HALO: Hardware-aware quantization with low critical-path-delay weights for LLM acceleration
作者: Rohan Juneja, Shivam Aggarwal, Safeen Huda, Tulika Mitra, Li-Shiuan Peh
分类: cs.AR, cs.AI
发布日期: 2025-02-27 (更新: 2025-11-17)
💡 一句话要点
HALO:一种硬件感知的低关键路径延迟权重量化方法,用于加速LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 硬件感知量化 后训练量化 大型语言模型 推理加速 低功耗设计
📋 核心要点
- 传统量化方法忽略了硬件特性,无法充分利用时序裕量和节能机会,限制了LLM在现代加速器上的部署效率。
- HALO通过将硬件特性(如关键路径时序和功耗)显式纳入量化过程,策略性地选择低延迟权重,提升运行频率。
- 实验表明,HALO在TPU和GPU上实现了显著的性能提升(270%)和节能效果(51%),同时保持了较高的模型精度。
📝 摘要(中文)
量化对于高效部署大型语言模型(LLM)至关重要。然而,传统方法通常与硬件无关,仅限于位宽约束,并且没有考虑乘法累加(MAC)单元的固有电路特性,如时序行为和能量分布。这种与电路级行为的脱节限制了利用可用时序裕量和节能机会的能力,从而降低了在现代加速器上部署的整体效率。为了解决这些限制,我们提出了一种通用的硬件感知后训练量化(PTQ)框架HALO。与传统方法不同,HALO明确地将详细的硬件特性(包括关键路径时序和功耗)纳入其量化方法中。HALO策略性地选择具有低关键路径延迟的权重,从而实现更高的工作频率和动态频率缩放,而不会中断架构的数据流。值得注意的是,HALO仅通过少量动态电压和频率缩放(DVFS)调整即可实现这些改进,从而确保了部署的简单性和实用性。此外,通过减少MAC单元内的开关活动,HALO有效地降低了能耗。在张量处理单元(TPU)和图形处理单元(GPU)等加速器上的评估表明,HALO显著提高了推理效率,与基线量化方法相比,平均性能提高了270%,节能51%,且对精度的影响极小。
🔬 方法详解
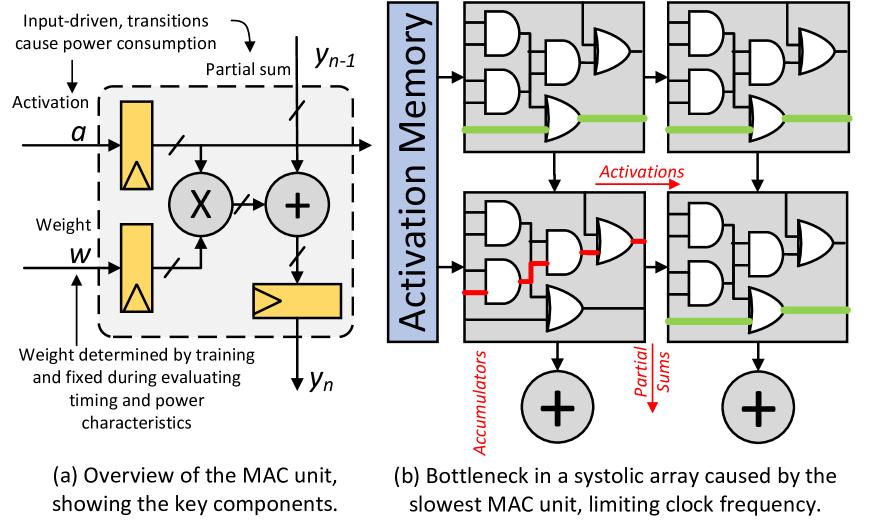
问题定义:现有的大型语言模型量化方法通常是硬件无关的,它们主要关注位宽的约束,而忽略了底层硬件电路的特性,例如乘法累加单元(MAC)的时序行为和功耗分布。这种忽略导致无法充分利用硬件的时序裕量和节能机会,从而限制了LLM在现代加速器上的部署效率。因此,需要一种硬件感知的量化方法,能够根据硬件的特性进行优化。
核心思路:HALO的核心思路是将硬件的特性(包括关键路径时序和功耗)显式地纳入到量化过程中。通过分析硬件的关键路径延迟,HALO策略性地选择具有低关键路径延迟的权重。这些权重可以支持更高的工作频率,并且允许在不影响数据流的情况下进行动态频率缩放。此外,HALO还通过减少MAC单元内部的开关活动来降低功耗。
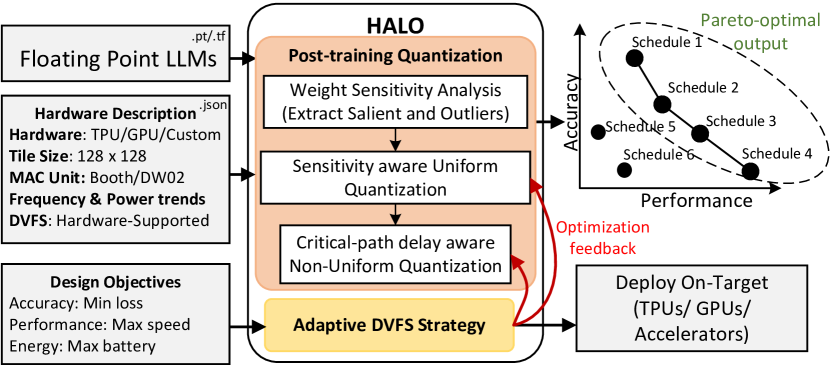
技术框架:HALO是一个硬件感知的后训练量化(PTQ)框架。其主要流程包括:1)分析目标硬件的特性,例如关键路径时序和功耗;2)根据硬件特性,对模型中的权重进行评估,选择具有低关键路径延迟的权重;3)对选择的权重进行量化,并进行动态电压和频率缩放(DVFS)调整;4)在目标硬件上部署量化后的模型,并进行性能和功耗评估。
关键创新:HALO的关键创新在于其硬件感知的量化方法。与传统的量化方法不同,HALO显式地考虑了硬件的特性,并根据这些特性来选择和量化权重。这种方法能够更好地利用硬件的时序裕量和节能机会,从而提高LLM的推理效率。另一个创新点是HALO仅需要少量的动态电压和频率缩放(DVFS)调整,这使得其部署更加简单和实用。
关键设计:HALO的关键设计包括:1)关键路径延迟的评估方法:HALO需要一种方法来准确评估硬件的关键路径延迟,这可能涉及到电路仿真或硬件测试;2)权重选择策略:HALO需要一种策略来选择具有低关键路径延迟的权重,这可能涉及到对权重进行排序或聚类;3)动态电压和频率缩放(DVFS)调整策略:HALO需要一种策略来确定最佳的电压和频率设置,以在性能和功耗之间取得平衡。
🖼️ 关键图片
📊 实验亮点
HALO在TPU和GPU等加速器上的实验结果表明,与基线量化方法相比,HALO平均性能提高了270%,节能51%,且对模型精度的影响极小。这些结果表明,HALO是一种有效的硬件感知量化方法,可以显著提高LLM的推理效率和降低功耗。
🎯 应用场景
HALO具有广泛的应用前景,可用于加速各种大型语言模型在不同硬件平台上的部署,包括云端服务器、边缘设备和移动设备。通过提高推理效率和降低功耗,HALO可以降低LLM的部署成本,并使其能够在资源受限的设备上运行。此外,HALO还可以应用于其他类型的深度学习模型,例如计算机视觉模型和语音识别模型。
📄 摘要(原文)
Quantization is critical for efficiently deploying large language models (LLMs). Yet conventional methods remain hardware-agnostic, limited to bit-width constraints, and do not account for intrinsic circuit characteristics such as the timing behaviors and energy profiles of Multiply-Accumulate (MAC) units. This disconnect from circuit-level behavior limits the ability to exploit available timing margins and energy-saving opportunities, reducing the overall efficiency of deployment on modern accelerators. To address these limitations, we propose HALO, a versatile framework for Hardware-Aware Post-Training Quantization (PTQ). Unlike traditional methods, HALO explicitly incorporates detailed hardware characteristics, including critical-path timing and power consumption, into its quantization approach. HALO strategically selects weights with low critical-path-delays enabling higher operational frequencies and dynamic frequency scaling without disrupting the architecture's dataflow. Remarkably, HALO achieves these improvements with only a few dynamic voltage and frequency scaling (DVFS) adjustments, ensuring simplicity and practicality in deployment. Additionally, by reducing switching activity within the MAC units, HALO effectively lowers energy consumption. Evaluations on accelerators such as Tensor Processing Units (TPUs) and Graphics Processing Units (GPUs) demonstrate that HALO significantly enhances inference efficiency, achieving average performance improvements of 270% and energy savings of 51% over baseline quantization methods, all with minimal impact on accuracy.