MIR-Bench: Can Your LLM Recognize Complicated Patterns via Many-Shot In-Context Reasoning?
作者: Kai Yan, Zhan Ling, Kang Liu, Yifan Yang, Ting-Han Fan, Lingfeng Shen, Zhengyin Du, Jiecao Chen
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-02-14 (更新: 2025-10-23)
备注: 39 pages, 11 figures. The paper is accepted at NeurIPS 2025 Datasets & Benchmarks Track, and the latest version adds modifications in camera-ready
💡 一句话要点
MIR-Bench:提出多示例上下文推理基准,评估LLM在复杂模式识别中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多示例学习 上下文推理 模式识别 长上下文模型 LLM评估 基准测试 归纳推理 转导推理
📋 核心要点
- 现有LLM模式识别基准侧重于少样本,缺乏对长上下文多信息聚合能力的评估。
- 提出MIR-Bench,一个多示例上下文推理基准,通过输入输出示例预测复杂模式。
- 基于MIR-Bench,研究了缩放效应、鲁棒性、归纳/转导推理、RAG等多个问题。
📝 摘要(中文)
模式识别是通用智能的基础能力,心理学和人工智能研究者对此进行了广泛研究。虽然已经有许多基准测试用于评估大型语言模型(LLM)的这种能力,但它们主要集中在少样本(通常<10)设置,并且缺乏对从长上下文中聚合大量信息能力的评估。另一方面,LLM不断增长的上下文长度催生了多示例上下文学习(ICL)的新范式,该范式使用数百到数千个示例来处理新任务,而无需昂贵且低效的微调。然而,多示例评估通常侧重于分类,而流行的长上下文LLM任务(如Needle-In-A-Haystack (NIAH))很少需要复杂的智能来整合大量信息。为了解决这两个问题,我们提出了MIR-Bench,这是第一个用于模式识别的多示例上下文推理基准,它要求LLM通过来自具有不同数据格式的基础函数的输入-输出示例来预测输出。基于MIR-Bench,我们研究了多示例上下文推理的许多新问题,并获得了许多有见地的发现,包括缩放效应、鲁棒性、归纳与转导推理、检索增强生成(RAG)、用于归纳推理的编码、跨领域泛化等。
🔬 方法详解
问题定义:现有的大语言模型(LLM)评估基准在模式识别方面存在不足,主要体现在两个方面:一是侧重于少样本学习(few-shot learning),即只提供少量示例进行学习和推理;二是缺乏对长上下文信息整合能力的有效评估,无法充分利用LLM日益增长的上下文窗口。这导致无法全面评估LLM在复杂模式识别任务中的潜力。现有方法难以衡量LLM在需要整合大量信息才能识别潜在模式的场景下的表现。
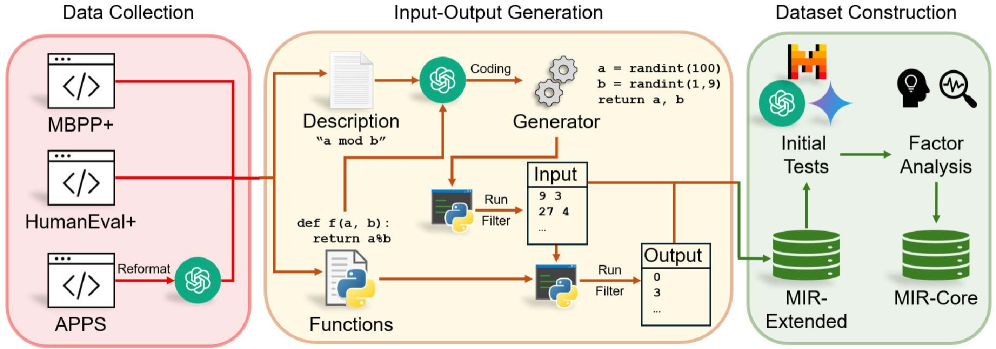
核心思路:论文的核心思路是构建一个多示例上下文推理(many-shot in-context reasoning)基准,即MIR-Bench,该基准通过提供大量的输入-输出示例,要求LLM从这些示例中学习并识别潜在的复杂模式,然后将这些模式应用于新的输入进行预测。这种设计旨在模拟真实世界中需要从大量数据中提取规律并进行推理的场景,从而更全面地评估LLM的模式识别能力。
技术框架:MIR-Bench的技术框架主要包含以下几个部分:1)定义一系列具有不同数据格式的基础函数,这些函数用于生成输入-输出示例;2)构建包含大量输入-输出示例的数据集,作为LLM进行上下文学习的依据;3)设计评估指标,用于衡量LLM在模式识别任务中的准确性和效率;4)利用该基准对不同的LLM进行评估,并分析其在多示例上下文推理方面的表现。整体流程是:给定大量输入输出示例,LLM需要学习潜在的函数关系,并预测新的输入对应的输出。
关键创新:MIR-Bench的关键创新在于:1)它是第一个专门针对多示例上下文推理的模式识别基准,填补了现有基准的空白;2)它使用了具有不同数据格式的基础函数,增加了任务的复杂性和多样性;3)它提供了大量的示例,使得LLM能够更好地学习和识别潜在的模式。与现有方法的本质区别在于,MIR-Bench更加关注LLM在长上下文和多信息整合方面的能力,而不仅仅是少样本学习。
关键设计:MIR-Bench的关键设计包括:1)基础函数的选择,需要保证函数具有一定的复杂性,同时又能够生成足够多的示例;2)数据集的构建,需要保证数据集的多样性和代表性,覆盖不同的数据格式和模式;3)评估指标的设计,需要能够准确地衡量LLM在模式识别任务中的表现,例如准确率、召回率、F1值等。此外,论文还研究了不同的上下文组织方式、示例选择策略等对LLM性能的影响。
🖼️ 关键图片
📊 实验亮点
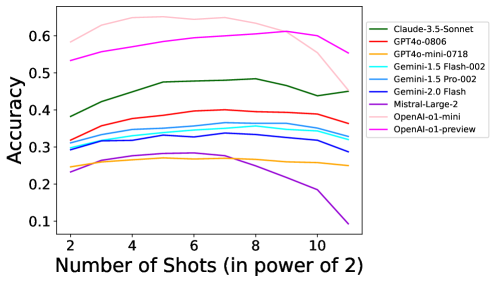
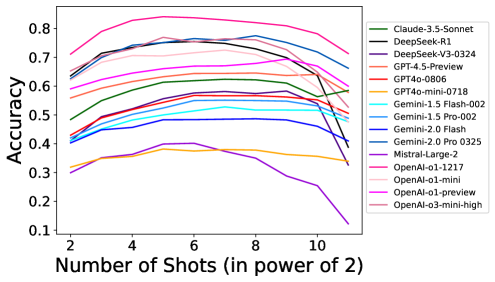
MIR-Bench的实验结果揭示了LLM在多示例上下文推理中的一些重要特性,例如缩放效应(scaling effect),即模型规模越大,性能越好;鲁棒性(robustness),即模型在面对噪声数据时的表现;以及归纳推理(inductive reasoning)和转导推理(transductive reasoning)之间的差异。此外,实验还探讨了检索增强生成(RAG)、编码等技术对LLM性能的影响。
🎯 应用场景
MIR-Bench可用于评估和提升LLM在各种需要复杂模式识别的实际应用中的性能,例如金融欺诈检测、网络安全威胁识别、生物信息学数据分析等。通过该基准,可以更好地了解LLM的优势和局限性,并指导LLM的改进和优化,从而推动人工智能技术的发展。
📄 摘要(原文)
The ability to recognize patterns from examples and apply them to new ones is a primal ability for general intelligence, and is widely studied by psychology and AI researchers. Many benchmarks have been proposed to measure such ability for Large Language Models (LLMs); however, they focus on few-shot (usually <10) setting and lack evaluation for aggregating many pieces of information from long contexts. On the other hand, the ever-growing context length of LLMs have brought forth the novel paradigm of many-shot In-Context Learning (ICL), which addresses new tasks with hundreds to thousands of examples without expensive and inefficient fine-tuning. However, many-shot evaluations often focus on classification, and popular long-context LLM tasks such as Needle-In-A-Haystack (NIAH) seldom require complicated intelligence for integrating many pieces of information. To fix the issues from both worlds, we propose MIR-Bench, the first many-shot in-context reasoning benchmark for pattern recognition that asks LLM to predict output via input-output examples from underlying functions with diverse data format. Based on MIR-Bench, we study many novel problems for many-shot in-context reasoning, and acquired many insightful findings including scaling effect, robustness, inductive vs. transductive reasoning, retrieval Augmented Generation (RAG), coding for inductive reasoning, cross-domain generalizability, etc.