AttackSeqBench: Benchmarking Large Language Models in Analyzing Attack Sequences within Cyber Threat Intelligence
作者: Haokai Ma, Javier Yong, Yunshan Ma, Kuei Chen, Anis Yusof, Zhenkai Liang, Ee-Chien Chang
分类: cs.CR, cs.AI
发布日期: 2025-03-05 (更新: 2025-10-05)
备注: 36 pages, 9 figures
💡 一句话要点
AttackSeqBench:评估大语言模型在网络威胁情报中分析攻击序列的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 网络威胁情报 大语言模型 攻击序列分析 基准测试 网络安全
📋 核心要点
- 网络威胁情报报告分析复杂,现有方法难以有效提取和分析攻击序列。
- 提出AttackSeqBench基准,系统评估LLM在理解和推理对抗行为序列方面的能力。
- 通过基准测试,揭示了不同LLM在CTI分析中的优势与不足,为应用提供指导。
📝 摘要(中文)
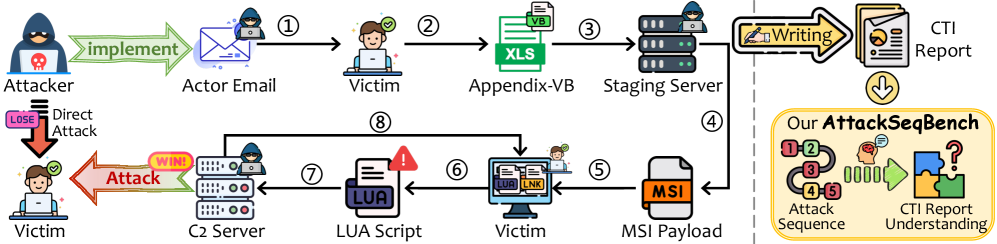
网络威胁情报(CTI)报告记录了对网络威胁的观察,将关于攻击者行为和意图的证据综合成可操作的知识,为检测、响应和防御规划提供信息。然而,CTI报告的非结构化和冗长特性给安全从业人员手动提取和分析这些序列带来了重大挑战。尽管大型语言模型(LLM)在实体提取和知识图构建等网络安全任务中展现出潜力,但它们对行为序列的理解和推理能力仍未得到充分探索。为了解决这个问题,我们引入了AttackSeqBench,这是一个旨在系统地评估LLM在对抗行为的战术、技术和程序维度上的推理能力的基准,同时满足可扩展性、推理可伸缩性和特定领域的认知可扩展性。我们进一步在AttackSeqBench中提出的3个基准设置和3个基准任务中,对7个LLM、5个LRM和4个后训练策略进行了基准测试,以识别它们在此特定领域的优势和局限性。我们的发现有助于更深入地理解LLM驱动的CTI报告理解,并促进其在网络安全运营中的应用。
🔬 方法详解
问题定义:该论文旨在解决网络安全从业人员在处理大量非结构化的网络威胁情报(CTI)报告时,难以有效提取和分析攻击序列的问题。现有的手动分析方法耗时且容易出错,而现有的大语言模型(LLM)在CTI领域,特别是对行为序列的理解和推理能力尚未得到充分评估。
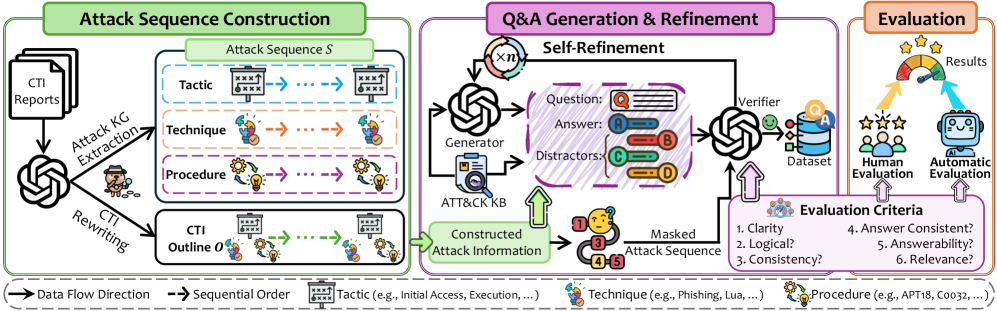
核心思路:论文的核心思路是构建一个专门用于评估LLM在分析攻击序列方面的能力的基准测试集AttackSeqBench。通过设计不同的任务和设置,系统地考察LLM在战术、技术和程序三个维度上理解和推理对抗行为的能力。
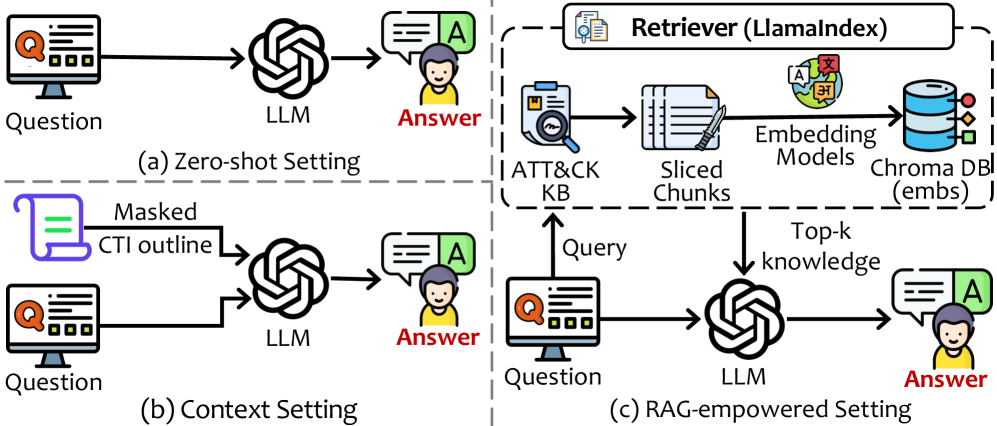
技术框架:AttackSeqBench基准测试框架包含三个主要组成部分:1)数据集构建,包含不同类型的攻击序列和相应的标注;2)基准测试任务设计,涵盖实体识别、关系抽取、序列预测等任务;3)评估指标定义,用于衡量LLM在不同任务上的性能。此外,论文还对多个LLM、LRM和后训练策略进行了基准测试。
关键创新:该论文的关键创新在于提出了AttackSeqBench,这是一个专门针对LLM在网络威胁情报领域分析攻击序列能力的基准测试集。该基准测试集具有可扩展性、推理可伸缩性和领域特定认知可扩展性,能够全面评估LLM在不同维度上的推理能力。
关键设计:AttackSeqBench的关键设计包括:1)精心设计的攻击序列,涵盖不同的攻击类型和技术;2)多样化的基准测试任务,包括实体识别、关系抽取和序列预测;3)全面的评估指标,用于衡量LLM在不同任务上的性能。此外,论文还考虑了不同LLM的特点,并选择了合适的后训练策略进行优化。
🖼️ 关键图片
📊 实验亮点
论文对7个LLM、5个LRM和4个后训练策略在AttackSeqBench上进行了基准测试。实验结果表明,不同的LLM在不同的任务上表现出不同的优势和局限性。例如,某些LLM在实体识别任务上表现出色,而另一些LLM在关系抽取任务上更具优势。这些发现有助于指导安全从业人员选择合适的LLM来解决特定的CTI分析问题。
🎯 应用场景
该研究成果可应用于自动化网络威胁情报分析、安全事件响应、威胁狩猎等领域。通过利用LLM的强大推理能力,可以帮助安全分析师更快速、准确地理解和应对网络威胁,从而提高网络安全防御能力。未来,该研究可以进一步扩展到其他安全领域,例如漏洞分析和恶意代码检测。
📄 摘要(原文)
Cyber Threat Intelligence (CTI) reports document observations of cyber threats, synthesizing evidence about adversaries' actions and intent into actionable knowledge that informs detection, response, and defense planning. However, the unstructured and verbose nature of CTI reports poses significant challenges for security practitioners to manually extract and analyze such sequences. Although large language models (LLMs) exhibit promise in cybersecurity tasks such as entity extraction and knowledge graph construction, their understanding and reasoning capabilities towards behavioral sequences remains underexplored. To address this, we introduce AttackSeqBench, a benchmark designed to systematically evaluate LLMs' reasoning abilities across the tactical, technical, and procedural dimensions of adversarial behaviors, while satisfying Extensibility, Reasoning Scalability, and Domain-dpecific Epistemic Expandability. We further benchmark 7 LLMs, 5 LRMs and 4 post-training strategies across the proposed 3 benchmark settings and 3 benchmark tasks within our AttackSeqBench to identify their advantages and limitations in such specific domain. Our findings contribute to a deeper understanding of LLM-driven CTI report understanding and foster its application in cybersecurity operations.