SuPreME: A Supervised Pre-training Framework for Multimodal ECG Representation Learning
作者: Mingsheng Cai, Jiuming Jiang, Wenhao Huang, Che Liu, Rossella Arcucci
分类: eess.SP, cs.AI, cs.CL, cs.LG
发布日期: 2025-02-27 (更新: 2025-09-19)
备注: Findings of The 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP 2025)
💡 一句话要点
提出SuPreME框架,利用监督预训练提升多模态心电图表征学习,实现零样本分类。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心电图 多模态学习 自监督学习 预训练 大型语言模型 零样本学习 心血管疾病
📋 核心要点
- 现有ECG自监督学习方法难以捕捉细粒度临床语义,且下游任务微调成本高昂。
- SuPreME框架利用大型语言模型从ECG报告中提取结构化诊断标签,进行监督预训练。
- 实验结果表明,SuPreME在零样本分类任务中显著优于现有自监督学习方法。
📝 摘要(中文)
心血管疾病是全球死亡和残疾的主要原因。心电图(ECG)对于诊断和监测心脏健康至关重要,但获取大规模带标注的ECG数据集需要大量的人力和时间。最近的ECG自监督学习(eSSL)方法通过在没有大量标签的情况下学习特征来缓解这个问题,但未能捕获细粒度的临床语义,并且需要大量的特定任务微调。为了解决这些挑战,我们提出了SuPreME,一个用于多模态ECG表征学习的监督预训练框架。SuPreME使用结构化的诊断标签进行预训练,这些标签是通过大型语言模型(LLM)从ECG报告实体中一次性离线提取的,这有助于去噪、标准化心脏概念,并改善临床表征学习。通过将ECG信号与文本心脏查询而不是固定标签融合,SuPreME能够对未见过的疾病进行零样本分类,而无需进一步微调。我们在涵盖106种心脏疾病的六个下游数据集上评估了SuPreME,实现了77.20%的卓越零样本AUC性能,超过了最先进的eSSL方法4.98%。结果表明SuPreME在利用结构化的、临床相关的知识进行高质量ECG表征方面的有效性。
🔬 方法详解
问题定义:现有ECG自监督学习方法虽然避免了对大量标注数据的依赖,但在学习到的表征中,临床语义信息不足,导致下游任务需要大量的微调才能达到较好的效果。此外,这些方法难以泛化到未见过的疾病类型,缺乏零样本分类能力。
核心思路:SuPreME的核心思路是利用大型语言模型(LLM)从现有的ECG报告中提取结构化的诊断标签,并将这些标签作为监督信号来预训练ECG表征模型。通过这种方式,模型可以学习到更丰富的临床语义信息,从而提高其在下游任务中的性能,并具备零样本分类能力。
技术框架:SuPreME框架主要包含以下几个步骤:1) 使用LLM从ECG报告中提取结构化的诊断标签。2) 将ECG信号和对应的文本查询(即提取的诊断标签)输入到预训练模型中。3) 模型通过融合ECG信号和文本查询的信息,学习到高质量的ECG表征。4) 在下游任务中,可以直接使用预训练好的模型进行零样本分类,或者进行少量微调以进一步提高性能。
关键创新:SuPreME最重要的创新点在于利用LLM从ECG报告中提取结构化的诊断标签,并将这些标签作为监督信号来预训练ECG表征模型。这种方法不仅可以避免对大量标注数据的依赖,还可以使模型学习到更丰富的临床语义信息。与现有方法的本质区别在于,SuPreME使用文本查询作为监督信号,而不是固定的标签,从而实现了零样本分类能力。
关键设计:SuPreME的关键设计包括:1) 使用特定的大型语言模型(具体模型未在摘要中提及)进行实体抽取和关系抽取,以获得结构化的诊断标签。2) 设计合适的融合模块,将ECG信号和文本查询的信息进行融合。3) 选择合适的损失函数,以优化模型的训练过程。具体的网络结构和损失函数细节在摘要中未提及,属于未知信息。
🖼️ 关键图片
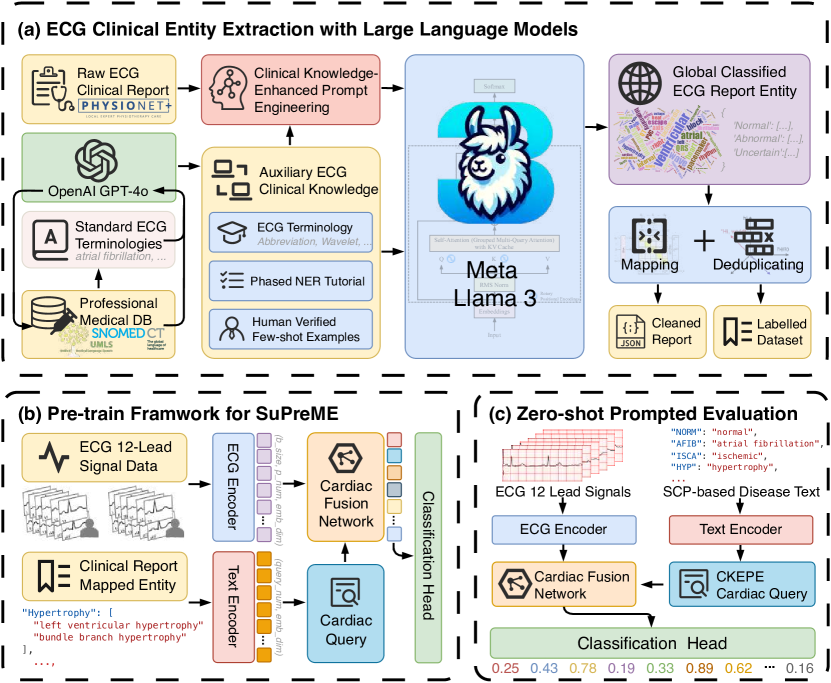

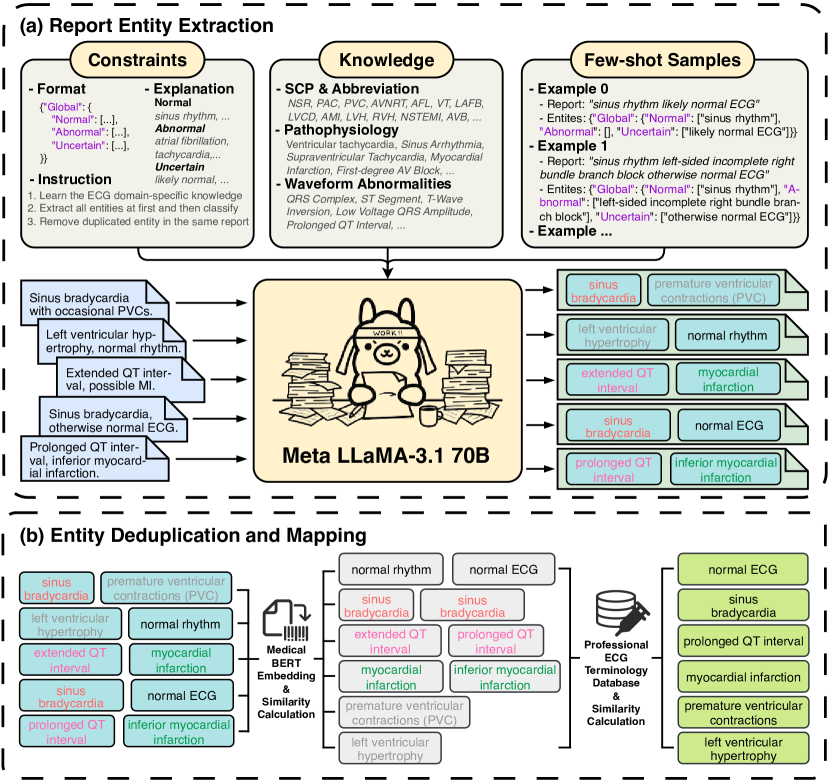
📊 实验亮点
SuPreME在六个下游数据集上进行了评估,涵盖106种心脏疾病。实验结果表明,SuPreME实现了77.20%的零样本AUC性能,超过了最先进的eSSL方法4.98%。这一结果表明,SuPreME能够有效地利用结构化的、临床相关的知识来学习高质量的ECG表征,并具备良好的泛化能力。
🎯 应用场景
SuPreME框架可应用于心血管疾病的自动诊断、风险预测和病情监测。该方法能够降低对大量标注数据的依赖,提高诊断效率和准确性,尤其是在缺乏专业医生或标注数据的情况下。未来,该技术有望集成到智能医疗设备和远程医疗平台中,实现更便捷、高效的心脏健康管理。
📄 摘要(原文)
Cardiovascular diseases are a leading cause of death and disability worldwide. Electrocardiogram (ECG) is critical for diagnosing and monitoring cardiac health, but obtaining large-scale annotated ECG datasets is labor-intensive and time-consuming. Recent ECG Self-Supervised Learning (eSSL) methods mitigate this by learning features without extensive labels but fail to capture fine-grained clinical semantics and require extensive task-specific fine-tuning. To address these challenges, we propose $\textbf{SuPreME}$, a $\textbf{Su}$pervised $\textbf{Pre}$-training framework for $\textbf{M}$ultimodal $\textbf{E}$CG representation learning. SuPreME is pre-trained using structured diagnostic labels derived from ECG report entities through a one-time offline extraction with Large Language Models (LLMs), which help denoise, standardize cardiac concepts, and improve clinical representation learning. By fusing ECG signals with textual cardiac queries instead of fixed labels, SuPreME enables zero-shot classification of unseen conditions without further fine-tuning. We evaluate SuPreME on six downstream datasets covering 106 cardiac conditions, achieving superior zero-shot AUC performance of $77.20\%$, surpassing state-of-the-art eSSLs by $4.98\%$. Results demonstrate SuPreME's effectiveness in leveraging structured, clinically relevant knowledge for high-quality ECG representations.