LLM Strategic Reasoning: Agentic Study through Behavioral Game Theory
作者: Jingru Jia, Zehua Yuan, Junhao Pan, Paul E. McNamara, Deming Chen
分类: cs.AI, cs.CY, cs.GT, cs.LG
发布日期: 2025-02-27 (更新: 2025-11-01)
备注: Accepted by NeurIPS 2025
💡 一句话要点
提出基于行为博弈论的LLM战略推理评估框架,揭示模型决策机制与偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 战略推理 行为博弈论 模型评估 公平性 伦理偏见 链式思考 决策机制
📋 核心要点
- 现有LLM评估侧重纳什均衡近似,忽略了驱动战略选择的机制,无法有效评估LLM的战略推理能力。
- 论文提出基于行为博弈论的评估框架,解耦推理能力与上下文影响,更深入地分析LLM的战略决策过程。
- 实验结果表明,模型规模并非决定性能的唯一因素,CoT提示效果因模型而异,且模型存在固有偏见。
📝 摘要(中文)
本文提出了一种基于行为博弈论的评估框架,旨在深入研究大型语言模型(LLMs)的战略决策能力,区分推理能力与上下文效应。通过对22个先进LLM的测试,发现GPT-o3-mini、GPT-o1和DeepSeek-R1在多数博弈中表现突出,同时也表明模型规模并非决定性能的唯一因素。链式思考(CoT)提示并非普遍有效,仅在特定模型层级上提升战略推理能力。此外,研究还考察了编码人口统计特征对模型的影响,观察到某些特征分配会影响决策模式。例如,GPT-4o在具有女性特征时表现出更强的战略推理能力,而Gemma则为异性恋身份分配更高的推理水平,揭示了模型中固有的偏见。这些发现强调了在提升推理能力的同时,需要制定伦理标准和进行上下文对齐,以确保公平性。
🔬 方法详解
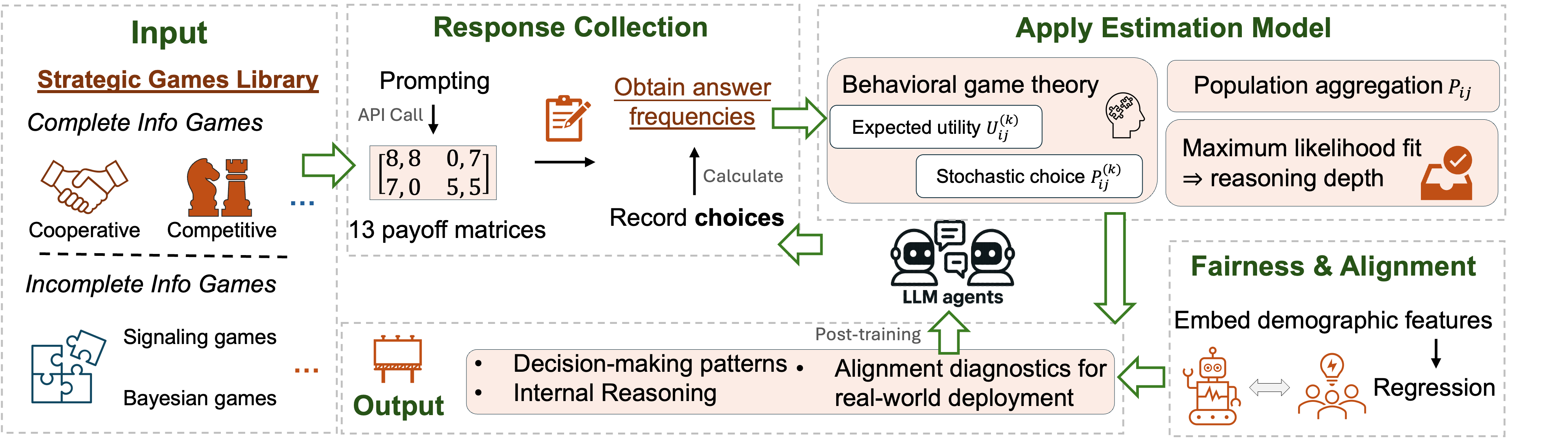
问题定义:现有的大型语言模型(LLMs)评估方法主要集中在纳什均衡(NE)的近似计算上,忽略了模型进行战略决策的内在机制。这种评估方式无法深入了解模型如何根据其他参与者的行为调整自身策略,以及上下文信息如何影响其决策过程。因此,需要一种更细粒度的评估框架,能够将模型的推理能力与上下文效应区分开来,从而更准确地评估其战略决策能力。
核心思路:本文的核心思路是利用行为博弈论的框架来评估LLMs的战略推理能力。行为博弈论关注的是参与者在博弈中的实际行为,而非仅仅是理论上的最优解。通过设计一系列博弈场景,并观察LLMs在这些场景中的决策行为,可以更深入地了解其推理过程和决策模式。此外,通过控制上下文信息,可以区分推理能力与上下文效应,从而更准确地评估模型的战略决策能力。
技术框架:该研究的评估框架主要包含以下几个阶段:1) 设计一系列博弈场景,这些场景需要能够考察LLMs的战略推理能力,例如囚徒困境、协调博弈等。2) 选择一系列LLMs作为评估对象,包括不同规模、不同架构的模型。3) 对每个LLM,在每个博弈场景中进行多次实验,记录其决策行为。4) 分析实验数据,评估LLMs的战略推理能力,并分析上下文信息对其决策的影响。5) 考察编码人口统计特征对模型决策的影响,揭示模型中可能存在的偏见。
关键创新:该研究的关键创新在于将行为博弈论引入到LLMs的评估中。与传统的基于纳什均衡的评估方法相比,行为博弈论能够更深入地了解模型的决策过程和决策模式。此外,该研究还考察了上下文信息和人口统计特征对模型决策的影响,揭示了模型中可能存在的偏见。
关键设计:在实验设计方面,研究人员精心设计了一系列博弈场景,以考察LLMs在不同情况下的战略推理能力。同时,研究人员还控制了上下文信息,例如参与者的身份、背景等,以区分推理能力与上下文效应。此外,研究人员还考察了不同类型的提示方法(例如,链式思考提示)对模型决策的影响。在数据分析方面,研究人员使用了多种统计方法来评估LLMs的战略推理能力,并分析上下文信息对其决策的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GPT-o3-mini、GPT-o1和DeepSeek-R1在多数博弈中表现突出,但模型规模并非决定性能的唯一因素。CoT提示并非普遍有效,仅在特定模型层级上提升战略推理能力。GPT-4o在具有女性特征时表现出更强的战略推理能力,而Gemma则为异性恋身份分配更高的推理水平,揭示了模型中固有的偏见。
🎯 应用场景
该研究成果可应用于开发更可靠、更公平的AI系统。通过评估LLM在战略决策中的偏见,可以指导模型训练,减少歧视性行为。此外,该框架可用于评估和改进AI在博弈论、谈判、自动化交易等领域的应用,提升AI系统的智能化水平和伦理水平。
📄 摘要(原文)
Strategic decision-making involves interactive reasoning where agents adapt their choices in response to others, yet existing evaluations of large language models (LLMs) often emphasize Nash Equilibrium (NE) approximation, overlooking the mechanisms driving their strategic choices. To bridge this gap, we introduce an evaluation framework grounded in behavioral game theory, disentangling reasoning capability from contextual effects. Testing 22 state-of-the-art LLMs, we find that GPT-o3-mini, GPT-o1, and DeepSeek-R1 dominate most games yet also demonstrate that the model scale alone does not determine performance. In terms of prompting enhancement, Chain-of-Thought (CoT) prompting is not universally effective, as it increases strategic reasoning only for models at certain levels while providing limited gains elsewhere. Additionally, we investigate the impact of encoded demographic features on the models, observing that certain assignments impact the decision-making pattern. For instance, GPT-4o shows stronger strategic reasoning with female traits than males, while Gemma assigns higher reasoning levels to heterosexual identities compared to other sexual orientations, indicating inherent biases. These findings underscore the need for ethical standards and contextual alignment to balance improved reasoning with fairness.