EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents
作者: Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, Heng Ji, Huan Zhang, Tong Zhang
分类: cs.AI, cs.CL, cs.CV
发布日期: 2025-02-13 (更新: 2025-06-05)
备注: Accepted to ICML 2025
💡 一句话要点
EmbodiedBench:用于视觉驱动具身智能体的多模态大语言模型综合评测基准
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能体 多模态大语言模型 基准测试 视觉驱动 机器人 环境感知 任务规划
📋 核心要点
- 现有的具身智能体研究主要集中在语言驱动,缺乏对多模态大语言模型(MLLM)驱动的具身智能体的全面评估。
- EmbodiedBench通过构建包含多样化任务和评估子集的基准,系统性地评估MLLM在具身智能体中的能力。
- 实验结果表明,MLLM在高层任务中表现良好,但在低层操作任务中存在明显不足,为未来研究指明方向。
📝 摘要(中文)
本文提出了EmbodiedBench,一个全面的基准测试,旨在评估视觉驱动的具身智能体。该基准包含四个环境中1128个不同的测试任务,涵盖从高层语义任务(如家庭环境任务)到涉及原子动作的低层任务(如导航和操作)。EmbodiedBench还包括六个精心策划的子集,用于评估智能体的关键能力,如常识推理、复杂指令理解、空间感知、视觉感知和长期规划。通过广泛的实验,我们在EmbodiedBench中评估了24个领先的专有和开源多模态大语言模型(MLLM)。结果表明,MLLM擅长高层任务,但在低层操作方面表现不佳,即使是最好的模型GPT-4o,平均得分也仅为28.9%。EmbodiedBench提供了一个多方面的标准化评估平台,不仅突出了现有挑战,还为推进基于MLLM的具身智能体提供了宝贵的见解。
🔬 方法详解
问题定义:现有具身智能体评估框架不足以全面评估基于多模态大语言模型(MLLM)的视觉驱动具身智能体。现有方法难以覆盖从高层语义理解到低层原子动作控制的完整能力谱系,缺乏对常识推理、空间感知等关键能力的针对性评估。这阻碍了MLLM在具身智能体领域的有效应用和发展。
核心思路:EmbodiedBench的核心思路是构建一个多样化、细粒度的评估基准,通过覆盖不同环境、任务类型和能力维度,全面评估MLLM驱动的具身智能体的性能。通过精心设计的任务和评估指标,揭示MLLM在具身智能体应用中的优势和不足,为未来的研究提供指导。
技术框架:EmbodiedBench包含四个环境,涵盖高层语义任务(如家庭环境)和低层原子动作任务(如导航和操作)。它包含1128个测试任务,并划分为六个评估子集,分别针对常识推理、复杂指令理解、空间感知、视觉感知和长期规划等关键能力。评估流程包括:输入视觉信息和任务指令给MLLM,MLLM生成动作指令,智能体执行动作,根据环境反馈和任务完成情况进行评估。
关键创新:EmbodiedBench的关键创新在于其综合性和细粒度。它不仅覆盖了多种环境和任务类型,还针对具身智能体的关键能力设计了专门的评估子集。这种设计使得研究人员能够更全面地了解MLLM在具身智能体应用中的性能瓶颈,并有针对性地进行改进。
关键设计:EmbodiedBench的关键设计包括:(1) 任务的多样性,涵盖了从高层语义理解到低层原子动作控制的不同难度级别;(2) 评估子集的针对性,每个子集都专注于评估智能体的特定能力;(3) 评估指标的合理性,能够准确反映智能体在不同任务上的表现。
🖼️ 关键图片


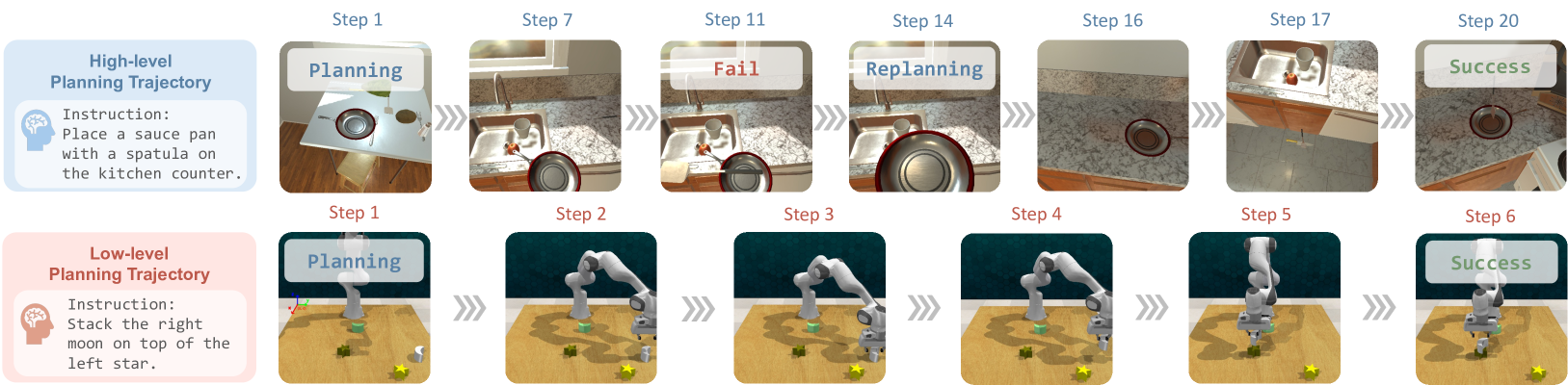
📊 实验亮点
实验结果表明,GPT-4o在EmbodiedBench上的平均得分仅为28.9%,表明MLLM在低层操作任务中仍存在显著不足。同时,MLLM在高层语义任务中表现相对较好,但仍有提升空间。EmbodiedBench的评估结果为未来研究提供了重要的参考,指明了MLLM在具身智能体应用中的发展方向。
🎯 应用场景
EmbodiedBench的研究成果可应用于机器人、智能家居、自动驾驶等领域。通过该基准,研究人员可以更有效地评估和改进MLLM驱动的具身智能体,从而开发出更智能、更自主的机器人系统,提升其在复杂环境中的适应性和交互能力。未来,该基准可以扩展到更多环境和任务,推动具身智能体的实际应用。
📄 摘要(原文)
Leveraging Multi-modal Large Language Models (MLLMs) to create embodied agents offers a promising avenue for tackling real-world tasks. While language-centric embodied agents have garnered substantial attention, MLLM-based embodied agents remain underexplored due to the lack of comprehensive evaluation frameworks. To bridge this gap, we introduce EmbodiedBench, an extensive benchmark designed to evaluate vision-driven embodied agents. EmbodiedBench features: (1) a diverse set of 1,128 testing tasks across four environments, ranging from high-level semantic tasks (e.g., household) to low-level tasks involving atomic actions (e.g., navigation and manipulation); and (2) six meticulously curated subsets evaluating essential agent capabilities like commonsense reasoning, complex instruction understanding, spatial awareness, visual perception, and long-term planning. Through extensive experiments, we evaluated 24 leading proprietary and open-source MLLMs within EmbodiedBench. Our findings reveal that: MLLMs excel at high-level tasks but struggle with low-level manipulation, with the best model, GPT-4o, scoring only 28.9\% on average. EmbodiedBench provides a multifaceted standardized evaluation platform that not only highlights existing challenges but also offers valuable insights to advance MLLM-based embodied agents. Our code and dataset are available at https://embodiedbench.github.io.