Neuromorphic Principles for Efficient Large Language Models on Intel Loihi 2
作者: Steven Abreu, Sumit Bam Shrestha, Rui-Jie Zhu, Jason Eshraghian
分类: cs.NE, cs.AI, cs.AR, cs.LG
发布日期: 2025-02-12 (更新: 2025-03-25)
备注: Accepted to International Conference on Learning Representations (ICLR) Workshop on Scalable Optimization for Efficient and Adaptive Foundation Models (SCOPE)
💡 一句话要点
提出基于Loihi 2神经形态芯片的无MatMul大语言模型,实现高效推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经形态计算 大语言模型 Loihi 2 低功耗 边缘计算 无矩阵乘法 量化
📋 核心要点
- 大型语言模型能耗高昂,限制了其在资源受限设备上的部署。
- 论文提出一种无需矩阵乘法的LLM架构,适配Intel Loihi 2神经形态芯片,利用其低精度和事件驱动计算特性。
- 实验结果表明,该模型在边缘GPU上实现了更高的吞吐量和更低的能耗,并具备良好的扩展性。
📝 摘要(中文)
大型语言模型(LLMs)性能卓越,但能耗巨大。本文提出了一种适用于Intel神经形态处理器Loihi 2的、无需矩阵乘法(MatMul-free)的LLM架构。该方法利用Loihi 2对低精度、事件驱动计算和状态处理的支持。在GPU上的硬件感知量化模型表明,一个3.7亿参数的MatMul-free模型可以在不损失精度的情况下进行量化。初步结果表明,与边缘GPU上基于Transformer的LLM相比,吞吐量提高了3倍,能耗降低了2倍,并且具有更好的扩展性。进一步的硬件优化将提高吞吐量并降低能耗。这些结果表明了神经形态硬件在高效推理方面的潜力,并为能够快速且经济高效地生成复杂长文本的高效推理模型铺平了道路。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)依赖于大量的矩阵乘法运算,这导致了极高的计算复杂度和能耗,尤其是在边缘设备上部署时,这一问题尤为突出。因此,如何在保持模型性能的同时,显著降低LLM的能耗,是当前面临的一个重要挑战。
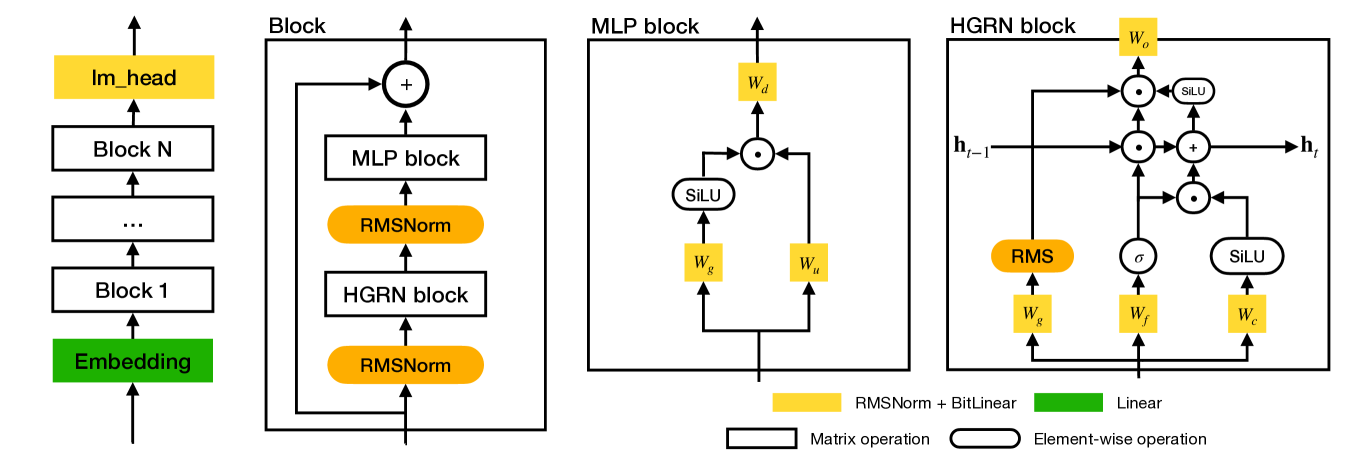
核心思路:论文的核心思路是设计一种无需矩阵乘法的LLM架构,从而避免传统LLM中高能耗的矩阵乘法运算。通过将模型适配到Intel的Loihi 2神经形态处理器上,利用其低精度、事件驱动计算和状态处理的特性,实现高效的推理。
技术框架:该方法首先设计了一种MatMul-free的LLM架构。然后,针对Loihi 2的硬件特性,对模型进行量化和优化。最后,在Loihi 2上进行推理,并与传统的基于Transformer的LLM在边缘GPU上进行比较。整体流程包括模型设计、量化优化和硬件部署三个主要阶段。
关键创新:该论文最重要的技术创新点在于提出了一个完全无需矩阵乘法的LLM架构。与传统的基于Transformer的LLM相比,该架构避免了高能耗的矩阵乘法运算,从而显著降低了模型的能耗。此外,该方法还充分利用了Loihi 2神经形态处理器的特性,进一步提高了推理效率。
关键设计:论文中提到在GPU上对模型进行了硬件感知量化,以确保在Loihi 2上部署时不会损失精度。虽然没有详细说明量化的具体方法,但可以推断使用了针对Loihi 2硬件特性的量化策略。此外,论文强调了对模型架构的调整,使其能够充分利用Loihi 2的事件驱动计算和状态处理能力。具体的网络结构和参数设置在论文中没有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该MatMul-free LLM在边缘GPU上实现了高达3倍的吞吐量提升,同时能耗降低了2倍。此外,该模型还表现出良好的扩展性,这意味着随着模型规模的增大,其性能优势将更加明显。3.7亿参数的MatMul-free模型可以在不损失精度的情况下进行量化,这为在资源受限的设备上部署大型语言模型提供了新的可能性。
🎯 应用场景
该研究成果可应用于资源受限的边缘设备,例如移动设备、物联网设备和机器人等,实现高效的本地化语言处理。这使得在这些设备上部署复杂的LLM成为可能,从而支持各种应用,如智能助手、自然语言理解和生成、以及实时翻译等。此外,该研究还有助于推动神经形态计算在人工智能领域的应用。
📄 摘要(原文)
Large language models (LLMs) deliver impressive performance but require large amounts of energy. In this work, we present a MatMul-free LLM architecture adapted for Intel's neuromorphic processor, Loihi 2. Our approach leverages Loihi 2's support for low-precision, event-driven computation and stateful processing. Our hardware-aware quantized model on GPU demonstrates that a 370M parameter MatMul-free model can be quantized with no accuracy loss. Based on preliminary results, we report up to 3x higher throughput with 2x less energy, compared to transformer-based LLMs on an edge GPU, with significantly better scaling. Further hardware optimizations will increase throughput and decrease energy consumption. These results show the potential of neuromorphic hardware for efficient inference and pave the way for efficient reasoning models capable of generating complex, long-form text rapidly and cost-effectively.