Koel-TTS: Enhancing LLM based Speech Generation with Preference Alignment and Classifier Free Guidance
作者: Shehzeen Hussain, Paarth Neekhara, Xuesong Yang, Edresson Casanova, Subhankar Ghosh, Mikyas T. Desta, Roy Fejgin, Rafael Valle, Jason Li
分类: cs.SD, cs.AI, cs.LG, eess.AS
发布日期: 2025-02-07 (更新: 2025-07-22)
期刊: ICML Workshop on Machine Learning for Audio, 2025
💡 一句话要点
Koel-TTS:通过偏好对齐和无分类器指导增强基于LLM的语音生成
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 语音合成 文本转语音 Transformer 偏好对齐 无分类器指导 说话人验证 自动语音识别
📋 核心要点
- 自回归语音生成模型缺乏可控性,易产生幻觉和不符合输入的语音。
- Koel-TTS利用偏好对齐技术(基于ASR和说话人验证)和无分类器指导来提升可控性。
- 实验表明,Koel-TTS在说话人相似度、可懂性和自然度上优于SOTA模型,且训练数据更少。
📝 摘要(中文)
本文提出Koel-TTS,一套增强的encoder-decoder Transformer TTS模型,通过结合自动语音识别和说话人验证模型指导的偏好对齐技术,解决自回归语音token生成模型在可控性方面的挑战,例如幻觉和不符合条件输入的非期望发声。此外,我们采用无分类器指导,进一步提高合成语音对文本和参考说话人音频的依从性。实验结果表明,这些优化显著提高了合成语音的目标说话人相似度、可懂性和自然度。值得注意的是,Koel-TTS直接将文本和上下文音频映射到声学token,并在上述指标上优于最先进的TTS模型,尽管训练数据集规模明显更小。
🔬 方法详解
问题定义:现有的自回归语音token生成模型虽然在语音的多样性和自然度方面表现出色,但缺乏足够的可控性。这导致模型容易产生幻觉,或者生成不符合文本转录和参考说话人音频信息的语音,例如生成与文本内容无关的声音或模仿出错误的说话人。
核心思路:Koel-TTS的核心思路是通过引入偏好对齐和无分类器指导来增强模型的可控性。偏好对齐利用自动语音识别(ASR)和说话人验证(SV)模型作为指导,使生成的语音更符合文本转录和参考说话人的特征。无分类器指导则进一步增强了模型对输入条件的依从性。
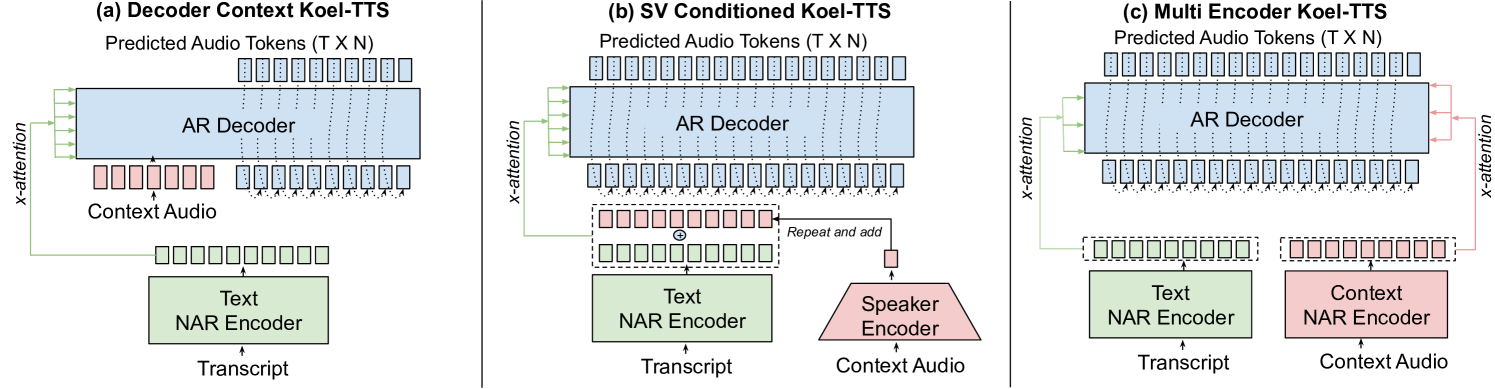
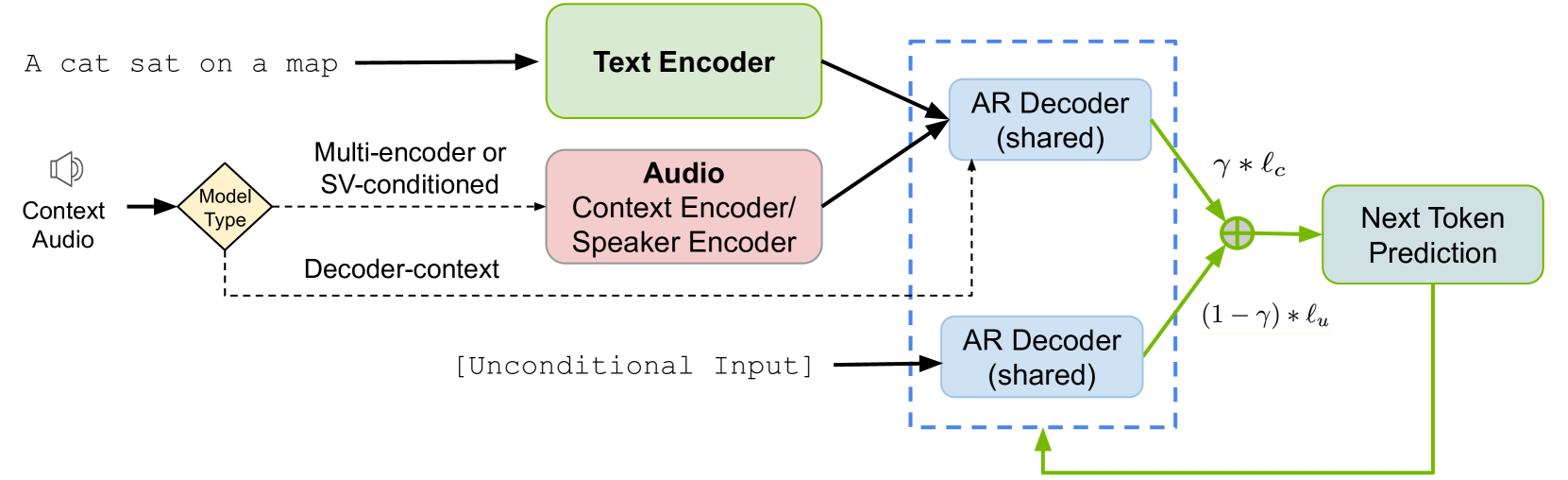
技术框架:Koel-TTS采用encoder-decoder Transformer架构。Encoder负责将文本和参考音频编码成隐藏表示,Decoder则基于这些隐藏表示生成声学token。偏好对齐模块在训练过程中利用ASR和SV模型的输出作为奖励信号,引导模型生成更符合期望的语音。无分类器指导则通过在训练过程中随机丢弃条件信息(文本或参考音频),迫使模型学习在缺少部分信息的情况下也能生成高质量的语音。
关键创新:Koel-TTS的关键创新在于将偏好对齐和无分类器指导有效地结合到TTS模型中。偏好对齐利用外部模型(ASR和SV)的知识来指导语音生成,而无分类器指导则增强了模型的鲁棒性和对输入条件的依从性。此外,Koel-TTS直接将文本和上下文音频映射到声学token,避免了中间表示的引入,简化了模型结构。
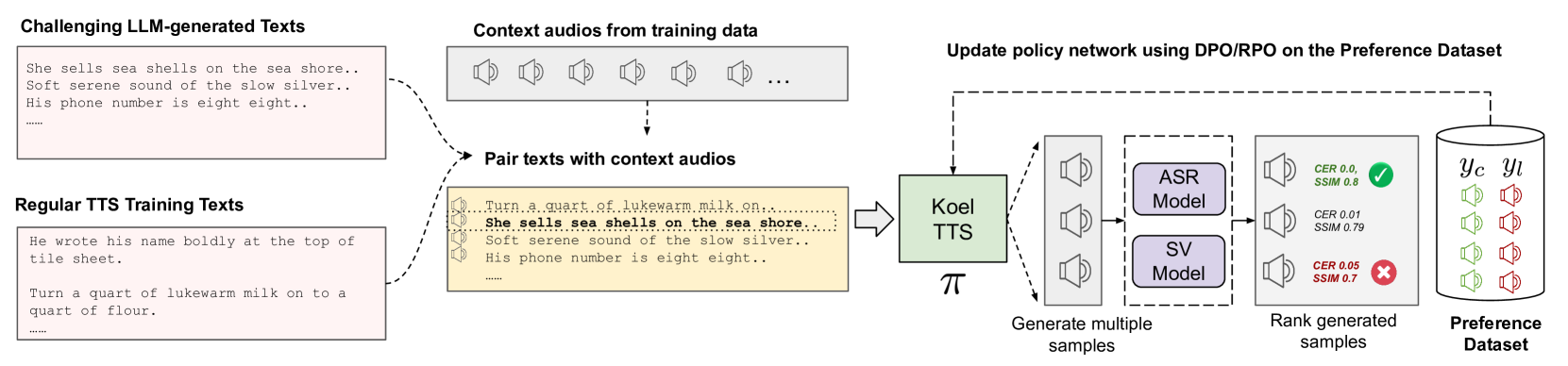
关键设计:Koel-TTS的偏好对齐模块使用ASR和SV模型的输出作为奖励信号,通过强化学习的方式训练模型。奖励函数的设计需要仔细考虑,以平衡文本转录的准确性和说话人相似度。无分类器指导的实现方式是在训练过程中以一定的概率随机丢弃文本或参考音频,并使用相同的模型进行训练。这个概率是一个重要的超参数,需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
Koel-TTS在目标说话人相似度、可懂性和自然度等指标上均优于当前最先进的TTS模型,即使在更小的数据集上训练也能取得更好的效果。这表明偏好对齐和无分类器指导能够有效地提升TTS模型的性能,并降低对大规模数据集的依赖。
🎯 应用场景
Koel-TTS可应用于语音助手、游戏角色配音、有声读物制作等领域。其提升的可控性和生成质量,使得语音合成更加逼真自然,并能更好地满足特定应用场景的需求。未来,该技术有望在个性化语音合成、跨语种语音合成等方面发挥更大的作用。
📄 摘要(原文)
While autoregressive speech token generation models produce speech with remarkable variety and naturalness, their inherent lack of controllability often results in issues such as hallucinations and undesired vocalizations that do not conform to conditioning inputs. We introduce Koel-TTS, a suite of enhanced encoder-decoder Transformer TTS models that address these challenges by incorporating preference alignment techniques guided by automatic speech recognition and speaker verification models. Additionally, we incorporate classifier-free guidance to further improve synthesis adherence to the transcript and reference speaker audio. Our experiments demonstrate that these optimizations significantly enhance target speaker similarity, intelligibility, and naturalness of synthesized speech. Notably, Koel-TTS directly maps text and context audio to acoustic tokens, and on the aforementioned metrics, outperforms state-of-the-art TTS models, despite being trained on a significantly smaller dataset. Audio samples and demos are available on our website.