Automated Query-Product Relevance Labeling using Large Language Models for E-commerce Search
作者: Jayant Sachdev, Sean D Rosario, Abhijeet Phatak, He Wen, Swati Kirti, Chittaranjan Tripathy
分类: cs.IR, cs.AI, cs.CL, cs.LG
发布日期: 2025-02-21
💡 一句话要点
利用大型语言模型自动标注电商搜索中的查询-商品相关性,降低标注成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 电商搜索 查询-商品相关性 提示工程 自动化标注
📋 核心要点
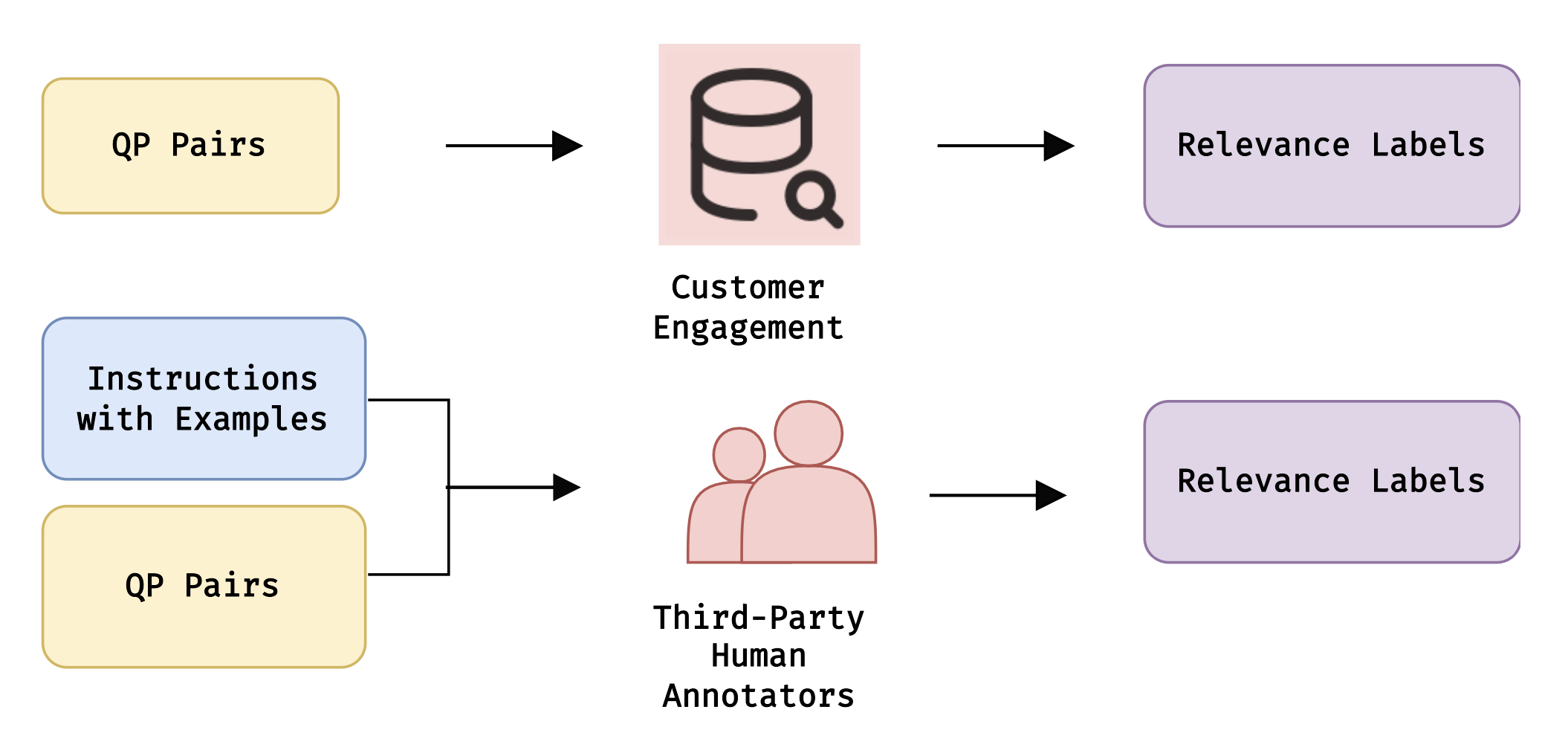
- 人工标注查询-商品相关性成本高、耗时且易出错,难以满足电商搜索排序模型训练的需求。
- 利用大型语言模型,结合提示工程技术,自动化生成查询-商品相关性标签,降低标注成本。
- 实验表明,该方法在准确率上接近人工标注,且大幅降低了时间和成本,具有实际应用价值。
📝 摘要(中文)
准确的查询-商品相关性标注对于生成电商搜索排序的真值数据集至关重要。传统的标注方法依赖于人工标注服务,成本高昂、耗时且容易出错。本文探索了使用大型语言模型(LLM)来自动化大规模电商搜索中的查询-商品相关性标注。我们使用了多个公开的和专有的LLM进行实验,并在两个开源数据集和一个内部电商搜索数据集上进行了验证。通过提示工程技术,如思维链(CoT)提示、上下文学习(ICL)以及使用最大边缘相关性(MMR)的检索增强生成(RAG),我们表明LLM的性能有潜力接近人工标注的准确率,且所需的时间和成本仅为人工标注的一小部分,表明我们的方法比传统方法更有效。我们已经使用LLM大规模生成了查询-商品相关性标签,并将其用于评估搜索算法的改进。我们的工作展示了LLM在提高查询-商品相关性方面的潜力,从而提升电商搜索用户体验。更重要的是,这种可扩展的替代人工标注的方法对于信息检索领域(包括搜索和推荐系统)具有重要意义,在这些领域中,相关性评分对于优化产品和内容的排序以提高客户参与度和转化率至关重要。
🔬 方法详解
问题定义:论文旨在解决电商搜索中查询-商品相关性标注的问题。现有方法依赖人工标注,存在成本高昂、耗时、主观性强且难以规模化等痛点。这些痛点限制了搜索排序模型的训练和迭代效率。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大语义理解和生成能力,通过提示工程(Prompt Engineering)引导LLM自动判断查询和商品之间的相关性。通过精心设计的提示,使LLM能够模拟人工标注的过程,从而生成高质量的标注数据。
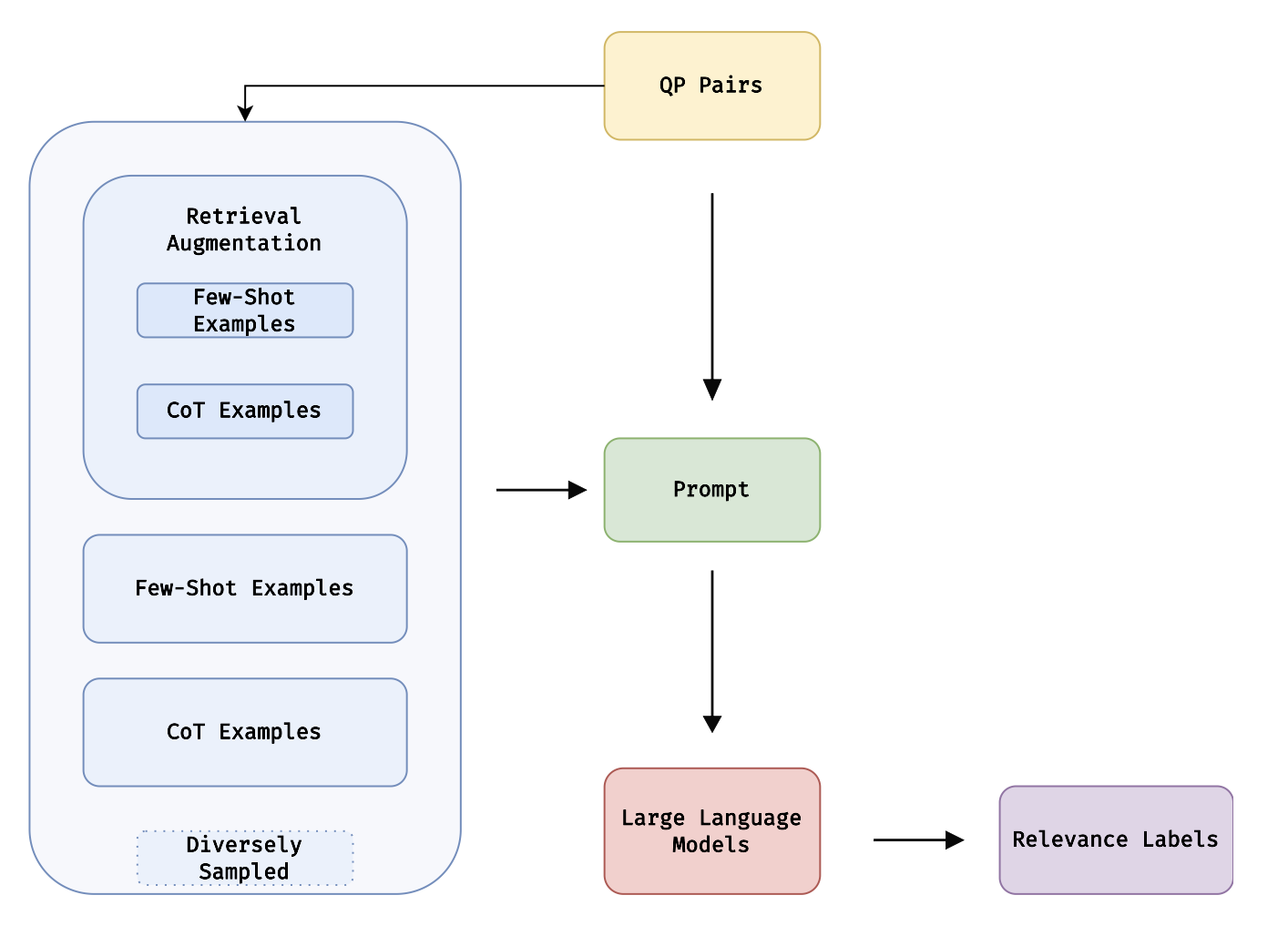
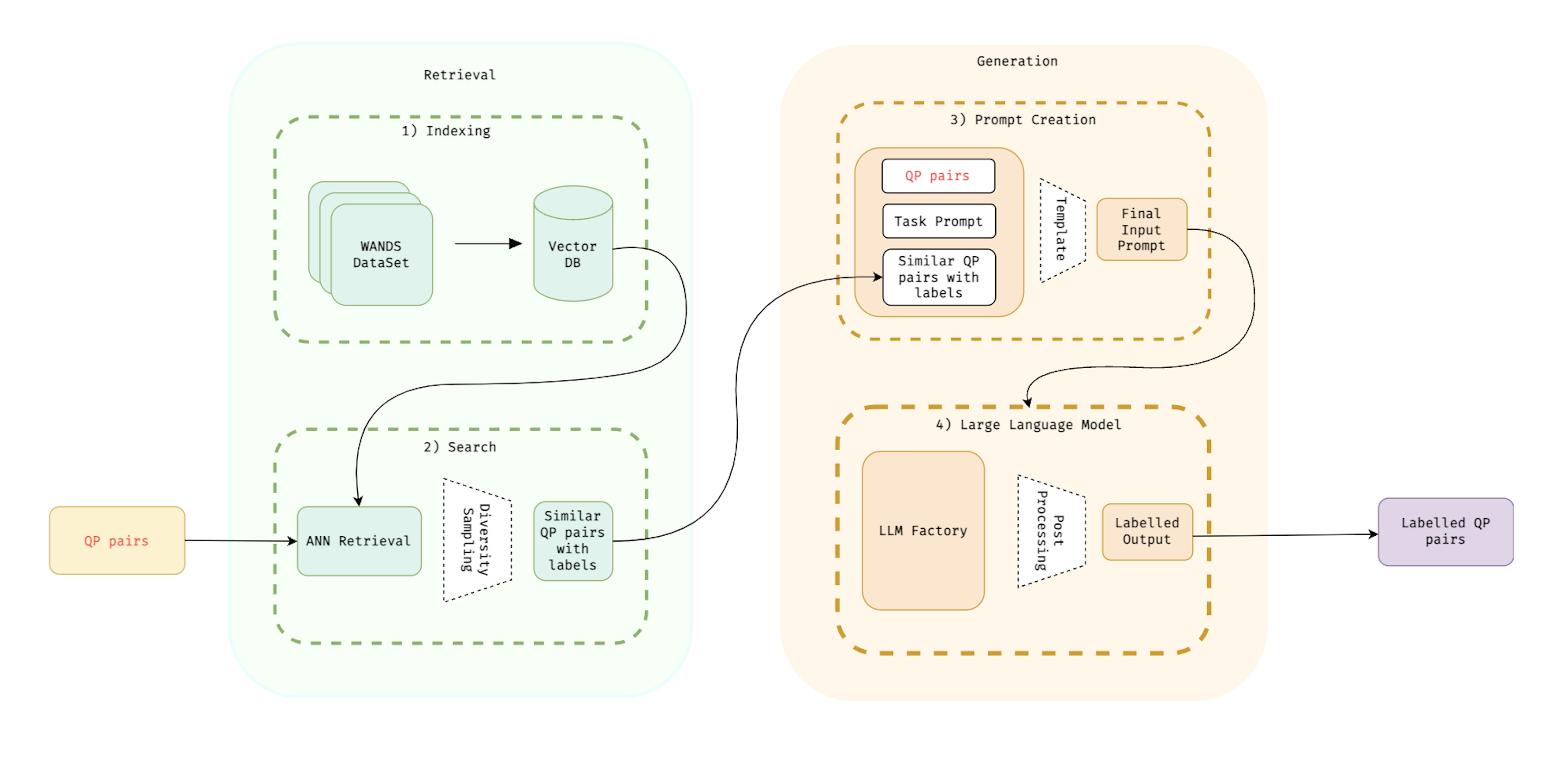
技术框架:整体流程包括以下几个主要阶段:1) 数据准备:构建包含查询和商品信息的数据集。2) 提示工程:设计合适的提示模板,包括思维链(CoT)提示、上下文学习(ICL)和检索增强生成(RAG)。3) LLM推理:将查询和商品信息以及提示输入LLM,获得相关性判断结果。4) 结果评估:将LLM的标注结果与人工标注或其他基线方法进行比较,评估性能。其中,RAG模块使用最大边缘相关性(MMR)来选择检索到的相关文档,以提高生成结果的多样性和准确性。
关键创新:论文的关键创新在于将LLM应用于查询-商品相关性标注任务,并结合多种提示工程技术,实现了自动化、低成本且高质量的标注。与传统的人工标注相比,该方法具有更高的效率和可扩展性。此外,结合RAG和MMR进一步提升了LLM生成标签的质量。
关键设计:提示工程是关键。例如,CoT提示通过引导LLM逐步推理,提高判断的准确性。ICL通过提供少量示例,使LLM能够更好地理解任务要求。RAG结合MMR,从外部知识库中检索相关信息,辅助LLM进行判断。具体的参数设置和模型选择取决于具体的LLM和数据集,需要进行实验调优。
🖼️ 关键图片
📊 实验亮点
论文在多个数据集上进行了实验,包括开源数据集和内部电商搜索数据集。实验结果表明,通过提示工程,LLM的性能可以接近人工标注的准确率,且所需的时间和成本远低于人工标注。这表明该方法具有很高的效率和实用性,能够显著降低标注成本,加速模型迭代。
🎯 应用场景
该研究成果可广泛应用于电商搜索、推荐系统等领域,用于生成大规模的训练数据,提升排序模型的性能,从而改善用户体验,提高点击率、转化率等关键业务指标。此外,该方法也可推广到其他信息检索领域,例如新闻推荐、知识问答等,具有重要的应用价值和潜力。
📄 摘要(原文)
Accurate query-product relevance labeling is indispensable to generate ground truth dataset for search ranking in e-commerce. Traditional approaches for annotating query-product pairs rely on human-based labeling services, which is expensive, time-consuming and prone to errors. In this work, we explore the application of Large Language Models (LLMs) to automate query-product relevance labeling for large-scale e-commerce search. We use several publicly available and proprietary LLMs for this task, and conducted experiments on two open-source datasets and an in-house e-commerce search dataset. Using prompt engineering techniques such as Chain-of-Thought (CoT) prompting, In-context Learning (ICL), and Retrieval Augmented Generation (RAG) with Maximum Marginal Relevance (MMR), we show that LLM's performance has the potential to approach human-level accuracy on this task in a fraction of the time and cost required by human-labelers, thereby suggesting that our approach is more efficient than the conventional methods. We have generated query-product relevance labels using LLMs at scale, and are using them for evaluating improvements to our search algorithms. Our work demonstrates the potential of LLMs to improve query-product relevance thus enhancing e-commerce search user experience. More importantly, this scalable alternative to human-annotation has significant implications for information retrieval domains including search and recommendation systems, where relevance scoring is crucial for optimizing the ranking of products and content to improve customer engagement and other conversion metrics.