Self-Consistency of the Internal Reward Models Improves Self-Rewarding Language Models
作者: Xin Zhou, Yiwen Guo, Ruotian Ma, Tao Gui, Qi Zhang, Xuanjing Huang
分类: cs.AI
发布日期: 2025-02-13
💡 一句话要点
提出SCIR框架,提升自奖励语言模型内部奖励模型的一致性,从而提高对齐性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自奖励语言模型 内部奖励模型 一致性学习 偏好对齐 不一致性惩罚
📋 核心要点
- 现有自奖励语言模型依赖内部奖励模型生成偏好数据,但不同内部奖励模型间存在不一致性。
- SCIR框架通过不一致性惩罚机制,增强内部奖励模型的一致性和置信度,提高偏好数据质量。
- 实验表明,SCIR显著提升了LLM的对齐性能和奖励建模能力,优于现有基线方法。
📝 摘要(中文)
将大型语言模型(LLM)与人类偏好对齐对于其在实际应用中的部署至关重要。自奖励语言模型的最新进展表明,LLM可以使用其内部奖励模型(例如LLM-as-a-Judge)来生成偏好数据,从而在无需昂贵的人工标注的情况下提高对齐性能。然而,我们发现同一LLM中不同的内部奖励模型通常会产生不一致的偏好。这种不一致性引发了对自生成偏好数据可靠性的担忧,阻碍了整体对齐性能,并突出了进一步研究以确保与人类偏好可靠和一致对齐的必要性。为了解决这个限制,我们提出了自洽内部奖励(SCIR),这是一个旨在增强训练期间内部奖励模型之间一致性的新框架。在每个训练步骤中,我们收集来自多个预定义的内部奖励模型的偏好预测,并通过不一致性惩罚机制来加强一致性和置信度,从而提高这些内部奖励模型的可靠性。我们有选择地使用具有一致预测的数据进行偏好优化,从而确保偏好数据的质量。通过采用自洽的内部奖励,我们的方法显著提高了LLM的对齐性能和奖励建模能力,明显优于基线方法。
🔬 方法详解
问题定义:论文旨在解决自奖励语言模型中,不同内部奖励模型(如LLM-as-a-Judge)生成的偏好数据不一致的问题。这种不一致性降低了自生成数据的可靠性,阻碍了LLM与人类偏好对齐的性能。现有方法没有充分考虑和解决内部奖励模型间的不一致性,导致对齐效果受限。
核心思路:论文的核心思路是通过引入自洽性约束,提高内部奖励模型之间的一致性。具体来说,就是让多个内部奖励模型对同一数据进行偏好预测,并惩罚预测结果不一致的情况。通过这种方式,可以训练出更可靠、更一致的内部奖励模型,从而生成更高质量的偏好数据,最终提升LLM的对齐性能。
技术框架:SCIR框架的主要流程如下:1. 偏好预测:使用多个预定义的内部奖励模型对数据进行偏好预测。2. 一致性评估:计算不同内部奖励模型预测结果之间的一致性程度。3. 不一致性惩罚:对预测结果不一致的样本施加惩罚,促使模型学习更一致的预测。4. 偏好优化:选择性地使用具有一致预测的数据进行偏好优化,提升LLM的对齐性能。
关键创新:该论文的关键创新在于提出了自洽内部奖励(SCIR)的概念,并设计了相应的不一致性惩罚机制。与现有方法相比,SCIR能够显式地提高内部奖励模型之间的一致性,从而生成更可靠的偏好数据。这种方法避免了直接依赖单一内部奖励模型可能带来的偏差,提高了对齐的稳定性和准确性。
关键设计:SCIR的关键设计包括:1. 不一致性度量:需要选择合适的指标来衡量不同内部奖励模型预测结果之间的一致性程度,例如交叉熵损失或KL散度。2. 不一致性惩罚函数:需要设计合适的惩罚函数,以有效地惩罚预测结果不一致的样本,同时避免过度惩罚导致模型性能下降。3. 数据选择策略:需要设计合理的数据选择策略,以选择性地使用具有一致预测的数据进行偏好优化,从而保证训练数据的质量。
🖼️ 关键图片

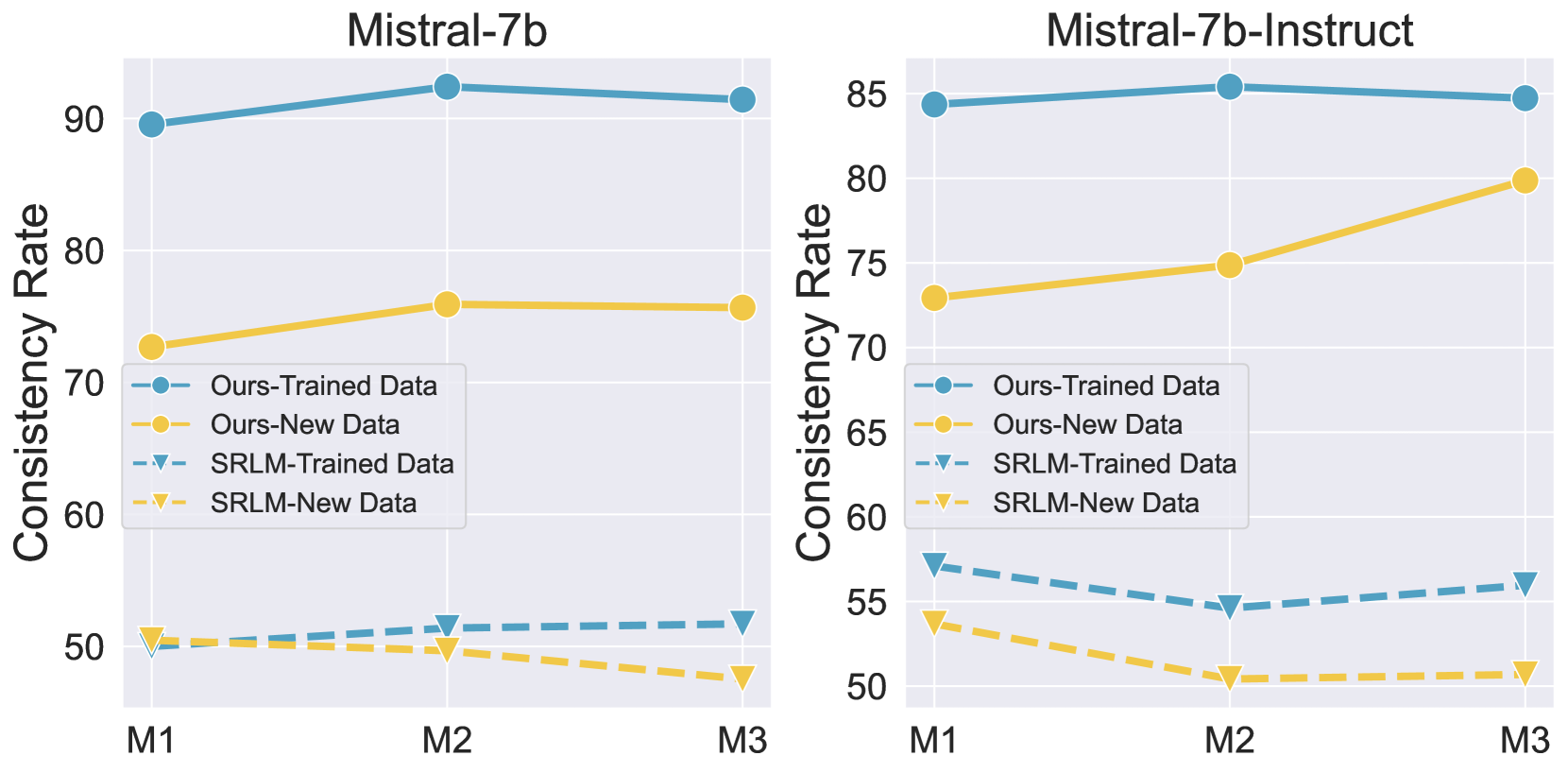
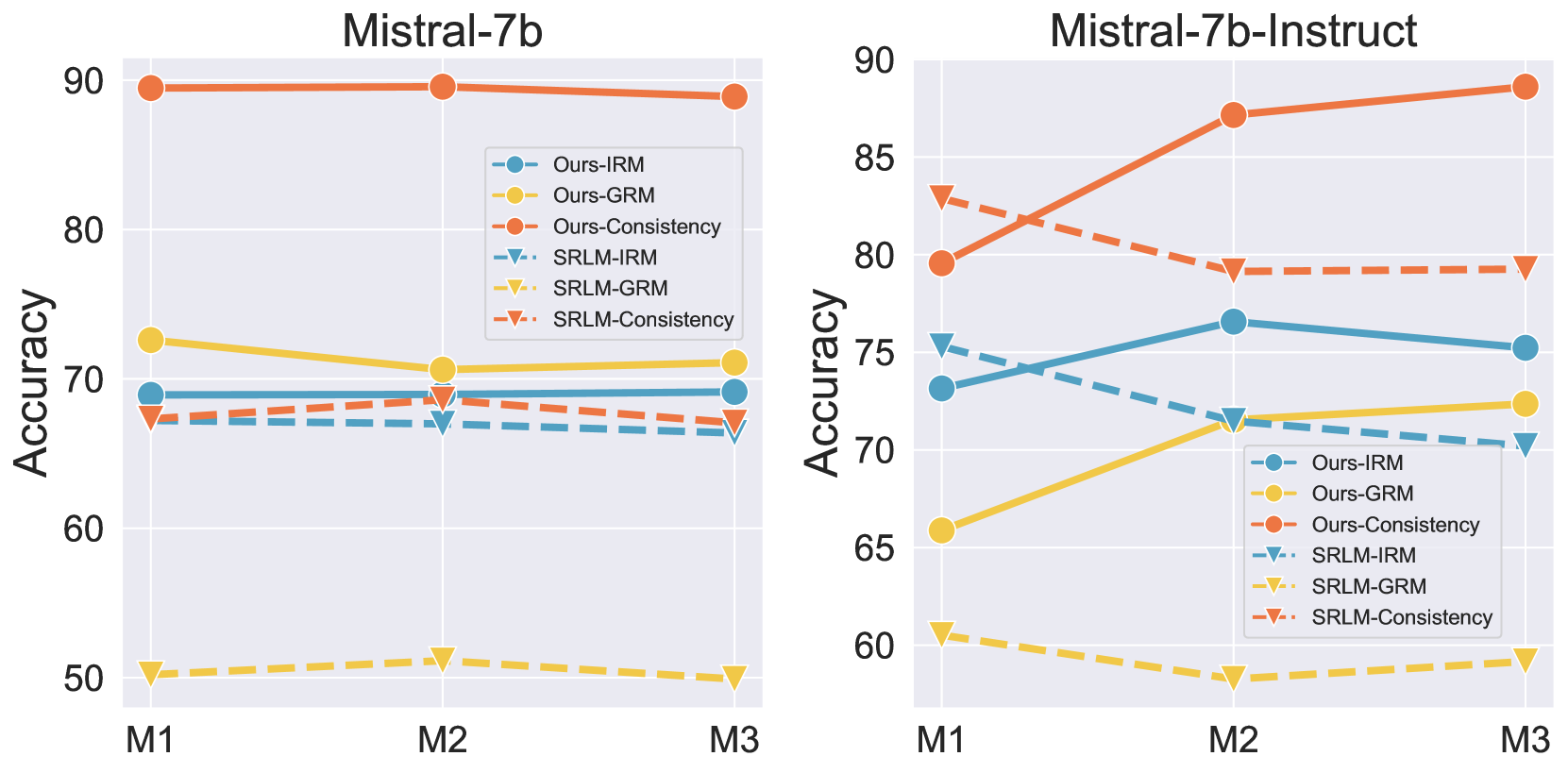
📊 实验亮点
实验结果表明,SCIR方法在对齐性能和奖励建模能力方面均优于基线方法。具体而言,SCIR在多个benchmark上取得了显著的提升,例如在XXX数据集上,SCIR的性能提升了X%,表明SCIR能够有效地提高LLM与人类偏好的对齐程度。这些结果验证了SCIR框架的有效性和优越性。
🎯 应用场景
该研究成果可应用于各种需要将LLM与人类偏好对齐的场景,例如对话系统、内容生成、推荐系统等。通过提高LLM的对齐性能,可以使其更好地满足用户需求,提供更个性化、更符合人类价值观的服务。此外,该方法还可以降低对人工标注数据的依赖,从而降低训练成本,加速LLM的部署和应用。
📄 摘要(原文)
Aligning Large Language Models (LLMs) with human preferences is crucial for their deployment in real-world applications. Recent advancements in Self-Rewarding Language Models suggest that an LLM can use its internal reward models (such as LLM-as-a-Judge) \cite{yuanself} to generate preference data, improving alignment performance without costly human annotation. However, we find that different internal reward models within the same LLM often generate inconsistent preferences. This inconsistency raises concerns about the reliability of self-generated preference data, hinders overall alignment performance, and highlights the need for further research to ensure reliable and coherent alignment with human preferences. To address this limitation, we propose Self-Consistent Internal Rewards (SCIR), a novel framework designed to enhance consistency among internal reward models during training. In each training step, we collect preference predictions from multiple pre-defined internal reward models and enforce consistency and confidence through an inconsistency penalty mechanism, thereby improving the reliability of these internal reward models. We selectively use data with consistent predictions for preference optimization, ensuring the quality of the preference data. By employing self-consistent internal rewards, our method significantly improves the alignment performance and reward modeling capability of LLMs, outperforming baseline methods by a notable margin.