On the Convergence and Stability of Upside-Down Reinforcement Learning, Goal-Conditioned Supervised Learning, and Online Decision Transformers
作者: Miroslav Štrupl, Oleg Szehr, Francesco Faccio, Dylan R. Ashley, Rupesh Kumar Srivastava, Jürgen Schmidhuber
分类: stat.ML, cs.AI, cs.LG, cs.NE, eess.SY
发布日期: 2025-02-08 (更新: 2025-11-11)
备注: 85 pages in main text + 4 pages of references + 26 pages of appendices, 12 figures in main text + 2 figures in appendices; source code available at https://github.com/struplm/eUDRL-GCSL-ODT-Convergence-public
💡 一句话要点
分析倒置强化学习、目标条件监督学习和在线决策Transformer的收敛性和稳定性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 收敛性分析 稳定性分析 监督学习 决策Transformer 转移核 马尔可夫决策过程
📋 核心要点
- 现有倒置强化学习等算法在多种任务中表现出色,但缺乏严格的理论分析,尤其是在收敛性和稳定性方面。
- 该论文通过分析底层环境条件,研究算法识别最优解的能力,并评估其在噪声环境下的稳定性。
- 论文证明,当转移核接近确定性核时,算法能实现近优行为,并给出了策略和值的收敛性和稳定性的显式估计。
📝 摘要(中文)
本文对情景倒置强化学习、目标条件监督学习和在线决策Transformer的收敛性和稳定性进行了严格的分析。这些算法在从游戏到机器人任务的各种基准测试中表现出竞争力,但对其理论理解仅限于特定的环境条件。这项工作为通过监督学习或序列建模来解决强化学习的广泛范例的算法奠定了理论基础。这项研究的核心在于分析底层环境的条件,在该条件下,算法可以识别最优解。我们还评估了在环境受到微小噪声影响的情况下,新兴解决方案是否保持稳定。具体来说,我们研究了命令条件策略、值和目标到达目标(goal-reaching objective)的连续性和渐近收敛性,这取决于底层马尔可夫决策过程的转移核。我们证明,如果转移核位于确定性核的足够小的邻域内,则可以实现接近最优的行为。所提到的量在确定性核处是连续的(相对于特定拓扑),无论是渐近地还是在有限数量的学习周期之后。所开发的方法使我们能够给出策略和值在底层转移核方面的收敛性和稳定性的第一个显式估计。在理论方面,我们向强化学习引入了许多新概念,例如在段空间中工作、研究商拓扑中的连续性以及动力系统的定点理论的应用。理论研究伴随着对示例环境和数值实验的详细调查。
🔬 方法详解
问题定义:现有基于监督学习或序列建模的强化学习算法,如倒置强化学习、目标条件监督学习和在线决策Transformer,虽然在实践中表现良好,但缺乏对其收敛性和稳定性的理论保证。尤其是在环境存在噪声的情况下,算法能否稳定地学习到最优策略是一个关键问题。
核心思路:论文的核心思路是将强化学习问题转化为监督学习或序列建模问题,并分析在何种环境条件下,这些算法能够收敛到最优解,并且在环境存在微小扰动时保持稳定。通过研究转移核的性质,建立策略、值函数和环境之间的联系,从而分析算法的收敛性和稳定性。
技术框架:论文主要研究了命令条件策略、值函数和目标到达目标(goal-reaching objective)的连续性和渐近收敛性,这些性质都依赖于底层马尔可夫决策过程的转移核。论文分析了当转移核位于确定性核的邻域内时,算法的性能表现。整体框架可以概括为:定义环境的转移核 -> 分析转移核的性质 -> 建立策略、值函数和转移核之间的关系 -> 推导收敛性和稳定性的条件。
关键创新:论文最重要的技术创新在于建立了强化学习算法收敛性和稳定性分析的理论框架,并首次给出了策略和值函数在底层转移核方面的收敛性和稳定性的显式估计。此外,论文还引入了段空间、商拓扑中的连续性以及动力系统定点理论等新概念到强化学习领域。
关键设计:论文的关键设计在于对转移核的分析,特别是研究了转移核与确定性核的接近程度如何影响算法的性能。论文还使用了特定的拓扑结构来分析策略和值函数的连续性。此外,论文还通过数值实验验证了理论分析的有效性。
🖼️ 关键图片
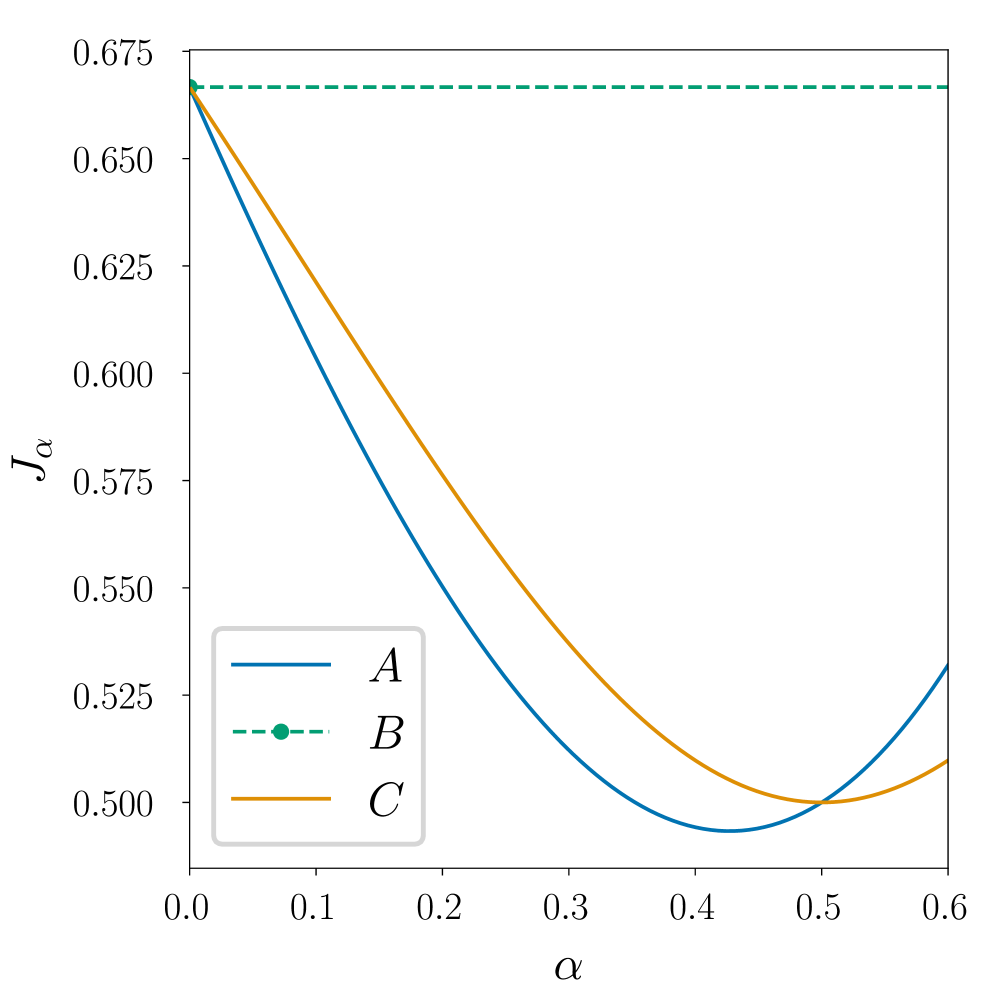
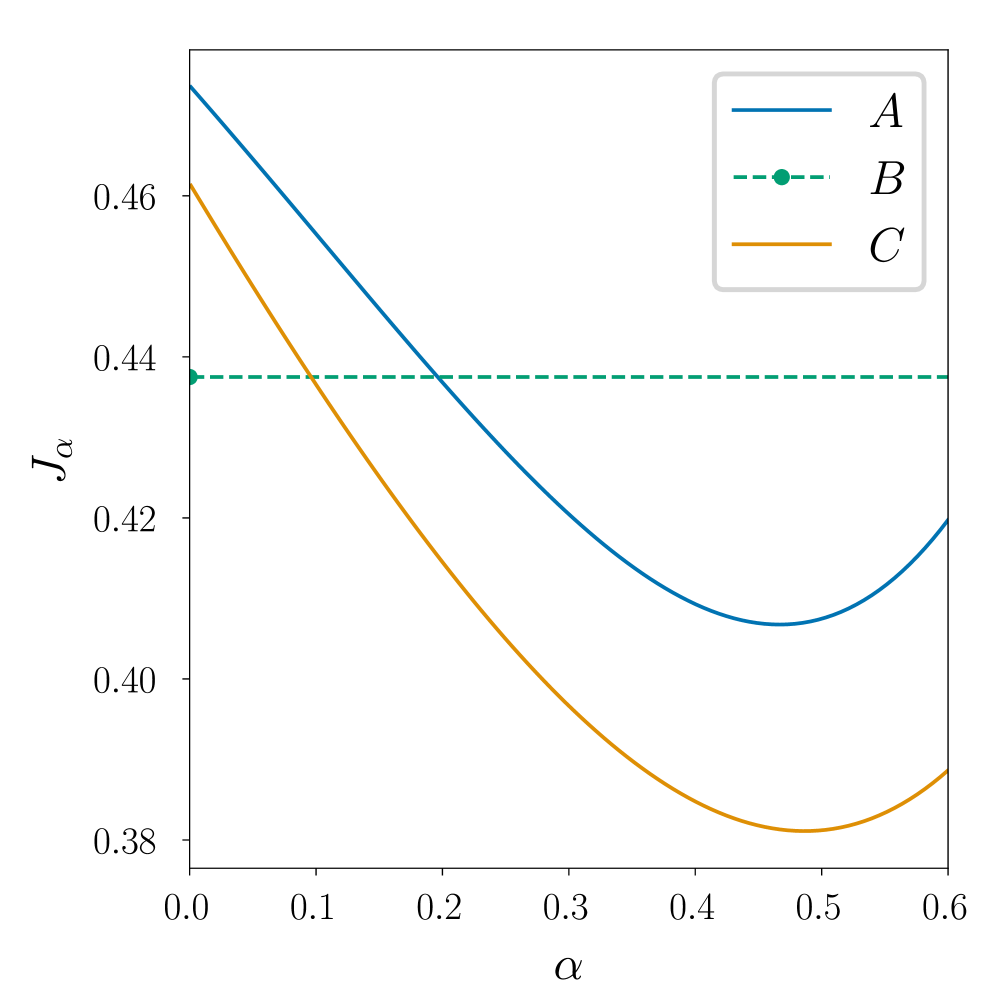
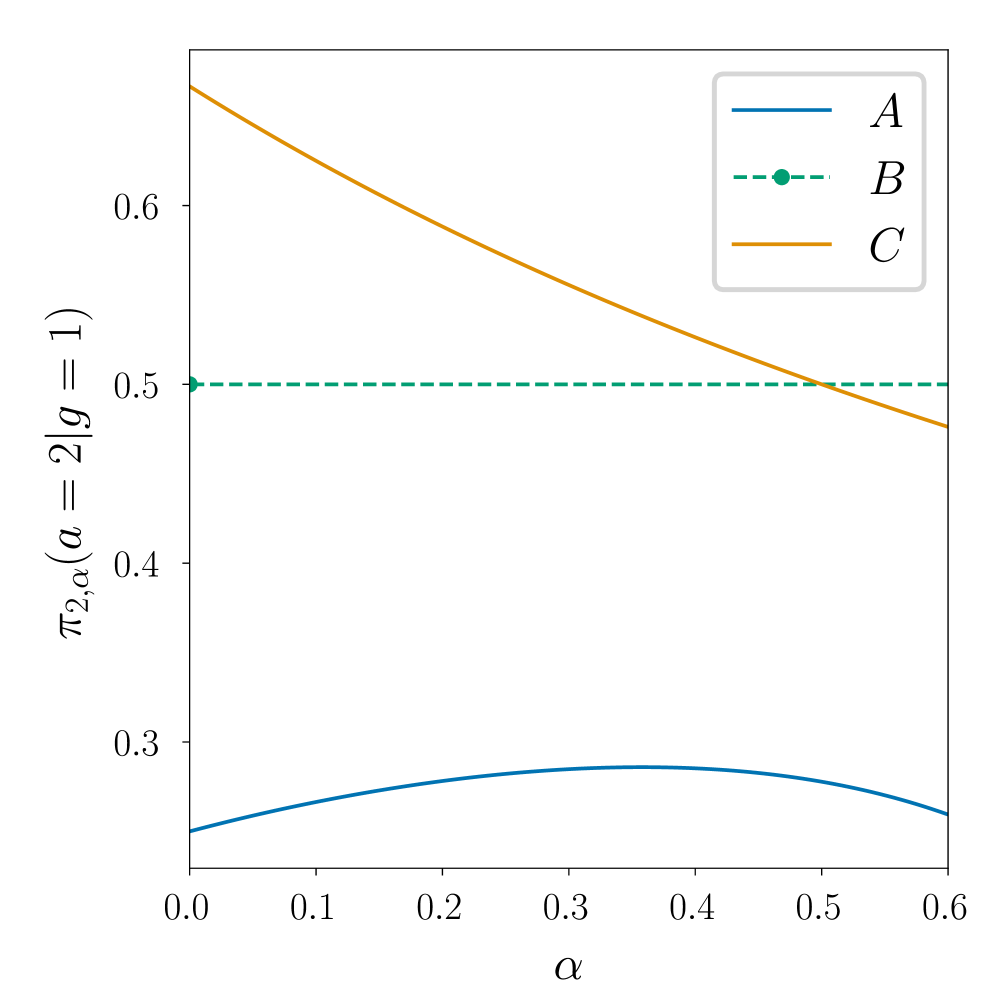
📊 实验亮点
论文证明了当转移核位于确定性核的足够小的邻域内时,算法可以实现接近最优的行为。此外,论文还给出了策略和值函数在底层转移核方面的收敛性和稳定性的第一个显式估计。数值实验验证了理论分析的有效性,为相关算法的实际应用提供了理论支撑。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、自动驾驶等领域,为这些领域中基于监督学习或序列建模的强化学习算法的可靠性和安全性提供理论保障。通过分析环境的转移核,可以更好地设计和优化算法,提高其在复杂和不确定环境中的性能。
📄 摘要(原文)
This article provides a rigorous analysis of convergence and stability of Episodic Upside-Down Reinforcement Learning, Goal-Conditioned Supervised Learning and Online Decision Transformers. These algorithms performed competitively across various benchmarks, from games to robotic tasks, but their theoretical understanding is limited to specific environmental conditions. This work initiates a theoretical foundation for algorithms that build on the broad paradigm of approaching reinforcement learning through supervised learning or sequence modeling. At the core of this investigation lies the analysis of conditions on the underlying environment, under which the algorithms can identify optimal solutions. We also assess whether emerging solutions remain stable in situations where the environment is subject to tiny levels of noise. Specifically, we study the continuity and asymptotic convergence of command-conditioned policies, values and the goal-reaching objective depending on the transition kernel of the underlying Markov Decision Process. We demonstrate that near-optimal behavior is achieved if the transition kernel is located in a sufficiently small neighborhood of a deterministic kernel. The mentioned quantities are continuous (with respect to a specific topology) at deterministic kernels, both asymptotically and after a finite number of learning cycles. The developed methods allow us to present the first explicit estimates on the convergence and stability of policies and values in terms of the underlying transition kernels. On the theoretical side we introduce a number of new concepts to reinforcement learning, like working in segment spaces, studying continuity in quotient topologies and the application of the fixed-point theory of dynamical systems. The theoretical study is accompanied by a detailed investigation of example environments and numerical experiments.