SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution
作者: Yuxiang Wei, Olivier Duchenne, Jade Copet, Quentin Carbonneaux, Lingming Zhang, Daniel Fried, Gabriel Synnaeve, Rishabh Singh, Sida I. Wang
分类: cs.SE, cs.AI, cs.CL
发布日期: 2025-02-25 (更新: 2025-12-01)
备注: Accepted to NeurIPS 2025 Main Track
💡 一句话要点
SWE-RL:通过在开源软件演化上进行强化学习提升LLM推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 软件工程 代码生成 软件演化 推理能力 开源软件 自动化代码修复
📋 核心要点
- 现有LLM在软件工程领域的推理能力不足,难以有效利用软件演化数据进行学习和问题解决。
- SWE-RL利用强化学习,通过开源软件演化数据训练LLM,使其自主学习开发者的推理过程和解决方案。
- Llama3-SWE-RL-70B在SWE-bench Verified上达到41.0%的解决率,并在多个领域外任务上表现出提升。
📝 摘要(中文)
DeepSeek-R1的发布展示了强化学习(RL)在增强大型语言模型(LLM)通用推理能力方面的巨大潜力。本文介绍了SWE-RL,这是第一个将基于RL的LLM推理扩展到实际软件工程的方法。SWE-RL利用轻量级的基于规则的奖励(例如,ground-truth和LLM生成的解决方案之间的相似性得分),使LLM能够通过学习广泛的开源软件演化数据(包括代码快照、代码更改以及问题和pull request等事件的软件完整生命周期记录)来自主恢复开发人员的推理过程和解决方案。基于Llama 3训练的推理模型Llama3-SWE-RL-70B在SWE-bench Verified(一个经过人工验证的真实GitHub问题集合)上实现了41.0%的解决率。据我们所知,这是迄今为止中等规模(<100B)LLM的最佳性能,甚至可以与GPT-4o等领先的专有LLM相媲美。令人惊讶的是,尽管仅在软件演化数据上执行RL,但Llama3-SWE-RL甚至涌现出广义的推理技能。例如,它在五个领域外的任务(即函数编码、库使用、代码推理、数学和通用语言理解)上显示出改进的结果,而监督微调基线甚至导致平均性能下降。总的来说,SWE-RL开辟了一个新的方向,通过在海量软件工程数据上进行强化学习来提高LLM的推理能力。
🔬 方法详解
问题定义:论文旨在解决LLM在软件工程领域推理能力不足的问题。现有方法难以有效利用软件演化数据,例如代码快照、代码变更和问题报告等,来提升LLM的软件开发能力。现有方法要么依赖于大量标注数据进行监督学习,要么难以泛化到真实世界的软件工程问题。
核心思路:论文的核心思路是利用强化学习,让LLM通过与软件演化环境的交互,自主学习开发者的推理过程和解决方案。通过定义合适的奖励函数,引导LLM生成更符合ground-truth的解决方案,从而提升其在软件工程任务上的表现。这种方法避免了对大量标注数据的依赖,并有望提升LLM的泛化能力。
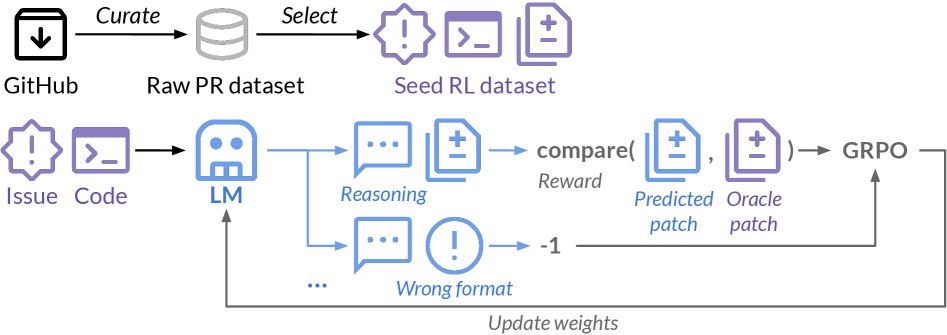
技术框架:SWE-RL的整体框架包括以下几个主要模块:1) LLM作为智能体,负责生成代码或解决方案;2) 软件演化环境,提供代码快照、变更历史等信息;3) 奖励函数,根据LLM生成的解决方案与ground-truth之间的相似度进行评分;4) 强化学习算法,用于更新LLM的策略,使其能够生成更高质量的解决方案。整个流程是一个迭代过程,LLM不断与环境交互,并通过强化学习算法进行优化。
关键创新:SWE-RL最重要的技术创新点在于将强化学习应用于软件演化数据,以提升LLM的推理能力。与传统的监督学习方法相比,SWE-RL能够更好地利用未标注的软件演化数据,并学习到更鲁棒的推理策略。此外,SWE-RL还设计了一种轻量级的基于规则的奖励函数,避免了人工标注的成本,并能够有效地引导LLM的学习。
关键设计:奖励函数的设计是SWE-RL的关键。论文采用基于规则的奖励函数,例如计算LLM生成的解决方案与ground-truth之间的相似度得分。具体而言,可以使用代码相似度指标,如BLEU或CodeBLEU,来衡量生成的代码与参考代码之间的相似程度。此外,还可以考虑代码的正确性,例如通过执行测试用例来验证生成的代码是否能够通过所有测试。强化学习算法可以选择常见的策略梯度算法,如PPO或Actor-Critic。
🖼️ 关键图片


📊 实验亮点
Llama3-SWE-RL-70B在SWE-bench Verified上实现了41.0%的解决率,显著优于其他中等规模的LLM。令人惊讶的是,该模型在五个领域外的任务上也表现出改进,表明通过在软件演化数据上进行强化学习,可以提升LLM的通用推理能力。相比之下,监督微调基线甚至导致平均性能下降。
🎯 应用场景
SWE-RL具有广泛的应用前景,可用于自动化代码修复、代码生成、软件漏洞检测等领域。通过提升LLM在软件工程领域的推理能力,可以显著提高软件开发的效率和质量,降低开发成本。此外,SWE-RL还可以应用于教育领域,帮助初学者学习编程和软件开发。
📄 摘要(原文)
The recent DeepSeek-R1 release has demonstrated the immense potential of reinforcement learning (RL) in enhancing the general reasoning capabilities of large language models (LLMs). While DeepSeek-R1 and other follow-up work primarily focus on applying RL to competitive coding and math problems, this paper introduces SWE-RL, the first approach to scale RL-based LLM reasoning for real-world software engineering. Leveraging a lightweight rule-based reward (e.g., the similarity score between ground-truth and LLM-generated solutions), SWE-RL enables LLMs to autonomously recover a developer's reasoning processes and solutions by learning from extensive open-source software evolution data -- the record of a software's entire lifecycle, including its code snapshots, code changes, and events such as issues and pull requests. Trained on top of Llama 3, our resulting reasoning model, Llama3-SWE-RL-70B, achieves a 41.0% solve rate on SWE-bench Verified -- a human-verified collection of real-world GitHub issues. To our knowledge, this is the best performance reported for medium-sized (<100B) LLMs to date, even comparable to leading proprietary LLMs like GPT-4o. Surprisingly, despite performing RL solely on software evolution data, Llama3-SWE-RL has even emerged with generalized reasoning skills. For example, it shows improved results on five out-of-domain tasks, namely, function coding, library use, code reasoning, mathematics, and general language understanding, whereas a supervised-finetuning baseline even leads to performance degradation on average. Overall, SWE-RL opens up a new direction to improve the reasoning capabilities of LLMs through reinforcement learning on massive software engineering data.