EnigmaEval: A Benchmark of Long Multimodal Reasoning Challenges
作者: Clinton J. Wang, Dean Lee, Cristina Menghini, Johannes Mols, Jack Doughty, Adam Khoja, Jayson Lynch, Sean Hendryx, Summer Yue, Dan Hendrycks
分类: cs.AI, cs.CL
发布日期: 2025-02-13 (更新: 2025-02-14)
💡 一句话要点
提出EnigmaEval:一个长程多模态推理挑战基准,用于评估语言模型的认知能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 长程推理 知识综合 谜题解决 语言模型评估
📋 核心要点
- 现有推理基准已无法充分评估语言模型的高级认知能力,需要更具挑战性的测试。
- EnigmaEval利用谜题解决活动,通过发现信息间隐藏联系来考察模型的推理能力。
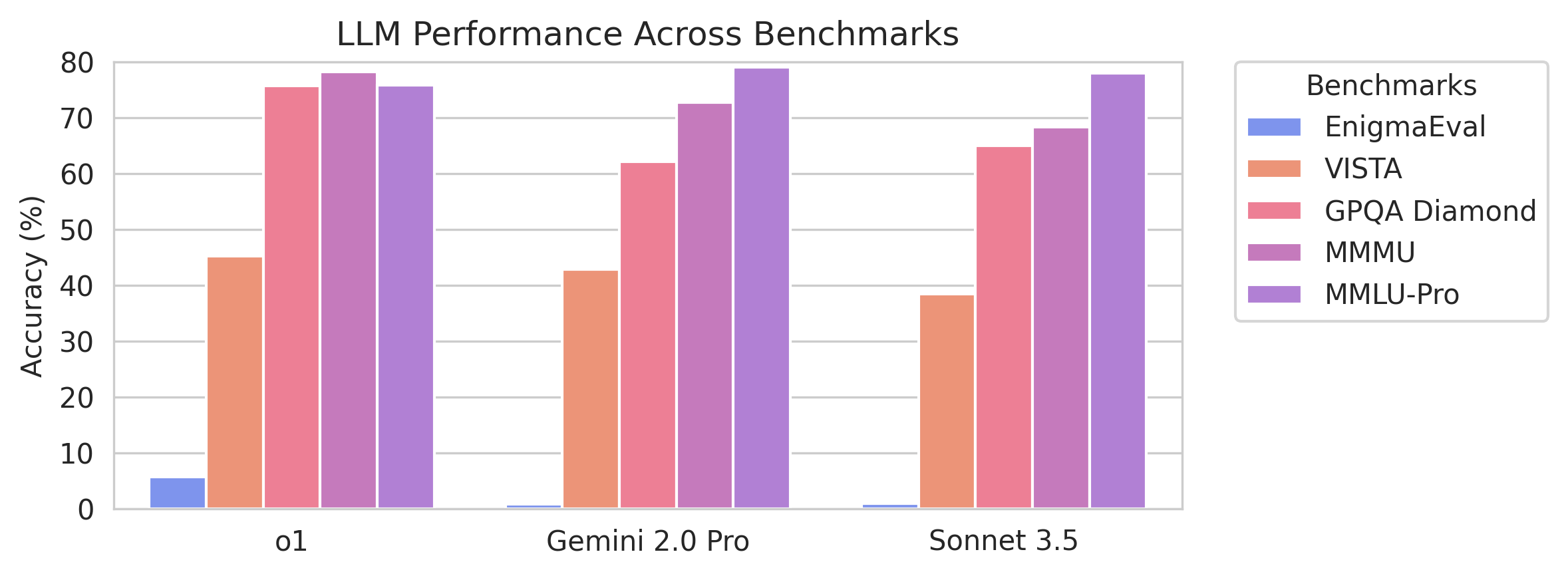
- 实验表明,现有SOTA语言模型在EnigmaEval上表现不佳,凸显了其在非结构化推理方面的不足。
📝 摘要(中文)
随着语言模型在现有推理基准测试中表现越来越好,我们需要新的挑战来评估它们的认知边界。谜题解决活动是具有挑战性的多模态问题的丰富来源,这些问题测试了广泛的高级推理和知识能力,使其成为评估前沿语言模型的独特试验台。我们介绍了EnigmaEval,这是一个从谜题竞赛和活动中提取的问题和解决方案的数据集,用于探测模型执行隐式知识综合和多步演绎推理的能力。与现有的推理和知识基准不同,谜题解决挑战模型去发现看似不相关的碎片信息之间的隐藏联系,从而揭示解决方案路径。该基准包括1184个不同复杂度的谜题——每个谜题通常需要熟练的解题团队花费数小时甚至数天才能完成——具有明确的、可验证的解决方案,从而实现高效的评估。最先进的语言模型在这些谜题上的准确率极低,甚至低于其他困难的基准,如Humanity's Last Exam,揭示了模型在面对需要非结构化和横向推理的问题时的缺点。
🔬 方法详解
问题定义:论文旨在解决现有语言模型在复杂、非结构化推理任务上的不足。现有推理基准往往过于简单或结构化,无法有效评估模型在真实世界场景下的认知能力。谜题解决问题需要模型具备隐式知识综合、多步演绎推理以及发现看似无关信息之间联系的能力,这对现有模型构成了巨大挑战。
核心思路:论文的核心思路是利用谜题解决活动作为评估语言模型认知能力的测试平台。谜题通常需要结合多种知识、进行多步推理,并且需要发现隐藏的关联,这与真实世界的问题解决过程非常相似。通过构建一个包含大量谜题的数据集,可以更全面地评估模型的推理能力。
技术框架:EnigmaEval数据集包含1184个谜题,这些谜题来源于谜题竞赛和活动。每个谜题都具有明确的、可验证的解决方案,这使得评估过程更加高效和客观。数据集中的谜题具有不同的复杂度,有些谜题甚至需要专业的解题团队花费数小时甚至数天才能解决。评估过程主要通过计算语言模型在解决这些谜题时的准确率来实现。
关键创新:EnigmaEval的关键创新在于其选择的评估任务——谜题解决。与传统的推理基准相比,谜题解决更侧重于考察模型在非结构化、多模态环境下的推理能力。它要求模型能够发现隐藏的关联、综合不同的知识,并进行多步演绎推理。这种评估方式更接近于真实世界的问题解决场景,能够更有效地揭示模型的认知局限性。
关键设计:EnigmaEval数据集中的谜题来源于真实的谜题竞赛和活动,保证了其难度和多样性。每个谜题都经过精心挑选,确保其具有明确的解决方案,并且能够考察模型的多方面推理能力。数据集还提供了谜题的难度等级,方便研究人员根据自己的需求选择合适的谜题进行评估。此外,数据集还提供了谜题的元数据,例如谜题的来源、类型等,方便研究人员进行更深入的分析。
🖼️ 关键图片


📊 实验亮点
实验结果表明,最先进的语言模型在EnigmaEval上的准确率极低,远低于其他困难的基准,如Humanity's Last Exam。这表明现有模型在处理需要非结构化和横向推理的问题时存在显著的局限性。该基准的推出为未来的研究提供了一个重要的评估工具,并指明了语言模型发展的方向。
🎯 应用场景
EnigmaEval可用于评估和提升语言模型在复杂推理、知识综合和问题解决方面的能力。其应用领域包括智能助手、自动化推理系统、以及需要处理非结构化信息的各种AI应用。该基准的推出将推动语言模型向更强的认知能力发展,使其在更广泛的实际场景中发挥作用。
📄 摘要(原文)
As language models master existing reasoning benchmarks, we need new challenges to evaluate their cognitive frontiers. Puzzle-solving events are rich repositories of challenging multimodal problems that test a wide range of advanced reasoning and knowledge capabilities, making them a unique testbed for evaluating frontier language models. We introduce EnigmaEval, a dataset of problems and solutions derived from puzzle competitions and events that probes models' ability to perform implicit knowledge synthesis and multi-step deductive reasoning. Unlike existing reasoning and knowledge benchmarks, puzzle solving challenges models to discover hidden connections between seemingly unrelated pieces of information to uncover solution paths. The benchmark comprises 1184 puzzles of varying complexity -- each typically requiring teams of skilled solvers hours to days to complete -- with unambiguous, verifiable solutions that enable efficient evaluation. State-of-the-art language models achieve extremely low accuracy on these puzzles, even lower than other difficult benchmarks such as Humanity's Last Exam, unveiling models' shortcomings when challenged with problems requiring unstructured and lateral reasoning.