Redistributing Rewards Across Time and Agents for Multi-Agent Reinforcement Learning
作者: Aditya Kapoor, Kale-ab Tessera, Mayank Baranwal, Harshad Khadilkar, Jan Peters, Stefano Albrecht, Mingfei Sun
分类: cs.MA, cs.AI, cs.LG, cs.RO
发布日期: 2025-02-07 (更新: 2025-10-29)
备注: 16 pages, 4 figures, 4 tables
💡 一句话要点
提出TAR²以解决多智能体强化学习中的奖励分配问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 信用分配 奖励重分配 潜在基础奖励塑形 神经网络 协作任务 学习加速
📋 核心要点
- 信用分配是合作多智能体强化学习中的核心挑战,现有方法依赖于模型的回归准确性,导致不可靠性。
- 本文提出的TAR²方法通过神经网络学习贡献分数,并通过确定性步骤确保回报等价性,从而解耦信用建模与约束。
- 在SMACLite和Google Research Football基准测试中,TAR²显著加速学习并超越了多个强基线,展示了其有效性。
📝 摘要(中文)
在合作多智能体强化学习(MARL)中,信用分配,即解耦每个智能体对共享奖励的贡献,是一项关键挑战。现有方法通常依赖于学习模型的回归准确性,导致其在实践中不可靠。本文提出了时间-智能体奖励重分配(TAR²)方法,该方法将信用建模与回报等价性约束解耦。通过神经网络学习未归一化的贡献分数,并通过一个确定性的归一化步骤确保回报等价性。我们证明该方法等价于有效的潜在基础奖励塑形(PBRS),保证了最优策略的保留。实验证明,TAR²在SMACLite和Google Research Football基准测试中加速学习并实现了高于强基线的最终性能。
🔬 方法详解
问题定义:本文解决的是多智能体强化学习中的信用分配问题,现有方法往往依赖于学习模型的回归准确性,导致在实际应用中表现不佳。
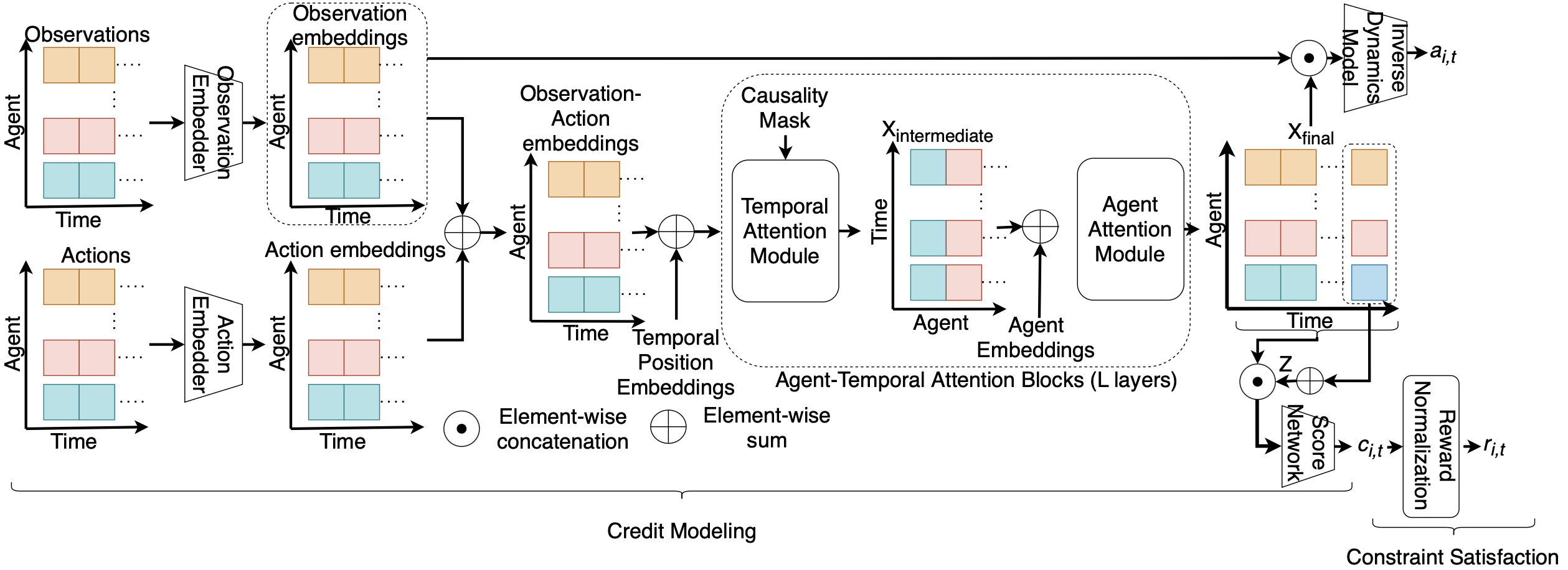
核心思路:TAR²方法通过将信用建模与回报等价性约束解耦,采用神经网络学习未归一化的贡献分数,并通过后续的归一化步骤确保回报等价性,从而提高了方法的可靠性。
技术框架:整体架构包括两个主要模块:第一部分是神经网络,用于学习每个智能体的贡献分数;第二部分是一个确定性的归一化步骤,确保所有智能体的分配奖励总和等于团队奖励。
关键创新:TAR²的创新在于其将信用建模与回报等价性解耦,使得方法不再依赖于模型的回归准确性,从而在理论上保证了最优策略的保留。
关键设计:在设计中,采用了特定的损失函数来优化贡献分数的学习,并确保归一化步骤的有效性。此外,网络结构经过精心设计,以提高学习效率和最终性能。
🖼️ 关键图片

📊 实验亮点
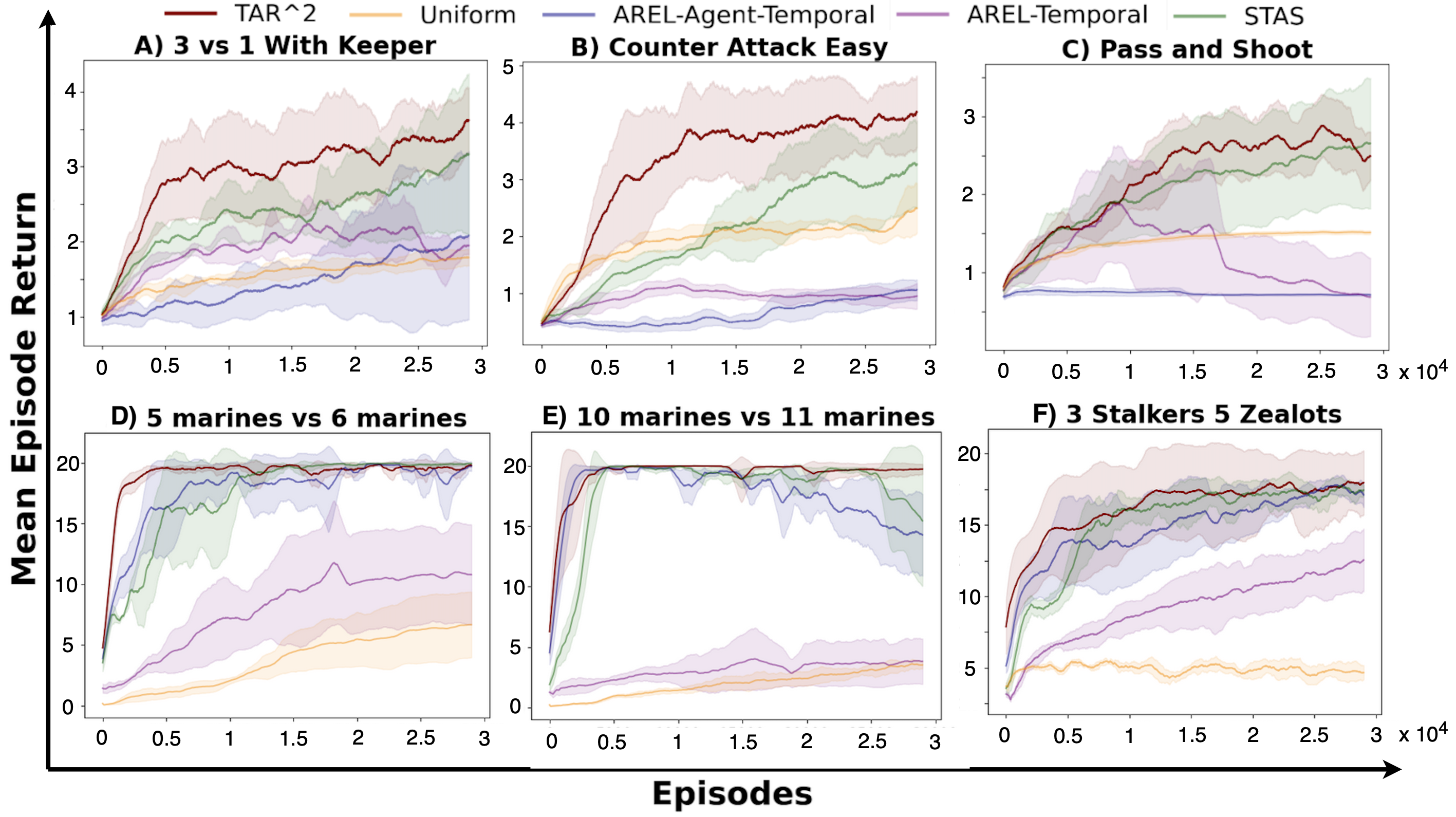
在SMACLite和Google Research Football基准测试中,TAR²方法显著加速了学习过程,并在最终性能上超越了多个强基线,展示了其在复杂环境中的有效性和优势。
🎯 应用场景
该研究的潜在应用领域包括多智能体系统中的协作任务,如机器人团队、自动驾驶车辆和智能制造等。通过有效的奖励分配机制,TAR²能够提升智能体间的协作效率,进而推动相关领域的技术进步和应用落地。
📄 摘要(原文)
Credit assignmen, disentangling each agent's contribution to a shared reward, is a critical challenge in cooperative multi-agent reinforcement learning (MARL). To be effective, credit assignment methods must preserve the environment's optimal policy. Some recent approaches attempt this by enforcing return equivalence, where the sum of distributed rewards must equal the team reward. However, their guarantees are conditional on a learned model's regression accuracy, making them unreliable in practice. We introduce Temporal-Agent Reward Redistribution (TAR$^2$), an approach that decouples credit modeling from this constraint. A neural network learns unnormalized contribution scores, while a separate, deterministic normalization step enforces return equivalence by construction. We demonstrate that this method is equivalent to a valid Potential-Based Reward Shaping (PBRS), which guarantees the optimal policy is preserved regardless of model accuracy. Empirically, on challenging SMACLite and Google Research Football (GRF) benchmarks, TAR$^2$ accelerates learning and achieves higher final performance than strong baselines. These results establish our method as an effective solution for the agent-temporal credit assignment problem.