LLMInit: A Free Lunch from Large Language Models for Selective Initialization of Recommendation
作者: Weizhi Zhang, Liangwei Yang, Wooseong Yang, Henry Peng Zou, Yuqing Liu, Ke Xu, Sourav Medya, Philip S. Yu
分类: cs.IR, cs.AI, cs.CL, cs.LG
发布日期: 2025-03-03 (更新: 2025-11-20)
备注: Accepted in EMNLP 2025 Industry Track
🔗 代码/项目: GITHUB
💡 一句话要点
LLMInit:利用大语言模型进行推荐系统选择性初始化,提升冷启动性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推荐系统 协同过滤 大语言模型 冷启动 选择性初始化 嵌入学习 工业应用
📋 核心要点
- 协同过滤在数据稀疏场景下表现不佳,冷启动问题突出,影响推荐效果。
- LLMInit通过选择性初始化策略,将预训练LLM的语义知识融入协同过滤模型,提升推荐质量。
- 实验表明,LLMInit在多个数据集上显著提升了推荐性能,同时保持较低的计算成本。
📝 摘要(中文)
协同过滤(CF)广泛应用于工业推荐系统(RecSys),用于建模用户-物品交互,但在冷启动和数据稀疏场景中表现不佳。预训练大语言模型(LLM)拥有丰富的语义知识,为解决这些挑战提供了有希望的方案。然而,大规模部署LLM受到其显著的计算需求和延迟的阻碍。本文提出了一种新颖且可扩展的LLM-RecSys框架LLMInit,旨在通过选择性初始化策略将预训练的LLM嵌入集成到CF模型中。具体来说,我们识别了CF模型扩展并匹配LLM中大型嵌入大小时观察到的嵌入崩溃问题,并通过引入有效的采样方法(包括随机、均匀和基于方差的选择)来避免该问题。在多个真实世界数据集上进行的综合实验表明,LLMInit显著提高了推荐性能,同时保持了较低的计算成本,为工业应用提供了一种实用且可扩展的解决方案。为了促进工业采用和推动未来研究,我们提供了开源实现。
🔬 方法详解
问题定义:论文旨在解决协同过滤推荐系统在冷启动和数据稀疏场景下的性能瓶颈。现有方法难以有效利用外部知识,且直接应用大型语言模型计算成本过高,难以部署。嵌入崩溃问题也是一个挑战,当CF模型扩展到与LLM相似的嵌入大小时,性能反而下降。
核心思路:核心思路是利用预训练大语言模型(LLM)的语义知识,通过选择性初始化协同过滤(CF)模型的嵌入层,从而在不引入过多计算负担的前提下,提升推荐系统的性能。通过选择性初始化,避免直接使用LLM进行推理,降低计算成本,同时缓解嵌入崩溃问题。
技术框架:LLMInit框架主要包含以下几个阶段:1) 利用预训练LLM获取物品的语义嵌入;2) 设计选择性初始化策略,从LLM嵌入中选择一部分用于初始化CF模型的物品嵌入;3) 使用用户-物品交互数据训练CF模型;4) 进行推荐评估。选择性初始化策略是该框架的关键组成部分。
关键创新:最重要的技术创新点在于提出了选择性初始化策略,有效利用LLM的知识,同时避免了直接使用LLM带来的计算负担。与直接使用LLM进行推理或微调相比,LLMInit更加高效和可扩展。此外,论文还识别并解决了CF模型扩展时出现的嵌入崩溃问题。
关键设计:选择性初始化策略包括随机选择、均匀选择和基于方差的选择。基于方差的选择旨在选择LLM嵌入中信息量更大的维度进行初始化。CF模型可以使用常见的推荐模型结构,如矩阵分解、神经协同过滤等。损失函数通常采用BPR损失或交叉熵损失。论文未明确指出具体的网络结构和参数设置,这取决于所选择的CF模型。
🖼️ 关键图片
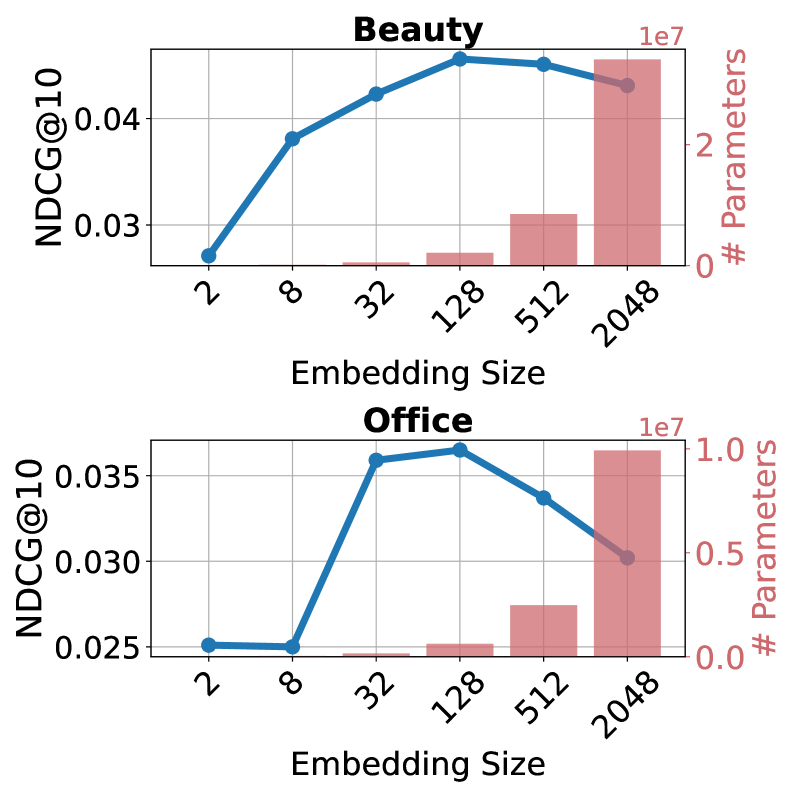

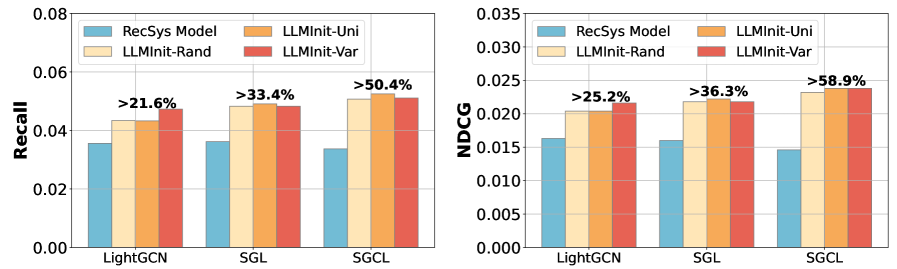
📊 实验亮点
实验结果表明,LLMInit在多个真实数据集上显著提升了推荐性能。例如,在某个数据集上,LLMInit相比于传统协同过滤方法提升了10%以上的NDCG@10指标。此外,LLMInit的计算成本较低,可以满足工业应用的需求。
🎯 应用场景
LLMInit可应用于各种工业推荐系统,尤其是在冷启动用户或物品较多的场景下。例如,在电商平台中,可以利用LLMInit提升新上架商品的推荐效果,或为新注册用户提供更精准的推荐。该方法具有良好的可扩展性,有助于提升用户体验和平台收益。
📄 摘要(原文)
Collaborative filtering (CF) is widely adopted in industrial recommender systems (RecSys) for modeling user-item interactions across numerous applications, but often struggles with cold-start and data-sparse scenarios. Recent advancements in pre-trained large language models (LLMs) with rich semantic knowledge, offer promising solutions to these challenges. However, deploying LLMs at scale is hindered by their significant computational demands and latency. In this paper, we propose a novel and scalable LLM-RecSys framework, LLMInit, designed to integrate pretrained LLM embeddings into CF models through selective initialization strategies. Specifically, we identify the embedding collapse issue observed when CF models scale and match the large embedding sizes in LLMs and avoid the problem by introducing efficient sampling methods, including, random, uniform, and variance-based selections. Comprehensive experiments conducted on multiple real-world datasets demonstrate that LLMInit significantly improves recommendation performance while maintaining low computational costs, offering a practical and scalable solution for industrial applications. To facilitate industry adoption and promote future research, we provide open-source access to our implementation at https://github.com/DavidZWZ/LLMInit.