Unlocking Efficient Vehicle Dynamics Modeling via Analytic World Models
作者: Asen Nachkov, Danda Pani Paudel, Jan-Nico Zaech, Davide Scaramuzza, Luc Van Gool
分类: cs.AI, cs.RO
发布日期: 2025-02-14 (更新: 2025-11-13)
备注: Accepted at AAAI 2026
💡 一句话要点
提出基于可微世界模型的车辆动力学高效建模方法,用于自动驾驶等场景。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 可微模拟 世界模型 车辆动力学 自动驾驶 解析策略梯度
📋 核心要点
- 现有方法难以高效地进行车辆动力学建模,限制了自动驾驶等领域的应用。
- 论文提出解析世界模型(AWM),结合可微动力学和状态预测器,实现端到端学习。
- 实验表明,AWM能够有效学习相对里程计、最优规划器和最优逆状态,提升决策能力。
📝 摘要(中文)
本文提出了一种利用可微模拟器进行车辆动力学建模的方法,该方法将环境动力学表示为一个可微函数。在机器人和自动驾驶领域,这种特性被用于解析策略梯度(APG),它依赖于通过动力学进行反向传播来训练各种任务的精确策略。本文表明,可微模拟在世界建模中也扮演着重要角色,它可以赋予智能体预测、规范和反事实能力。具体来说,我们设计了三种新的任务设置,其中可微动力学与端到端计算图相结合,但不是与策略相结合,而是与状态预测器相结合。这使得我们能够学习相对里程计、最优规划器和最优逆状态。我们将这些预测器统称为解析世界模型(AWM),并展示了可微模拟如何实现它们的有效端到端学习。在自动驾驶场景中,它们具有广泛的适用性,并且可以增强智能体在反应式控制之外的决策能力。
🔬 方法详解
问题定义:现有的车辆动力学建模方法,尤其是在自动驾驶领域,通常依赖于大量的数据驱动或者复杂的物理模型。数据驱动的方法需要大量的真实数据进行训练,泛化能力有限;而复杂的物理模型计算量大,难以进行实时优化和控制。因此,如何高效地进行车辆动力学建模,并将其应用于自动驾驶等场景是一个关键问题。
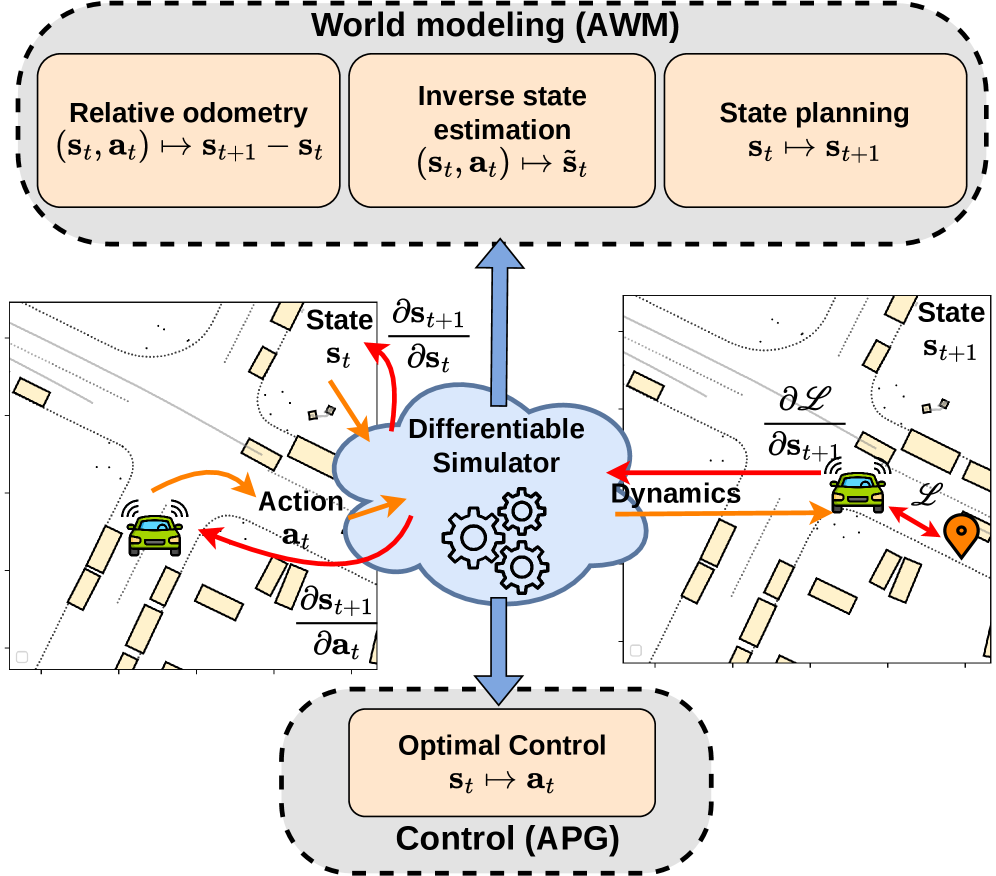
核心思路:本文的核心思路是利用可微模拟器,将环境动力学表示为一个可微函数。通过将可微动力学与状态预测器相结合,构建解析世界模型(AWM)。AWM可以通过端到端的方式进行训练,从而避免了传统方法中需要手动设计特征或者进行复杂优化的过程。这种方法能够高效地学习车辆动力学模型,并赋予智能体预测、规范和反事实能力。
技术框架:整体框架包含可微模拟器和状态预测器两个主要模块。可微模拟器负责模拟车辆的运动和环境的交互,并输出车辆的状态信息。状态预测器则根据当前状态和控制输入,预测未来的状态。整个框架通过端到端的方式进行训练,目标是最小化预测状态和真实状态之间的差异。具体流程是:首先,车辆在环境中执行动作,可微模拟器模拟车辆的运动,并输出下一时刻的状态。然后,状态预测器根据当前状态和动作,预测下一时刻的状态。最后,计算预测状态和真实状态之间的差异,并利用反向传播算法更新模型参数。
关键创新:本文最重要的技术创新点在于将可微模拟与世界模型相结合,提出了解析世界模型(AWM)。与传统的基于策略的学习方法不同,AWM直接学习状态预测器,从而避免了策略学习的复杂性。此外,AWM能够利用可微动力学进行反向传播,从而实现高效的端到端学习。
关键设计:在具体实现上,论文设计了三种不同的任务设置:相对里程计、最优规划器和最优逆状态。对于每种任务,论文都设计了相应的状态预测器和损失函数。例如,在相对里程计任务中,状态预测器预测车辆的相对位姿,损失函数则采用位姿误差。在最优规划器任务中,状态预测器预测最优的控制序列,损失函数则采用轨迹代价。网络结构方面,论文采用了常见的神经网络结构,如多层感知机(MLP)和循环神经网络(RNN)。
🖼️ 关键图片


📊 实验亮点
论文在三个任务上验证了AWM的有效性:相对里程计、最优规划器和最优逆状态。实验结果表明,AWM能够有效地学习车辆动力学模型,并在各种任务上取得良好的性能。例如,在相对里程计任务中,AWM能够准确地估计车辆的相对位姿,误差低于传统方法。在最优规划器任务中,AWM能够生成最优的控制序列,从而实现高效的轨迹规划。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、机器人导航、游戏AI等领域。在自动驾驶中,AWM可以用于车辆的运动规划、轨迹预测和控制。在机器人导航中,AWM可以用于机器人的路径规划和避障。在游戏AI中,AWM可以用于智能体的行为决策和环境交互。该研究具有重要的实际价值和广阔的应用前景,有望推动相关领域的发展。
📄 摘要(原文)
Differentiable simulators represent an environment's dynamics as a differentiable function. Within robotics and autonomous driving, this property is used in Analytic Policy Gradients (APG), which relies on backpropagating through the dynamics to train accurate policies for diverse tasks. Here we show that differentiable simulation also has an important role in world modeling, where it can impart predictive, prescriptive, and counterfactual capabilities to an agent. Specifically, we design three novel task setups in which the differentiable dynamics are combined within an end-to-end computation graph not with a policy, but a state predictor. This allows us to learn relative odometry, optimal planners, and optimal inverse states. We collectively call these predictors Analytic World Models (AWMs) and demonstrate how differentiable simulation enables their efficient, end-to-end learning. In autonomous driving scenarios, they have broad applicability and can augment an agent's decision-making beyond reactive control.