Bridging the Gap in XAI-Why Reliable Metrics Matter for Explainability and Compliance
作者: Pratinav Seth, Vinay Kumar Sankarapu
分类: cs.AI, cs.CE, cs.ET, cs.LG
发布日期: 2025-02-07 (更新: 2025-11-20)
备注: Accepted at first EurIPS Workshop on Private AI Governance
💡 一句话要点
提出基于标准化指标的AI治理框架,提升可解释性和合规性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 可解释性AI AI治理 标准化指标 合规性 AI审计
📋 核心要点
- 现有XAI评估指标分散且易被操纵,无法有效评估AI系统的可信度和合规性。
- 提出一种基于标准化指标的AI治理框架,将可解释性评估作为核心机制,提升问责制。
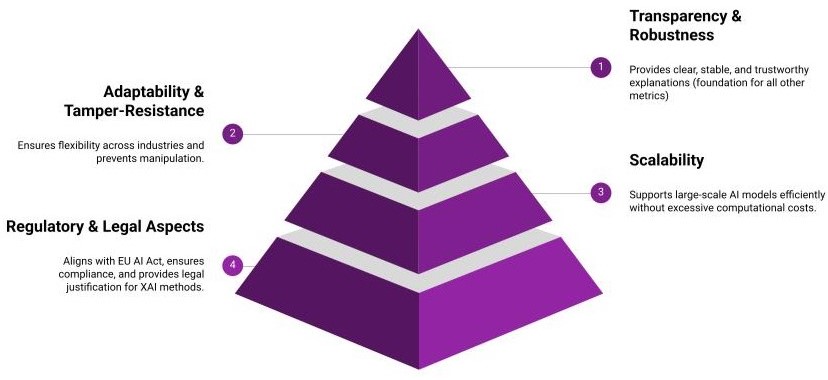
- 该框架通过分层模型,将透明度、抗篡改性、可扩展性和法律一致性联系起来,实现系统性问责。
📝 摘要(中文)
可靠的可解释性不仅是技术目标,也是私有AI治理的基石。随着AI模型进入高风险领域,审计师、保险公司、认证机构和采购机构等私有行为者需要标准化的评估指标来评估可信度。然而,当前XAI评估指标仍然分散且容易被操纵,这损害了问责制和合规性。本文认为,标准化指标可以作为治理基元,将可审计性和问责制嵌入AI系统中,以实现有效的私有监督。在XAI基准测试的基础上,本文指出了确保忠实性、抗篡改性和监管一致性的关键限制。此外,可解释性可以通过提供可验证的手段来确保通用人工智能(GPAI)系统中行为的完整性,从而直接支持模型对齐。可解释性和对齐之间的这种联系使XAI指标成为技术和监管工具,有助于防止对齐伪造。本文提出了一种“基于指标的治理”范式,将可解释性评估作为私有AI治理的核心机制。本文的框架引入了一个分层模型,将透明度、抗篡改性、可扩展性和法律一致性联系起来,从而将评估从模型内省扩展到系统性问责制。通过概念综合和与治理标准对齐,本文概述了一个将可解释性指标集成到持续AI保证管道中的路线图,以满足私有监督和监管需求。
🔬 方法详解
问题定义:当前可解释性AI(XAI)的评估指标体系存在碎片化和易被操纵的问题,导致无法有效评估AI模型的真实行为和潜在风险。这使得在高风险领域应用AI模型时,难以满足审计、合规和问责的要求。现有方法缺乏统一的标准和流程,无法保证评估结果的可靠性和一致性。
核心思路:本文的核心思路是将XAI评估指标作为一种治理工具,通过建立标准化的评估体系,将可解释性嵌入到AI系统的设计和部署过程中。通过量化和验证AI模型的行为,可以提高透明度,防止模型被恶意篡改,并确保其符合法律法规的要求。这种“基于指标的治理”范式旨在将可解释性从一种事后的解释工具转变为一种主动的治理机制。
技术框架:本文提出的治理框架是一个分层模型,包含以下几个主要层次:1. 透明度:评估模型内部机制和决策过程的可理解性。2. 抗篡改性:确保模型在部署后不会被恶意修改或攻击。3. 可扩展性:评估方法能够适应不同规模和复杂度的AI系统。4. 法律一致性:确保模型符合相关的法律法规和伦理规范。该框架旨在将这些层次整合到一个持续的AI保证管道中,实现对AI系统的全面监控和评估。
关键创新:本文最重要的技术创新在于将XAI评估指标与AI治理相结合,提出了一种新的治理范式。这种范式强调了可解释性在确保AI系统安全、可靠和负责任方面的重要性。通过建立标准化的评估体系,可以提高AI系统的透明度和可信度,促进其在高风险领域的应用。此外,该框架还强调了抗篡改性和法律一致性的重要性,旨在防止AI系统被滥用或用于非法目的。
关键设计:本文主要关注框架的设计和概念的整合,并未涉及具体的参数设置、损失函数或网络结构。关键设计在于指标体系的构建,需要选择合适的指标来量化透明度、抗篡改性、可扩展性和法律一致性。此外,还需要建立有效的评估流程,确保评估结果的可靠性和一致性。未来的研究可以进一步探索具体的指标选择和评估方法。
🖼️ 关键图片

📊 实验亮点
本文提出了一个将可解释性评估与AI治理相结合的框架,强调了标准化指标在确保AI系统安全、可靠和负责任方面的重要性。虽然没有提供具体的实验数据,但该框架为未来的研究提供了一个清晰的方向,即如何将可解释性指标集成到持续的AI保证管道中,以满足私有监督和监管需求。
🎯 应用场景
该研究成果可应用于金融、医疗、法律等高风险领域,帮助审计机构、监管部门和企业评估AI系统的可信度、合规性和安全性。通过标准化的可解释性指标,可以提高AI系统的透明度,降低潜在风险,并促进负责任的AI发展。未来,该框架有望成为AI治理的重要组成部分,为AI技术的广泛应用提供保障。
📄 摘要(原文)
Reliable explainability is not only a technical goal but also a cornerstone of private AI governance. As AI models enter high-stakes sectors, private actors such as auditors, insurers, certification bodies, and procurement agencies require standardized evaluation metrics to assess trustworthiness. However, current XAI evaluation metrics remain fragmented and prone to manipulation, which undermines accountability and compliance. We argue that standardized metrics can function as governance primitives, embedding auditability and accountability within AI systems for effective private oversight. Building upon prior work in XAI benchmarking, we identify key limitations in ensuring faithfulness, tamper resistance, and regulatory alignment. Furthermore, interpretability can directly support model alignment by providing a verifiable means of ensuring behavioral integrity in General Purpose AI (GPAI) systems. This connection between interpretability and alignment positions XAI metrics as both technical and regulatory instruments that help prevent alignment faking, a growing concern among oversight bodies. We propose a Governance by Metrics paradigm that treats explainability evaluation as a central mechanism of private AI governance. Our framework introduces a hierarchical model linking transparency, tamper resistance, scalability, and legal alignment, extending evaluation from model introspection toward systemic accountability. Through conceptual synthesis and alignment with governance standards, we outline a roadmap for integrating explainability metrics into continuous AI assurance pipelines that serve both private oversight and regulatory needs.