LEDD: Large Language Model-Empowered Data Discovery in Data Lakes
作者: Qi An, Chihua Ying, Yuqing Zhu, Yihao Xu, Manwei Zhang, Jianmin Wang
分类: cs.DB, cs.AI
发布日期: 2025-02-21
💡 一句话要点
LEDD:利用大语言模型实现数据湖中的数据发现与语义搜索
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据湖 数据发现 大型语言模型 语义搜索 全局目录
📋 核心要点
- 数据湖中数据发现面临语义理解和全局目录构建的挑战,现有方法难以有效利用LLM进行端到端处理。
- LEDD系统利用LLM进行语义表搜索和分层全局目录生成,通过自然语言规范实现语义相关的表检索。
- LEDD提供Python接口,方便算法扩展和替换,为下游任务如模型训练和模式链接提供基础。
📝 摘要(中文)
数据湖中日益增长的数据集给数据发现带来了巨大挑战,尤其是在表格的语义搜索和分层全局目录生成方面。虽然大型语言模型(LLM)有助于处理数据语义,但构建一个端到端系统来全面利用LLM完成这两项语义相关任务仍然存在挑战。本文演示了LEDD,一个具有可扩展架构的端到端系统,它利用LLM为数据湖提供具有语义意义的分层全局目录和语义表搜索。具体来说,LEDD可以根据自然语言规范返回语义相关的表。这些特性使LEDD成为下游任务(如模型训练和text-to-SQL任务的模式链接)的理想基础。LEDD还提供了一个简单的Python接口,以方便数据发现算法的扩展和替换。
🔬 方法详解
问题定义:数据湖中的数据发现,特别是表格的语义搜索和分层全局目录生成,面临着巨大的挑战。现有方法难以充分利用大型语言模型(LLM)的语义理解能力,构建一个端到端的系统来有效地完成这些任务。痛点在于如何将LLM集成到数据发现流程中,以实现更准确、更高效的语义搜索和目录生成。
核心思路:LEDD的核心思路是利用LLM的强大语义理解能力,构建一个端到端的系统,该系统能够根据自然语言规范返回语义相关的表,并生成具有语义意义的分层全局目录。通过将LLM集成到数据发现流程中,LEDD能够更准确地理解用户的查询意图,并提供更相关的搜索结果。
技术框架:LEDD是一个端到端系统,其架构具有可扩展性。它主要包含以下模块:数据摄取模块(负责从数据湖中提取数据)、语义分析模块(利用LLM对数据进行语义分析)、目录生成模块(生成分层全局目录)和搜索模块(根据自然语言规范进行语义表搜索)。用户可以通过Python接口与LEDD进行交互,方便算法的扩展和替换。
关键创新:LEDD的关键创新在于它将LLM集成到数据发现流程中,并构建了一个端到端的系统,能够根据自然语言规范返回语义相关的表,并生成具有语义意义的分层全局目录。与现有方法相比,LEDD能够更准确地理解用户的查询意图,并提供更相关的搜索结果。
关键设计:LEDD的关键设计包括:使用LLM进行语义分析,例如使用预训练的语言模型对表格的元数据进行编码,并使用余弦相似度来衡量表格之间的语义相似度;构建分层全局目录,例如使用聚类算法将语义相似的表格组织在一起,并生成分层目录结构;提供Python接口,方便算法的扩展和替换。
🖼️ 关键图片
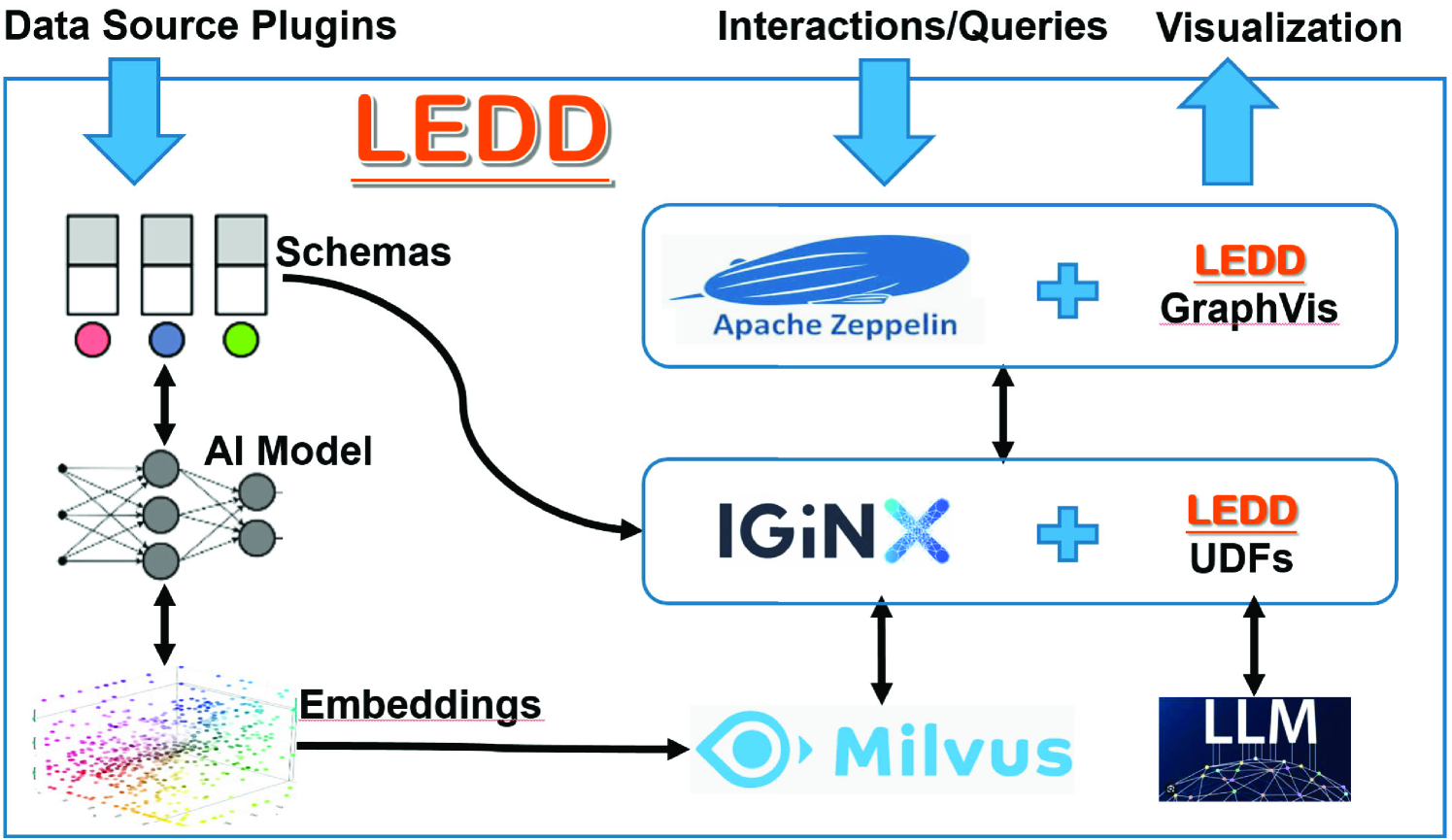


📊 实验亮点
LEDD系统能够根据自然语言规范返回语义相关的表,为数据湖提供具有语义意义的分层全局目录和语义表搜索功能。通过演示,验证了LEDD在数据发现和语义搜索方面的有效性,为下游任务(如模型训练和text-to-SQL任务的模式链接)提供了理想的基础。
🎯 应用场景
LEDD可应用于各种需要数据发现和语义搜索的场景,例如企业数据管理、科学研究和知识图谱构建。它可以帮助用户快速找到所需的数据,提高数据利用率,并为下游任务(如模型训练和text-to-SQL任务的模式链接)提供基础。未来,LEDD可以扩展到支持更多的数据源和数据类型,并提供更高级的语义分析功能。
📄 摘要(原文)
Data discovery in data lakes with ever increasing datasets has long been recognized as a big challenge in the realm of data management, especially for semantic search of and hierarchical global catalog generation of tables. While large language models (LLMs) facilitate the processing of data semantics, challenges remain in architecting an end-to-end system that comprehensively exploits LLMs for the two semantics-related tasks. In this demo, we propose LEDD, an end-to-end system with an extensible architecture that leverages LLMs to provide hierarchical global catalogs with semantic meanings and semantic table search for data lakes. Specifically, LEDD can return semantically related tables based on natural-language specification. These features make LEDD an ideal foundation for downstream tasks such as model training and schema linking for text-to-SQL tasks. LEDD also provides a simple Python interface to facilitate the extension and the replacement of data discovery algorithms.