Combining Planning and Reinforcement Learning for Solving Relational Multiagent Domains
作者: Nikhilesh Prabhakar, Ranveer Singh, Harsha Kokel, Sriraam Natarajan, Prasad Tadepalli
分类: cs.MA, cs.AI, cs.LG
发布日期: 2025-02-26
💡 一句话要点
结合规划与强化学习,解决关系型多智能体领域问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 关系型学习 规划 强化学习 任务迁移
📋 核心要点
- 传统MARL方法在关系型多智能体领域面临状态空间爆炸和样本效率低下的问题,难以泛化到新任务。
- 该论文提出将关系型规划器与强化学习相结合,利用规划器进行集中控制和高效的状态抽象。
- 实验结果表明,该方法具有更高的样本效率,并能有效进行任务迁移和泛化。
📝 摘要(中文)
多智能体强化学习(MARL)由于状态和动作空间的指数增长以及多智能体环境的非平稳性而面临重大挑战。这导致显著的样本低效,并阻碍了跨不同任务的泛化。在关系型环境中,复杂性更加突出,领域知识至关重要,但现有MARL算法通常未能充分利用。为了克服这些障碍,我们提出将关系型规划器作为具有高效状态抽象和强化学习的集中式控制器进行集成。这种方法被证明是样本高效的,并有助于有效的任务迁移和泛化。
🔬 方法详解
问题定义:论文旨在解决关系型多智能体强化学习中样本效率低和泛化能力差的问题。现有MARL算法难以有效利用领域知识,导致在复杂关系型环境中学习效率低下,难以适应新的任务和环境。
核心思路:论文的核心思路是将关系型规划器作为集中式控制器,结合强化学习进行决策。规划器负责生成高层次的行动计划,强化学习负责学习如何在具体环境中执行这些计划。通过这种方式,可以利用规划器的领域知识和强化学习的自适应能力,提高样本效率和泛化能力。
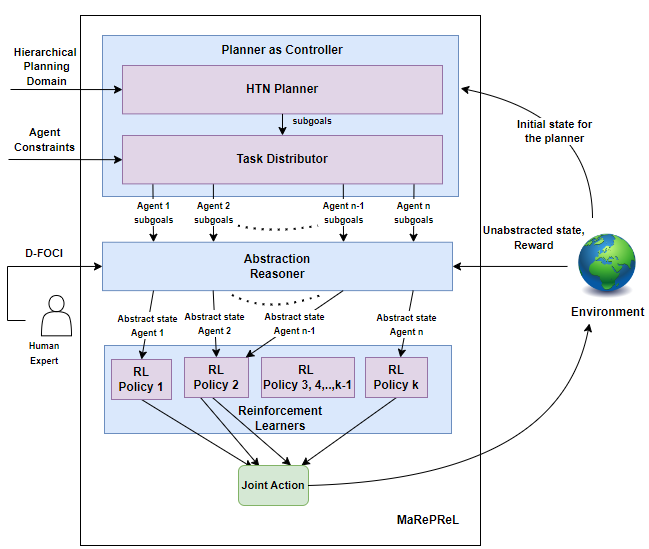
技术框架:整体框架包含两个主要模块:关系型规划器和强化学习智能体。关系型规划器负责根据当前状态生成行动计划,该计划被传递给强化学习智能体。强化学习智能体根据行动计划和环境反馈,学习如何执行计划并优化策略。整个过程是集中式训练和分布式执行的模式。
关键创新:该方法最重要的创新点在于将关系型规划器与强化学习相结合,充分利用了领域知识。传统的MARL方法通常是端到端学习,难以利用已有的领域知识。而该方法通过规划器提供高层次的指导,可以显著提高学习效率和泛化能力。
关键设计:论文中可能涉及的关键设计包括:规划器的具体实现方式(例如,使用STRIPS规划器),强化学习算法的选择(例如,DQN或Actor-Critic方法),以及如何将规划器的输出与强化学习智能体的输入进行有效结合。具体的损失函数和网络结构取决于所选择的强化学习算法。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了所提出方法的有效性。实验结果表明,该方法在关系型多智能体领域中具有更高的样本效率,并且能够实现有效的任务迁移和泛化。具体的性能数据和对比基线需要在论文中查找,但总体而言,该方法在性能上优于现有的MARL算法。
🎯 应用场景
该研究成果可应用于各种需要多智能体协作的复杂关系型领域,例如机器人协作、交通调度、资源分配和游戏AI等。通过结合规划和强化学习,可以提高智能体在复杂环境中的决策能力和协作效率,具有重要的实际应用价值和潜在的未来影响。
📄 摘要(原文)
Multiagent Reinforcement Learning (MARL) poses significant challenges due to the exponential growth of state and action spaces and the non-stationary nature of multiagent environments. This results in notable sample inefficiency and hinders generalization across diverse tasks. The complexity is further pronounced in relational settings, where domain knowledge is crucial but often underutilized by existing MARL algorithms. To overcome these hurdles, we propose integrating relational planners as centralized controllers with efficient state abstractions and reinforcement learning. This approach proves to be sample-efficient and facilitates effective task transfer and generalization.