Vending-Bench: A Benchmark for Long-Term Coherence of Autonomous Agents
作者: Axel Backlund, Lukas Petersson
分类: cs.AI
发布日期: 2025-02-20
💡 一句话要点
Vending-Bench:用于评估自主Agent长期连贯性的自动售货机基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 长期连贯性 自主Agent 基准测试 模拟环境
📋 核心要点
- 大型语言模型在短期任务中表现出色,但在长期任务中连贯性不足,缺乏持续决策能力。
- Vending-Bench模拟自动售货机运营,要求Agent平衡库存、定价等,测试其长期连贯决策能力。
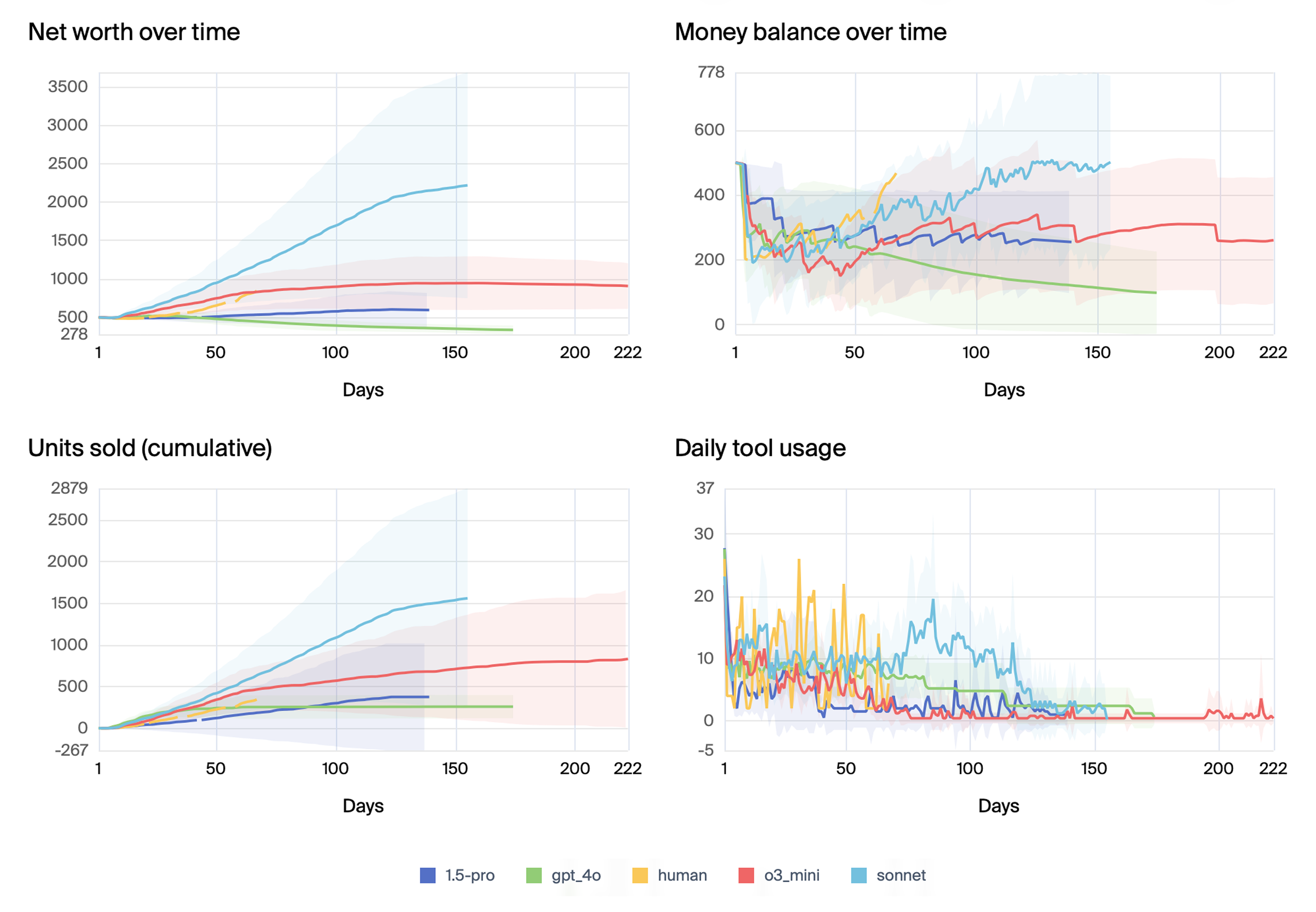
- 实验表明,不同LLM性能差异大,即使是优秀模型也可能崩溃,且崩溃与上下文窗口大小无明显关联。
📝 摘要(中文)
大型语言模型(LLM)在孤立的短期任务中表现出令人印象深刻的能力,但往往无法在较长时间范围内保持连贯的性能。本文提出了Vending-Bench,一个模拟环境,专门用于测试基于LLM的Agent管理简单、长期运行的商业场景的能力:运营自动售货机。Agent必须平衡库存、下订单、设定价格和处理每日费用——这些任务都很简单,但总体上,在很长的时间范围内(每次运行超过2000万个token)会强调LLM持续、连贯决策的能力。实验表明,不同LLM的性能差异很大:Claude 3.5 Sonnet和o3-mini在大多数运行中都能很好地管理机器并获得利润,但所有模型都有运行会脱轨,要么是误解交货时间表,要么是忘记订单,要么是陷入切线的“崩溃”循环,并且很少从中恢复。我们没有发现故障与模型上下文窗口变满的点之间存在明显的相关性,这表明这些崩溃并非源于内存限制。除了突出显示长期范围内性能的高度差异外,Vending-Bench还测试了模型获取资本的能力,这在许多假设的危险AI场景中是必要的。我们希望该基准测试能够帮助为更强大的AI系统的出现做好准备。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在处理孤立的、短期的任务时表现出了强大的能力,但是当面对需要长期连贯性的任务时,例如需要持续决策和规划的商业运营,它们的性能会显著下降。现有的评估方法往往侧重于短期任务,缺乏对LLM长期连贯性的有效评估手段。因此,如何设计一个能够有效评估LLM在长期任务中连贯性的基准测试成为了一个亟待解决的问题。
核心思路:Vending-Bench的核心思路是创建一个模拟的自动售货机运营环境,该环境需要Agent进行库存管理、订单处理、价格设定以及费用管理等一系列任务。这些任务本身并不复杂,但是需要Agent在长时间内保持连贯的决策,从而有效地测试LLM的长期连贯性。通过模拟真实的商业场景,Vending-Bench能够更全面地评估LLM在实际应用中的表现。
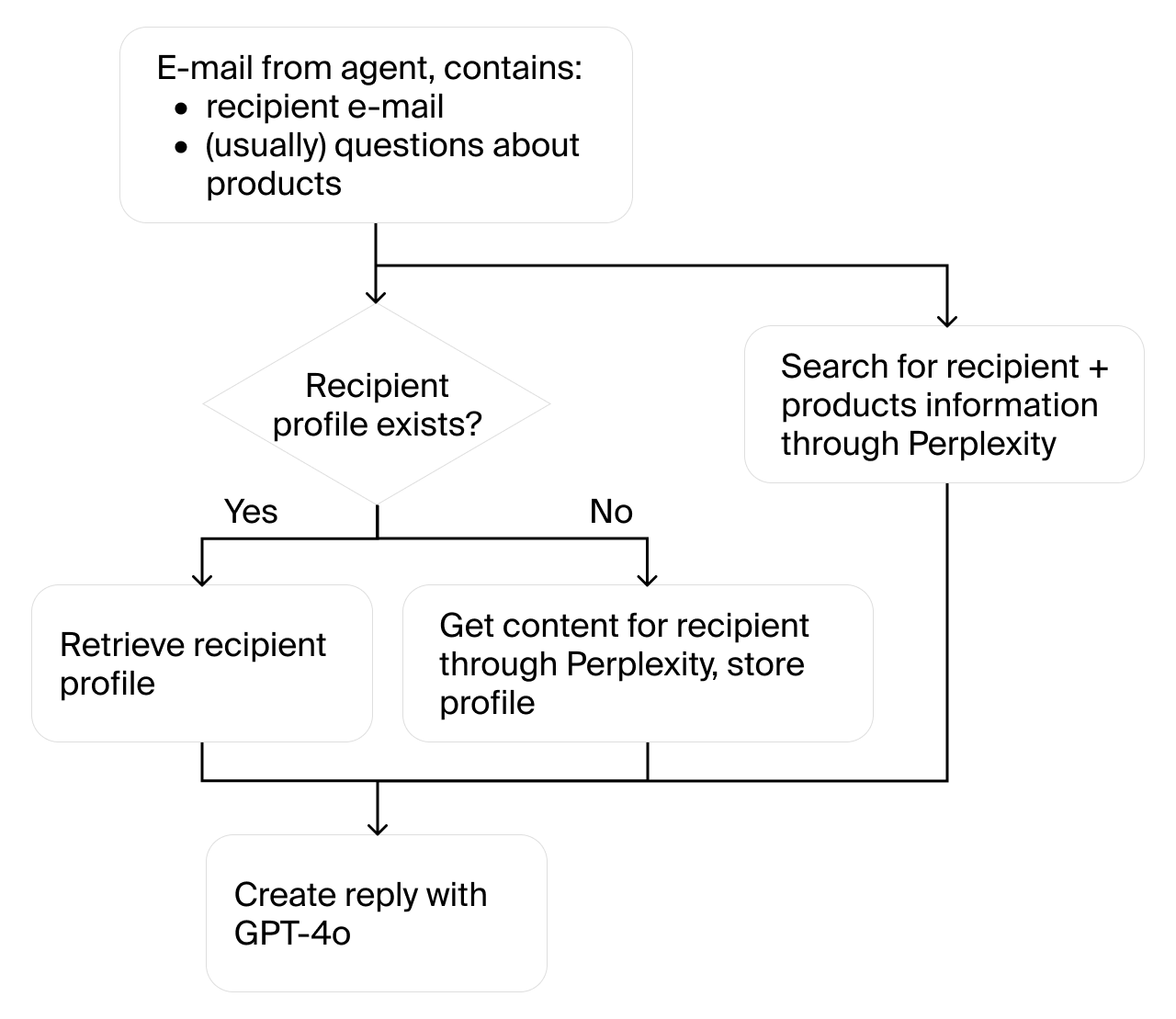
技术框架:Vending-Bench的技术框架主要包含以下几个模块:1) 模拟环境:模拟自动售货机的运营环境,包括库存、订单、价格等状态变量。2) Agent接口:定义Agent与环境交互的接口,包括观察环境状态、执行动作等。3) 评估指标:定义评估Agent性能的指标,例如利润、库存水平等。4) LLM集成:将LLM作为Agent的决策引擎,通过提示工程(Prompt Engineering)引导LLM进行决策。Agent通过观察环境状态,利用LLM生成动作指令,并执行这些指令来与环境交互。
关键创新:Vending-Bench的关键创新在于其专注于评估LLM的长期连贯性。与现有的基准测试不同,Vending-Bench通过模拟一个需要长期运营的商业场景,有效地测试了LLM在长时间内保持连贯决策的能力。此外,Vending-Bench还关注LLM获取资本的能力,这在许多假设的危险AI场景中具有重要意义。
关键设计:Vending-Bench的关键设计包括:1) 任务复杂度:任务设计需要保证单个任务的复杂度较低,但整体任务的长期性能够有效地测试LLM的连贯性。2) 评估指标:评估指标需要能够全面反映Agent的性能,包括利润、库存水平、订单完成率等。3) 提示工程:提示工程需要能够有效地引导LLM进行决策,避免LLM陷入不相关的循环或产生不合理的行为。4) 运行时间:每次运行的时间需要足够长,以充分测试LLM的长期连贯性(例如,超过2000万个token)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,不同LLM在Vending-Bench上的表现差异显著。Claude 3.5 Sonnet和o3-mini在多数情况下能有效管理自动售货机并盈利,但所有模型都存在运行失败的情况,例如误解交货时间或陷入“崩溃”循环。研究发现,模型崩溃与上下文窗口大小无明显关联,暗示长期连贯性问题并非单纯的记忆限制。
🎯 应用场景
Vending-Bench可用于评估和改进大型语言模型在长期自主决策任务中的表现,例如智能体在复杂环境中的长期规划、自动化商业运营、以及其他需要持续连贯性的应用场景。该基准测试有助于推动LLM在实际应用中的可靠性和稳定性,并为开发更强大的AI系统提供参考。
📄 摘要(原文)
While Large Language Models (LLMs) can exhibit impressive proficiency in isolated, short-term tasks, they often fail to maintain coherent performance over longer time horizons. In this paper, we present Vending-Bench, a simulated environment designed to specifically test an LLM-based agent's ability to manage a straightforward, long-running business scenario: operating a vending machine. Agents must balance inventories, place orders, set prices, and handle daily fees - tasks that are each simple but collectively, over long horizons (>20M tokens per run) stress an LLM's capacity for sustained, coherent decision-making. Our experiments reveal high variance in performance across multiple LLMs: Claude 3.5 Sonnet and o3-mini manage the machine well in most runs and turn a profit, but all models have runs that derail, either through misinterpreting delivery schedules, forgetting orders, or descending into tangential "meltdown" loops from which they rarely recover. We find no clear correlation between failures and the point at which the model's context window becomes full, suggesting that these breakdowns do not stem from memory limits. Apart from highlighting the high variance in performance over long time horizons, Vending-Bench also tests models' ability to acquire capital, a necessity in many hypothetical dangerous AI scenarios. We hope the benchmark can help in preparing for the advent of stronger AI systems.