Cooperative Multi-Agent Planning with Adaptive Skill Synthesis
作者: Zhiyuan Li, Wenshuai Zhao, Joni Pajarinen
分类: cs.AI, cs.MA
发布日期: 2025-02-14 (更新: 2025-05-06)
💡 一句话要点
COMPASS:基于自适应技能合成的合作式多智能体规划框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体强化学习 视觉语言模型 技能合成 合作式规划 结构化通信
📋 核心要点
- 传统MARL方法样本效率低、可解释性差,且难以迁移,而LLM虽有潜力,但难以处理部分可观测下的多智能体交互。
- COMPASS通过集成VLM、动态技能库和结构化通信,实现了分散式闭环决策,提升了多智能体协作能力。
- 在SMACv2上的实验表明,COMPASS在对称和非对称场景中均优于现有MARL方法,胜率显著提升。
📝 摘要(中文)
尽管分布式人工智能(AI)训练取得了很大进展,但使用多智能体强化学习(MARL)构建合作式多智能体系统在样本效率、可解释性和可迁移性方面面临挑战。与需要与环境进行大量交互的传统学习方法不同,大型语言模型(LLM)在零样本规划和复杂推理方面表现出卓越的能力。然而,现有的基于LLM的方法严重依赖于基于文本的观察,并且难以应对部分可观察性下多智能体交互的非马尔可夫性质。我们提出COMPASS,一种新颖的多智能体架构,它集成了视觉-语言模型(VLM)与动态技能库和结构化通信,用于分散式闭环决策。技能库从演示中引导,并通过规划器引导的任务进行演变,以实现自适应策略。COMPASS在部分可观察性下通过多跳通信传播实体信息。在改进的星际争霸多智能体挑战(SMACv2)上的评估表明,COMPASS在对称和非对称场景中都表现出优于最先进的MARL基线的强大性能。值得注意的是,在对称的Protoss 5v5任务中,COMPASS实现了57%的胜率,比QMIX(27%)高出30个百分点。
🔬 方法详解
问题定义:论文旨在解决多智能体强化学习中样本效率低、可解释性差、迁移性弱的问题,尤其是在部分可观测环境下,传统方法难以有效利用信息进行协作规划。现有方法要么需要大量环境交互,要么难以处理非马尔可夫性质的多智能体交互。
核心思路:论文的核心思路是结合视觉-语言模型(VLM)的强大推理能力和动态技能库的灵活性,通过结构化通信在智能体之间传递信息,从而实现高效、可解释、可迁移的多智能体协作。这种方法旨在弥合LLM在复杂推理方面的优势与MARL在环境交互方面的优势。
技术框架:COMPASS的整体架构包含以下几个主要模块:1) 视觉-语言模型(VLM):用于处理视觉输入并提取语义信息。2) 动态技能库:存储预定义的技能,并根据任务需求进行自适应选择和组合。3) 规划器:根据VLM的输出和技能库中的技能,生成任务执行计划。4) 结构化通信模块:用于在智能体之间传递信息,解决部分可观测性问题。整个流程是分散式的,每个智能体独立进行决策,并通过通信进行协调。
关键创新:COMPASS的关键创新在于将VLM与动态技能库相结合,并引入结构化通信机制。与传统的端到端MARL方法不同,COMPASS利用VLM的先验知识进行规划,并通过技能库实现策略的自适应调整。结构化通信则解决了部分可观测性下的信息传递问题,使得智能体能够更好地理解全局状态。
关键设计:技能库的初始化通过演示学习完成,并通过规划器引导的任务进行迭代更新。结构化通信采用多跳消息传递机制,允许智能体之间传递多轮信息。损失函数的设计旨在鼓励智能体选择合适的技能并进行有效的通信。具体的网络结构和参数设置在论文中进行了详细描述(未知)。
🖼️ 关键图片
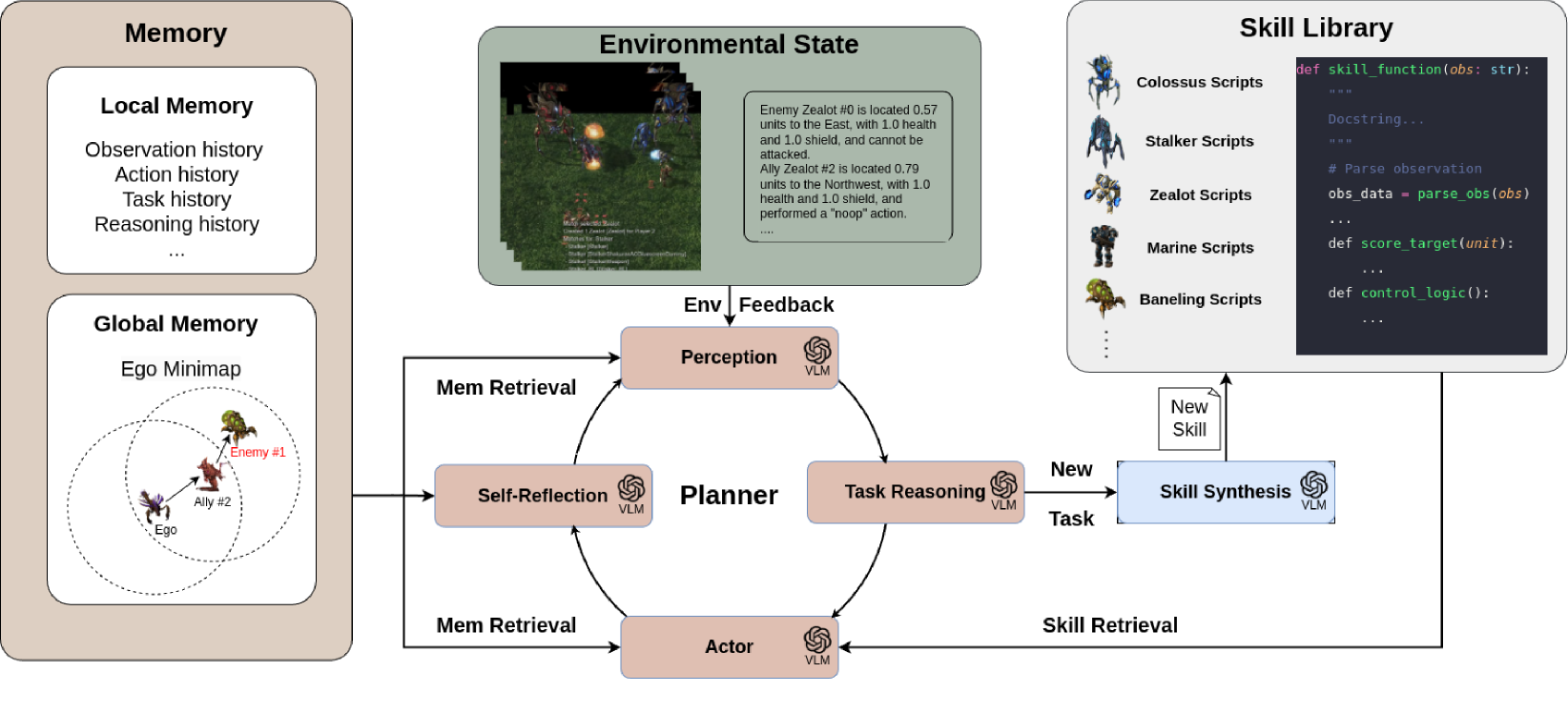

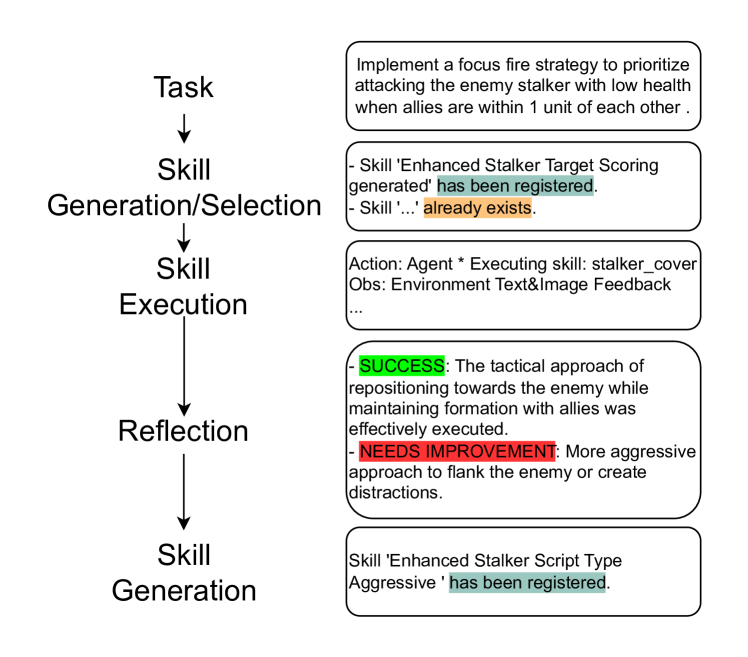
📊 实验亮点
COMPASS在SMACv2上取得了显著的性能提升。在对称的Protoss 5v5任务中,COMPASS的胜率达到了57%,比QMIX(27%)高出30个百分点。实验结果表明,COMPASS在对称和非对称场景中均优于现有的MARL基线,验证了其有效性和泛化能力。这些结果表明,COMPASS能够有效地利用VLM和动态技能库进行多智能体协作。
🎯 应用场景
COMPASS具有广泛的应用前景,例如在机器人协同操作、自动驾驶车队管理、智能交通调度、以及资源分配等领域。该研究的实际价值在于提升多智能体系统的协作效率和鲁棒性,使其能够在复杂和不确定的环境中更好地完成任务。未来,COMPASS有望推动多智能体技术在更多实际场景中的应用。
📄 摘要(原文)
Despite much progress in training distributed artificial intelligence (AI), building cooperative multi-agent systems with multi-agent reinforcement learning (MARL) faces challenges in sample efficiency, interpretability, and transferability. Unlike traditional learning-based methods that require extensive interaction with the environment, large language models (LLMs) demonstrate remarkable capabilities in zero-shot planning and complex reasoning. However, existing LLM-based approaches heavily rely on text-based observations and struggle with the non-Markovian nature of multi-agent interactions under partial observability. We present COMPASS, a novel multi-agent architecture that integrates vision-language models (VLMs) with a dynamic skill library and structured communication for decentralized closed-loop decision-making. The skill library, bootstrapped from demonstrations, evolves via planner-guided tasks to enable adaptive strategies. COMPASS propagates entity information through multi-hop communication under partial observability. Evaluations on the improved StarCraft Multi-Agent Challenge (SMACv2) demonstrate COMPASS's strong performance against state-of-the-art MARL baselines across both symmetric and asymmetric scenarios. Notably, in the symmetric Protoss 5v5 task, COMPASS achieved a 57\% win rate, representing a 30 percentage point advantage over QMIX (27\%). Project page can be found at https://stellar-entremet-1720bb.netlify.app/.