Science Across Languages: Assessing LLM Multilingual Translation of Scientific Papers
作者: Hannah Calzi Kleidermacher, James Zou
分类: cs.AI, cs.CL
发布日期: 2025-02-25 (更新: 2025-09-04)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
利用LLM实现科研论文多语种翻译,解决非英语母语研究者阅读障碍
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器翻译 大型语言模型 科学论文 JATS XML 问答基准测试
📋 核心要点
- 现有学术期刊主要以英文发表,对非英语母语的研究人员构成阅读障碍,阻碍了全球科研交流。
- 论文提出利用LLM自动翻译科研论文,并保留JATS XML格式,方便学术期刊直接采用。
- 实验结果表明,翻译准确率高达95.9%,用户研究也验证了翻译质量,但部分作者认为存在过度翻译问题。
📝 摘要(中文)
本研究利用大型语言模型(LLM)翻译已发表的科学文章,同时保留其原生的JATS XML格式,从而开发了一种可供学术期刊实施的实用、自动化方法。我们使用该方法将多个科学学科的文章翻译成28种语言。为了评估翻译的准确性,我们引入了一种新颖的问答(QA)基准测试方法,其中LLM从原始文本生成基于理解的问题,然后根据翻译后的文本回答这些问题。我们的基准测试结果显示平均性能为95.9%,表明关键的科学细节得到了准确传达。在一项用户研究中,我们将15位研究人员的科学论文翻译成他们的母语,发现作者一致认为翻译准确地捕捉了他们文章中的原始信息。有趣的是,三分之一的作者发现许多技术术语被“过度翻译”,表示更倾向于保留英语中更熟悉的技术术语不进行翻译。最后,我们展示了如何使用上下文学习技术来使翻译与领域特定的偏好保持一致,例如减轻过度翻译,突出了LLM驱动的科学翻译的适应性和实用性。代码和翻译后的文章可在https://hankleid.github.io/ProjectMundo获得。
🔬 方法详解
问题定义:当前科学研究全球化程度日益提高,但学术论文主要以英文发表,这给非英语母语的研究人员带来了巨大的阅读障碍。现有的翻译方法可能无法很好地保留科学论文的专业术语和格式,影响阅读体验和理解。
核心思路:本研究的核心思路是利用大型语言模型(LLM)强大的翻译能力,结合JATS XML格式保留技术,实现科研论文的自动化、高质量翻译。通过问答基准测试和用户研究,评估和优化翻译质量,并解决过度翻译等问题。
技术框架:该方法主要包含以下几个阶段:1) 获取已发表的科学文章,并提取其JATS XML格式;2) 利用LLM将文章内容翻译成目标语言;3) 保留原有的JATS XML格式,生成翻译后的文章;4) 使用问答基准测试评估翻译质量;5) 通过用户研究收集反馈,并利用上下文学习优化翻译效果。
关键创新:该研究的关键创新在于:1) 提出了一种基于LLM的科研论文自动化翻译方法,并保留了JATS XML格式;2) 引入了一种新颖的问答基准测试方法,用于评估翻译质量;3) 通过用户研究发现并解决了过度翻译等问题,并提出了基于上下文学习的优化方案。
关键设计:在翻译过程中,使用了大型语言模型,具体模型信息未知。问答基准测试中,LLM既作为问题生成器,又作为答案回答者。用户研究中,邀请了15位研究人员评估翻译质量,并收集了他们的反馈。通过上下文学习,可以调整LLM的翻译策略,例如控制技术术语的翻译程度,以满足用户的个性化需求。具体上下文学习的prompt设计未知。
🖼️ 关键图片


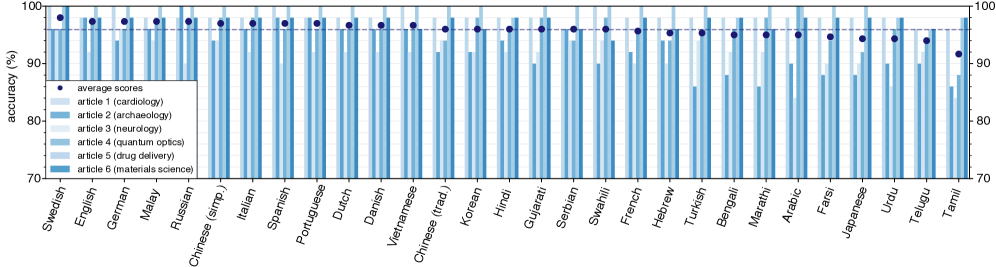
📊 实验亮点
该研究通过问答基准测试评估翻译质量,结果显示平均性能高达95.9%,表明关键的科学细节得到了准确传达。用户研究也表明,作者普遍认为翻译准确地捕捉了文章的原始信息。此外,研究还发现并解决了过度翻译的问题,并提出了基于上下文学习的优化方案,进一步提升了翻译质量。
🎯 应用场景
该研究成果可应用于学术期刊的论文翻译,促进科研成果的国际传播,帮助非英语母语的研究人员更好地获取和理解最新的科研进展。此外,该方法还可以应用于其他专业领域的文档翻译,提高信息获取的效率和便利性。未来,可以进一步优化翻译质量,并开发更多个性化的翻译服务。
📄 摘要(原文)
Scientific research is inherently global. However, the vast majority of academic journals are published exclusively in English, creating barriers for non-native-English-speaking researchers. In this study, we leverage large language models (LLMs) to translate published scientific articles while preserving their native JATS XML formatting, thereby developing a practical, automated approach for implementation by academic journals. Using our approach, we translate articles across multiple scientific disciplines into 28 languages. To evaluate translation accuracy, we introduce a novel question-and-answer (QA) benchmarking method, in which an LLM generates comprehension-based questions from the original text and then answers them based on the translated text. Our benchmark results show an average performance of 95.9%, showing that the key scientific details are accurately conveyed. In a user study, we translate the scientific papers of 15 researchers into their native languages, finding that the authors consistently found the translations to accurately capture the original information in their articles. Interestingly, a third of the authors found many technical terms "overtranslated," expressing a preference to keep terminology more familiar in English untranslated. Finally, we demonstrate how in-context learning techniques can be used to align translations with domain-specific preferences such as mitigating overtranslation, highlighting the adaptability and utility of LLM-driven scientific translation. The code and translated articles are available at https://hankleid.github.io/ProjectMundo.