Meta-Reasoner: Dynamic Guidance for Optimized Inference-time Reasoning in Large Language Models
作者: Yuan Sui, Yufei He, Tri Cao, Simeng Han, Yulin Chen, Bryan Hooi
分类: cs.AI, cs.LG
发布日期: 2025-02-27 (更新: 2025-12-01)
💡 一句话要点
Meta-Reasoner:动态引导大语言模型优化推理时推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理优化 元推理 上下文多臂老虎机 动态策略调整
📋 核心要点
- LLM在多步推理中效率低、易出错,现有方法缺乏有效的回溯和策略调整机制。
- Meta-Reasoner通过上下文多臂老虎机学习自适应策略,动态调整推理策略,引导LLM“思考如何思考”。
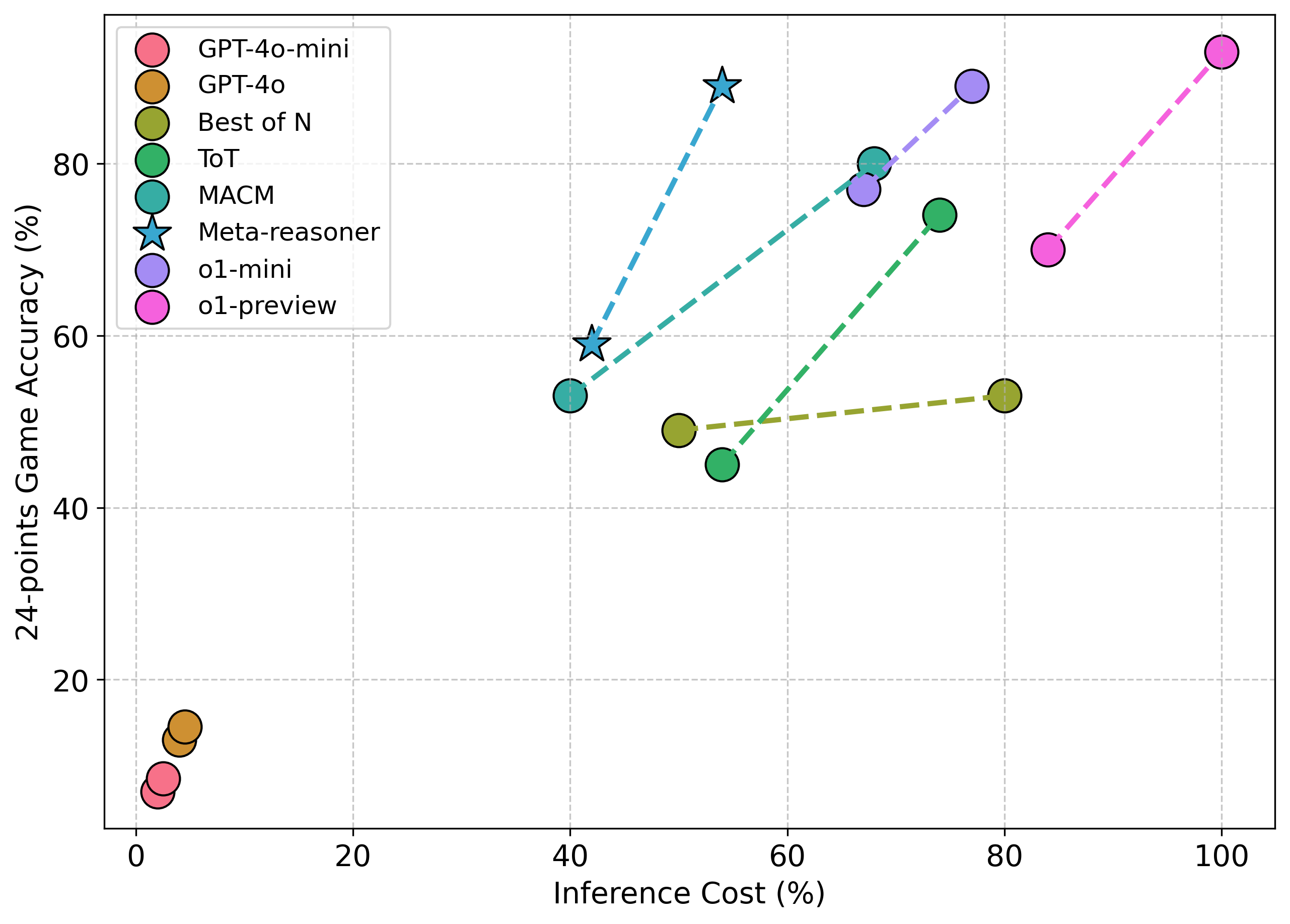
- 实验表明,Meta-Reasoner在数学和科学任务上,精度提升9-12%,推理时间减少28-35%。
📝 摘要(中文)
大型语言模型(LLMs)在多步推理任务中常常面临计算效率低下和误差传播的问题。尽管最近在提示工程和后训练方面的进展使LLMs能够执行逐步推理,但它们仍然倾向于探索无益的解决方案路径,缺乏有效的回溯或策略调整。本文提出了Meta-Reasoner,这是一个新的框架,使LLMs能够“思考如何思考”。它通过实时动态调整推理策略来优化推理过程。我们的方法采用上下文多臂老虎机(CMABs)来学习自适应策略,学习评估LLM推理的当前状态,并确定最有可能在推理过程中导致成功结果的最佳策略,例如是否回溯、切换到新方法或重新启动问题解决过程。这种元指导有助于避免在推理过程中探索无益的路径,从而提高计算效率。我们在数学问题(例如,Game-of-24、TheoremQA)和科学任务(例如,SciBench)上评估了Meta-Reasoner。结果表明,我们的方法在准确性方面优于之前的SOTA方法9-12%,同时在相同的计算预算下将推理时间减少了28-35%。在创意写作方面的额外实验证明了我们的方法对各种推理密集型任务的通用性。
🔬 方法详解
问题定义:大型语言模型在复杂推理任务中,常常因为探索无效路径而导致计算资源浪费和推理错误累积。现有的方法,如链式思考(Chain-of-Thought)等,虽然能引导LLM进行逐步推理,但缺乏动态调整策略的能力,无法根据推理过程中的状态进行有效的回溯或策略切换,导致效率低下。
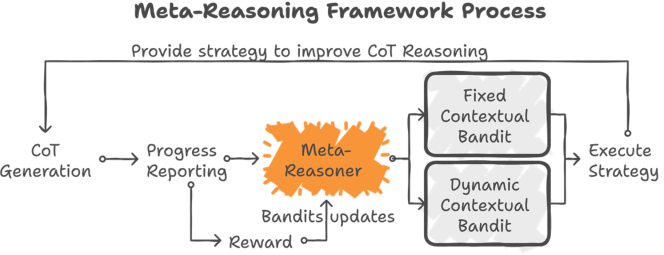
核心思路:Meta-Reasoner的核心思想是让LLM具备“元推理”能力,即“思考如何思考”。通过引入一个元控制器,该控制器能够根据LLM当前的推理状态,动态地选择最佳的推理策略(例如,继续当前路径、回溯、切换策略、重启等)。这种动态调整机制可以帮助LLM避免陷入无效的推理路径,从而提高推理效率和准确性。
技术框架:Meta-Reasoner的整体框架包含以下几个主要模块:1) LLM推理模块:负责执行实际的推理步骤,并输出中间结果。2) 状态评估模块:评估LLM当前的推理状态,例如,推理的进展、置信度等。3) 上下文多臂老虎机(CMAB)模块:根据状态评估模块的输出,选择最佳的推理策略。CMAB被训练成一个策略选择器,根据当前上下文(推理状态)选择动作(推理策略)。4) 策略执行模块:执行CMAB选择的推理策略,例如,回溯到之前的步骤、切换到新的推理方法等。
关键创新:Meta-Reasoner的关键创新在于引入了上下文多臂老虎机(CMAB)来动态地学习和调整推理策略。与传统的静态推理方法相比,Meta-Reasoner能够根据LLM的推理状态,实时地选择最佳的推理策略,从而避免了无效路径的探索,提高了推理效率和准确性。此外,将元推理的概念引入LLM,使其具备了“思考如何思考”的能力,这是一种新的研究方向。
关键设计:CMAB模块是Meta-Reasoner的关键。状态评估模块提取的推理状态作为CMAB的上下文信息。CMAB的动作空间包括多种推理策略,例如,继续当前路径、回溯到之前的步骤、切换到新的推理方法、重启等。CMAB的目标是最大化推理成功的概率,因此,奖励函数可以设置为推理成功时为正,失败时为负。CMAB的具体算法可以选择UCB、Thompson Sampling等。论文中可能还涉及一些超参数的调整,例如,CMAB的探索率、学习率等,这些参数会影响CMAB的学习效果和推理性能。
🖼️ 关键图片
📊 实验亮点
Meta-Reasoner在数学问题(Game-of-24, TheoremQA)和科学任务(SciBench)上进行了评估,结果表明,该方法在准确性方面优于之前的SOTA方法9-12%,同时在相同的计算预算下将推理时间减少了28-35%。这些结果表明,Meta-Reasoner能够有效地提高LLM的推理效率和准确性。
🎯 应用场景
Meta-Reasoner具有广泛的应用前景,可以应用于各种需要复杂推理的任务中,例如,数学问题求解、科学研究、软件开发、决策制定等。通过提高LLM的推理效率和准确性,Meta-Reasoner可以帮助人们更好地利用LLM解决实际问题,提高工作效率,并促进人工智能技术的发展。
📄 摘要(原文)
Large Language Models (LLMs) often struggle with computational efficiency and error propagation in multi-step reasoning tasks. While recent advancements on prompting and post-training have enabled LLMs to perform step-wise reasoning, they still tend to explore unproductive solution paths without effective backtracking or strategy adjustment. In this paper, we propose Meta-Reasoner, a new framework that empowers LLMs to "think about how to think". It optimizes the inference process by dynamically adapting reasoning strategies in real-time. Our approach employs contextual multi-armed bandits (CMABs) to learn an adaptive policy. It learns to evaluate the current state of LLM's reasoning and determine optimal strategy that is most likely to lead to a successful outcome during inference, like whether to backtrack, switch to a new approach, or restart the problem-solving process. This meta-guidance helps avoid unproductive paths exploration during inference and hence improves computational efficiency. We evaluate Meta-Reasoner on math problems (e.g., Game-of-24, TheoremQA) and scientific tasks (e.g., SciBench). Results show that our method outperform previous SOTA methods by 9-12\% in accuracy, while reducing inference time by 28-35\% under the same compute budget. Additional experiments on creative writing demonstrate the generalizability of our approach to diverse reasoning-intensive tasks.