Diverse Transformer Decoding for Offline Reinforcement Learning Using Financial Algorithmic Approaches
作者: Dan Elbaz, Oren Salzman
分类: cs.AI, cs.LG
发布日期: 2025-02-13
💡 一句话要点
提出Portfolio Beam Search,提升离线强化学习Transformer解码的多样性和鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 Transformer Beam Search 多样性解码 金融投资组合
📋 核心要点
- 离线强化学习中,Transformer解码常用的Beam Search方法忽略了数据集中固有的不确定性,导致探索不足。
- 论文提出Portfolio Beam Search (PBS),借鉴金融经济学思想,在解码过程中引入不确定性感知的多样化机制,平衡探索和利用。
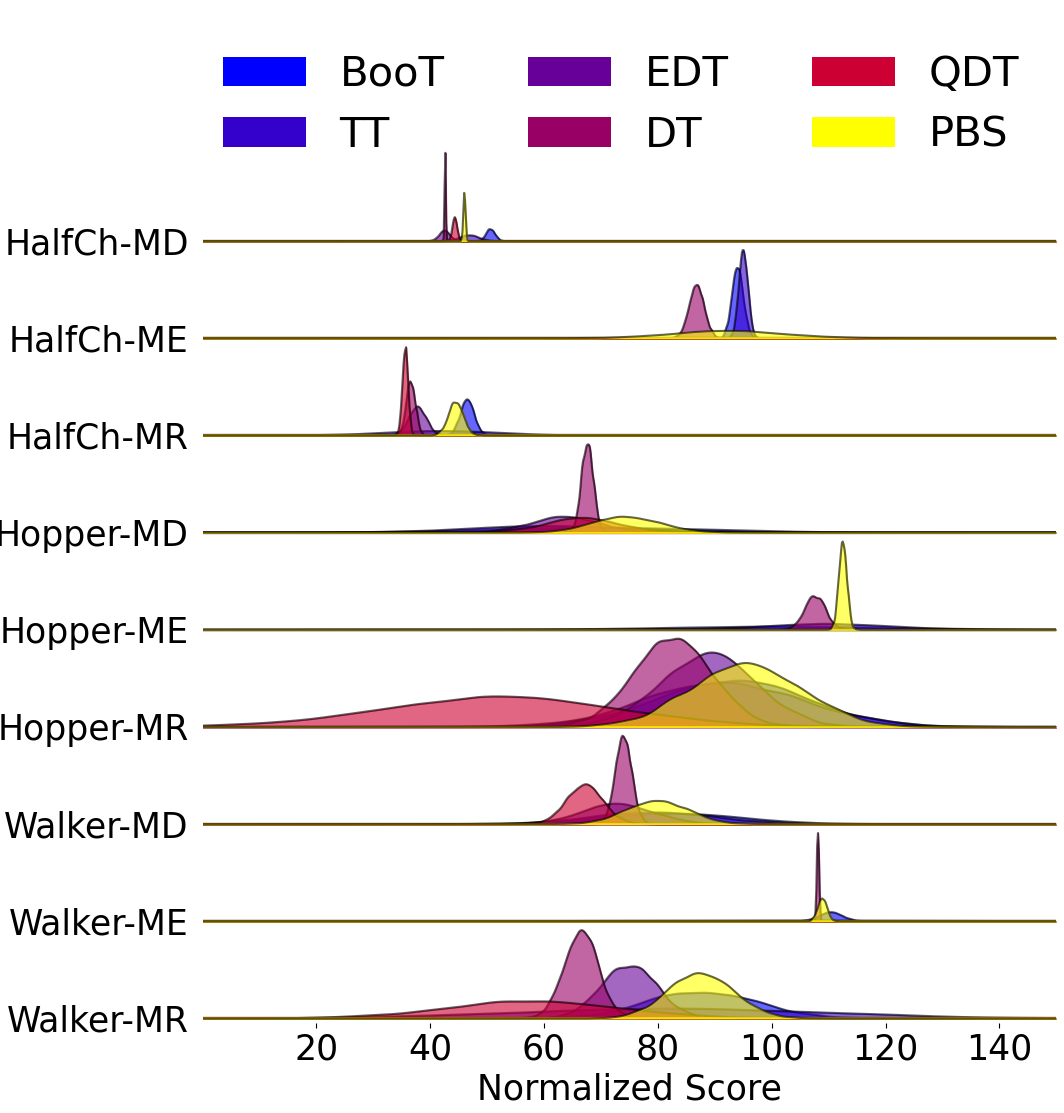
- 实验表明,PBS在D4RL locomotion基准测试中,相较于传统Beam Search,能获得更高的回报并降低结果的方差。
📝 摘要(中文)
离线强化学习(RL)算法使用固定的训练数据集学习策略,然后在实际环境中部署,进行决策。Transformer作为时间序列建模的标准选择,在离线RL中越来越受欢迎。通常,Beam Search (BS)是Transformer解码的首选方法。离线RL避免了代价高昂或有风险的在线数据收集。然而,受限的数据集会引入不确定性,因为智能体在执行过程中可能会遇到训练数据中未覆盖的陌生状态和动作序列。BS缺乏离线RL所需的两个重要属性:它没有考虑上述不确定性,并且其贪婪的从左到右搜索方法通常导致序列变化极小,无法探索潜在的更好选择。为了解决这些限制,我们提出了Portfolio Beam Search (PBS),这是一种简单而有效的BS替代方案,可以在解码过程中平衡Transformer模型中的探索和利用。我们从金融经济学中汲取灵感,并应用这些原则来开发一种不确定性感知的多样化机制,我们将其集成到推理时的顺序解码算法中。我们在D4RL locomotion基准上进行了实证研究,结果表明PBS实现了更高的回报,并显著降低了结果的可变性。
🔬 方法详解
问题定义:离线强化学习旨在利用静态数据集训练策略,避免在线交互带来的成本和风险。然而,离线数据集的局限性导致智能体在部署时可能遇到未知的状态-动作序列,产生不确定性。传统的Beam Search解码方法是一种贪婪搜索算法,容易陷入局部最优,无法有效探索潜在的更优策略,且忽略了离线数据带来的不确定性。
核心思路:论文的核心思路是借鉴金融投资组合的概念,将Beam Search中的每个候选序列视为一种“资产”,通过构建一个多样化的“投资组合”,来平衡探索和利用。具体来说,就是鼓励在搜索过程中生成更多样化的序列,从而降低对初始选择的依赖,并提高找到全局最优解的可能性。这种多样化策略能够更好地应对离线数据带来的不确定性。
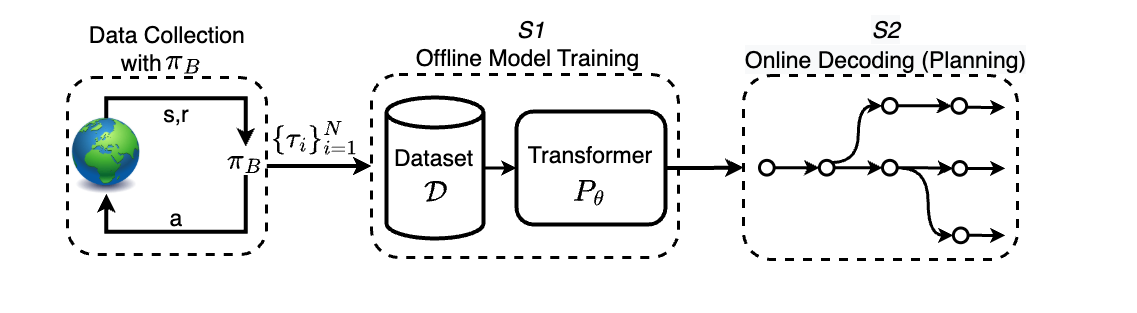
技术框架:Portfolio Beam Search (PBS) 沿用 Transformer 的整体架构,主要改进在于解码阶段。PBS 在每个解码步骤中,维护一个包含多个候选序列的集合(beam)。与标准 Beam Search 不同的是,PBS 在选择下一个候选序列时,不仅考虑序列的得分(例如,模型预测的概率),还考虑序列之间的多样性。具体流程如下: 1. 初始化:使用初始状态作为起始序列,放入 beam 中。 2. 迭代解码:对于 beam 中的每个序列,预测下一个动作的概率分布。 3. 候选生成:根据概率分布,采样生成多个候选动作,扩展现有序列。 4. 多样性评估:评估新生成的序列与 beam 中现有序列的多样性。 5. 序列选择:综合考虑序列得分和多样性,选择得分高且与现有序列差异大的序列,更新 beam。 6. 重复步骤 2-5,直到达到最大序列长度。
关键创新:PBS 的关键创新在于引入了不确定性感知的多样化机制。它通过评估候选序列与现有序列之间的差异,鼓励选择更多样化的序列。这种机制借鉴了金融投资组合理论中的风险分散思想,旨在降低对单一“最优”序列的过度依赖,从而提高鲁棒性和探索能力。与传统的 Beam Search 相比,PBS 能够更好地应对离线数据带来的不确定性,并找到更优的策略。
关键设计:PBS 的关键设计包括: 1. 多样性度量:论文可能采用某种距离度量(例如,编辑距离、余弦相似度)来衡量序列之间的差异。 2. 多样性权重:引入一个超参数来控制多样性在序列选择中的重要性。该参数用于平衡序列得分和多样性之间的权衡。 3. 序列选择策略:设计一种策略来综合考虑序列得分和多样性,例如,加权平均、排序等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PBS在D4RL locomotion基准测试中,相较于传统的Beam Search,能够显著提高策略的回报,并降低结果的方差。具体而言,PBS在多个任务上取得了更高的平均回报,并且回报的波动性更小,表明其具有更好的鲁棒性和泛化能力。这些结果验证了PBS在离线强化学习中的有效性。
🎯 应用场景
该研究成果可应用于各种离线强化学习场景,例如机器人控制、自动驾驶、金融交易等。在这些场景中,智能体需要在有限的离线数据上学习策略,并部署到真实环境中。PBS能够提高策略的鲁棒性和泛化能力,降低部署风险,具有重要的实际应用价值。未来,该方法可以进一步扩展到其他序列生成任务中,例如自然语言生成、图像生成等。
📄 摘要(原文)
Offline Reinforcement Learning (RL) algorithms learn a policy using a fixed training dataset, which is then deployed online to interact with the environment and make decisions. Transformers, a standard choice for modeling time-series data, are gaining popularity in offline RL. In this context, Beam Search (BS), an approximate inference algorithm, is the go-to decoding method. Offline RL eliminates the need for costly or risky online data collection. However, the restricted dataset induces uncertainty as the agent may encounter unfamiliar sequences of states and actions during execution that were not covered in the training data. In this context, BS lacks two important properties essential for offline RL: It does not account for the aforementioned uncertainty, and its greedy left-right search approach often results in sequences with minimal variations, failing to explore potentially better alternatives. To address these limitations, we propose Portfolio Beam Search (PBS), a simple-yet-effective alternative to BS that balances exploration and exploitation within a Transformer model during decoding. We draw inspiration from financial economics and apply these principles to develop an uncertainty-aware diversification mechanism, which we integrate into a sequential decoding algorithm at inference time. We empirically demonstrate the effectiveness of PBS on the D4RL locomotion benchmark, where it achieves higher returns and significantly reduces outcome variability.