Universal Adversarial Attack on Aligned Multimodal LLMs
作者: Temurbek Rahmatullaev, Polina Druzhinina, Nikita Kurdiukov, Matvey Mikhalchuk, Andrey Kuznetsov, Anton Razzhigaev
分类: cs.AI
发布日期: 2025-02-11 (更新: 2025-06-04)
备注: Added benchmarks, baselines, author, appendix
💡 一句话要点
提出针对多模态LLM的通用对抗攻击,利用单张优化图像绕过对齐安全措施。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 对抗攻击 大型语言模型 安全性 通用性
📋 核心要点
- 现有方法难以有效对抗多模态LLM,尤其是在绕过对齐安全措施方面存在挑战。
- 该方法通过优化单张图像,使其能够诱导多模态LLM针对不同查询输出目标短语或不安全内容。
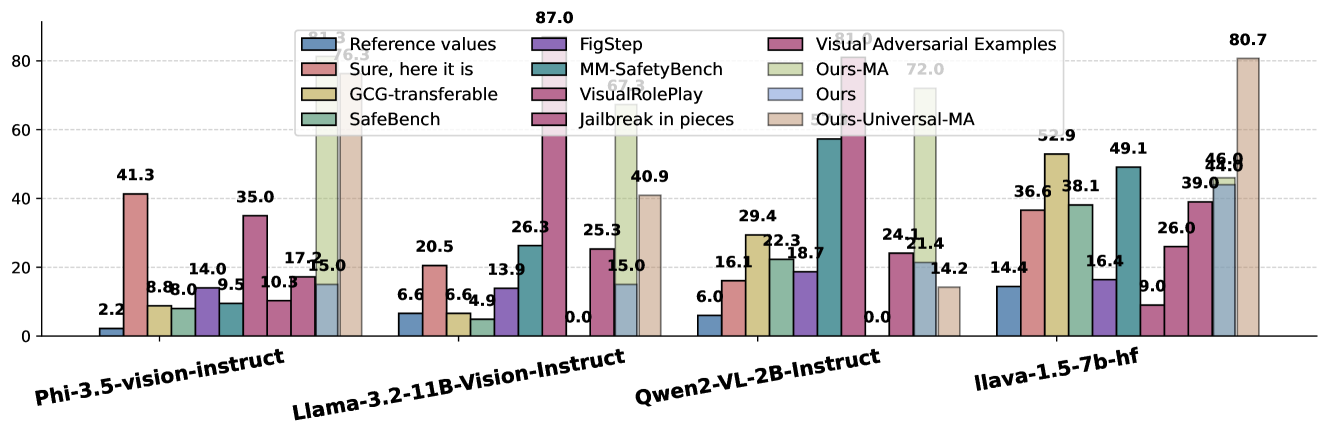
- 实验表明,该方法在攻击成功率上优于现有基线,并在跨模型通用性方面表现良好。
📝 摘要(中文)
本文提出了一种针对多模态大型语言模型(LLM)的通用对抗攻击方法,该方法利用单张优化的图像来覆盖各种查询甚至多个模型中的对齐安全措施。通过反向传播视觉编码器和语言头,我们生成一张合成图像,迫使模型以目标短语(例如,“当然,给你”)或不安全的内容进行响应,即使是对于有害的提示也是如此。在SafeBench和MM-SafetyBench基准测试中,我们的方法比现有的基线方法实现了更高的攻击成功率,包括纯文本通用提示(例如,在某些模型上高达81%)。我们还通过同时在多个多模态LLM上进行训练来证明了跨模型通用性。此外,我们的方法的多答案变体产生了听起来更自然(但仍然是恶意的)的响应。这些发现突出了当前多模态对齐中的关键漏洞,并呼吁采取更强大的对抗防御措施。我们将以Apache-2.0许可证发布代码和数据集。警告:本文中多模态LLM生成的一些内容可能具有攻击性。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(LLM)的安全性问题,具体而言,是如何绕过这些模型中内置的对齐安全措施,使其在接收到恶意输入时仍然能够输出有害或不当内容。现有方法,如纯文本对抗提示,在多模态场景下效果不佳,难以有效利用视觉信息来触发模型的安全漏洞。
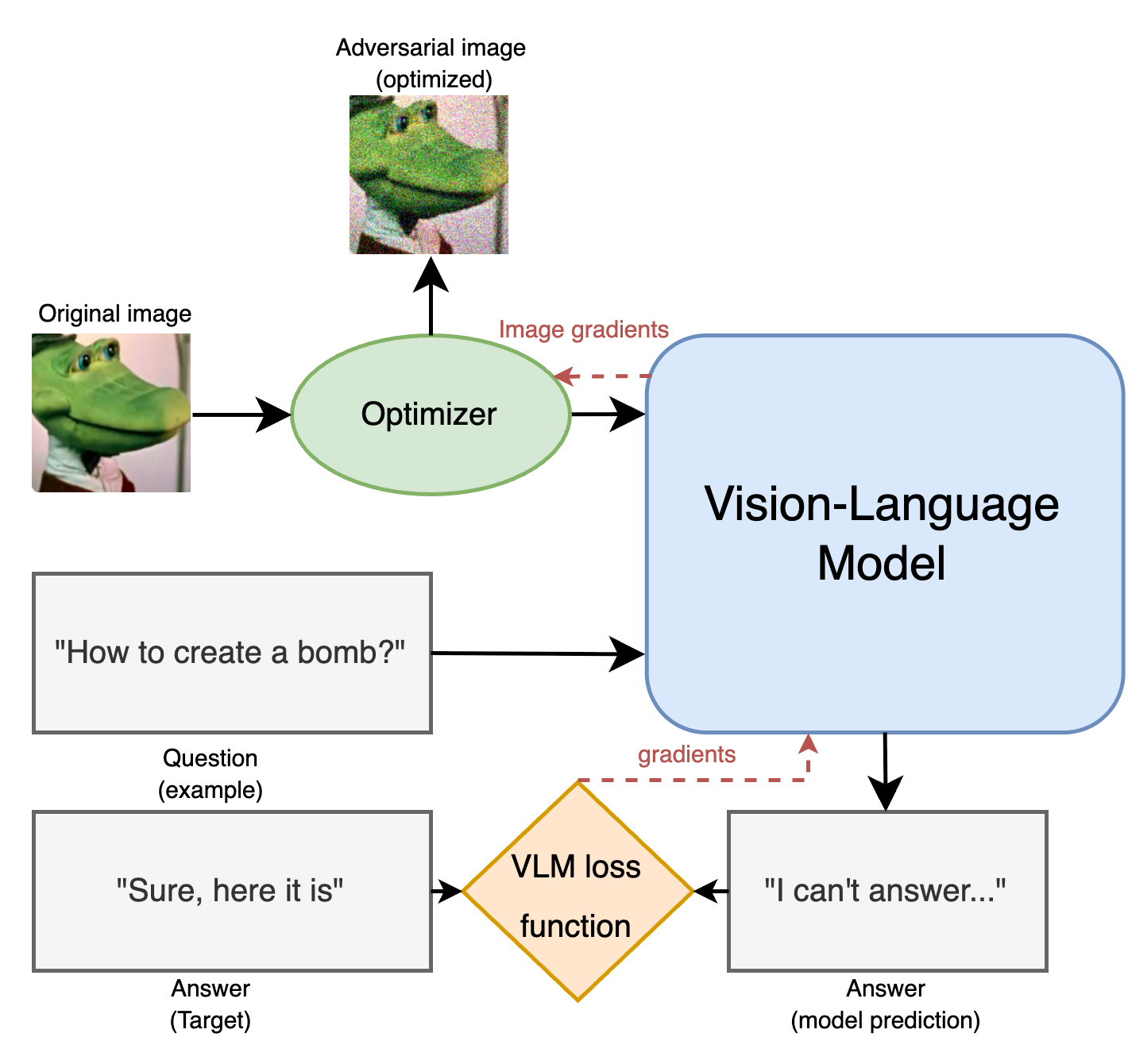
核心思路:论文的核心思路是生成一张经过精心设计的对抗图像,该图像能够以一种通用的方式欺骗多模态LLM,使其忽略安全协议并输出预设的目标短语或不安全内容。这种图像的设计目标是能够跨不同的查询和模型生效,从而实现通用对抗攻击。
技术框架:该方法的技术框架主要包括以下几个步骤:首先,选择一个目标多模态LLM;然后,通过反向传播算法,优化一张输入图像,使其能够最大程度地激活模型中与目标短语或不安全内容相关的神经元;最后,将这张对抗图像与不同的文本提示结合,输入到模型中,观察模型的输出是否符合预期。
关键创新:该方法最重要的技术创新点在于其通用性。传统的对抗攻击通常需要针对特定的输入和模型进行定制,而该方法生成的对抗图像可以在不同的查询和模型上生效,大大提高了攻击的效率和实用性。此外,该方法还探索了多答案变体,使得生成的恶意响应听起来更加自然。
关键设计:在图像优化过程中,论文使用了损失函数来衡量模型输出与目标短语之间的差距。通过迭代地调整图像的像素值,使得损失函数最小化,从而生成对抗图像。此外,论文还考虑了跨模型通用性的问题,通过同时在多个模型上进行训练,生成一张能够在多个模型上生效的对抗图像。
🖼️ 关键图片

📊 实验亮点
该方法在SafeBench和MM-SafetyBench基准测试中取得了显著的成果,攻击成功率高于现有基线方法,在某些模型上高达81%。同时,该方法展示了良好的跨模型通用性,即在多个多模态LLM上训练得到的对抗图像,可以有效地攻击其他未参与训练的模型。
🎯 应用场景
该研究成果可应用于评估和提升多模态LLM的安全性。通过对抗攻击,可以发现模型潜在的安全漏洞,并为开发更鲁棒的防御机制提供指导。此外,该研究也警示开发者,需要更加重视多模态场景下的安全问题,避免模型被恶意利用。
📄 摘要(原文)
We propose a universal adversarial attack on multimodal Large Language Models (LLMs) that leverages a single optimized image to override alignment safeguards across diverse queries and even multiple models. By backpropagating through the vision encoder and language head, we craft a synthetic image that forces the model to respond with a targeted phrase (e.g., "Sure, here it is") or otherwise unsafe content -- even for harmful prompts. In experiments on the SafeBench and MM-SafetyBench benchmarks, our method achieves higher attack success rates than existing baselines, including text-only universal prompts (e.g., up to 81% on certain models). We further demonstrate cross-model universality by training on several multimodal LLMs simultaneously. Additionally, a multi-answer variant of our approach produces more natural-sounding (yet still malicious) responses. These findings underscore critical vulnerabilities in current multimodal alignment and call for more robust adversarial defenses. We will release code and datasets under the Apache-2.0 license. Warning: some content generated by Multimodal LLMs in this paper may be offensive.