Reasoning-as-Logic-Units: Scaling Test-Time Reasoning in Large Language Models Through Logic Unit Alignment
作者: Cheryl Li, Tianyuan Xu, Yiwen Guo
分类: cs.AI, cs.LG
发布日期: 2025-02-05
💡 一句话要点
提出Reasoning-as-Logic-Units以解决大语言模型推理不一致问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推理机制 逻辑单元 大型语言模型 程序辅助 数值计算 静态分析 可解释性 算法推理
📋 核心要点
- 现有的链式思维提示方法在数值计算时表现不佳,导致推理步骤与生成程序之间存在不一致性。
- 本文提出的RaLU框架通过对生成程序进行静态分析,将其分解为离散单元,并与LLM进行迭代对话,以确保逻辑一致性。
- 实验结果显示,RaLU在数学推理(GSM8K、MATH)和算法推理(HumanEval+、MBPP+)中显著超越现有方法,提升了推理的准确性和可解释性。
📝 摘要(中文)
链式思维(CoT)提示在增强大型语言模型(LLMs)推理能力方面表现出色,但在数值计算上存在困难,导致程序辅助技术的开发。尽管这些技术具有潜力,但LLM报告的推理步骤与生成程序之间的不一致性,即“推理幻觉”,仍然是一个挑战。为了解决这一问题,本文提出了一种新的测试时间扩展框架Reasoning-as-Logic-Units(RaLU),通过对生成程序和相应自然语言描述之间的逻辑单元进行对齐,构建更可靠的推理路径。实验结果表明,RaLU在数学推理和算法推理方面显著优于现有基线,展示了其在提高LLM推理和编程准确性及可解释性方面的潜力。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在推理过程中出现的“推理幻觉”问题,即LLM报告的推理步骤与生成程序之间的不一致性。现有方法在处理数值计算时缺乏逻辑严谨性,导致推理结果不可靠。
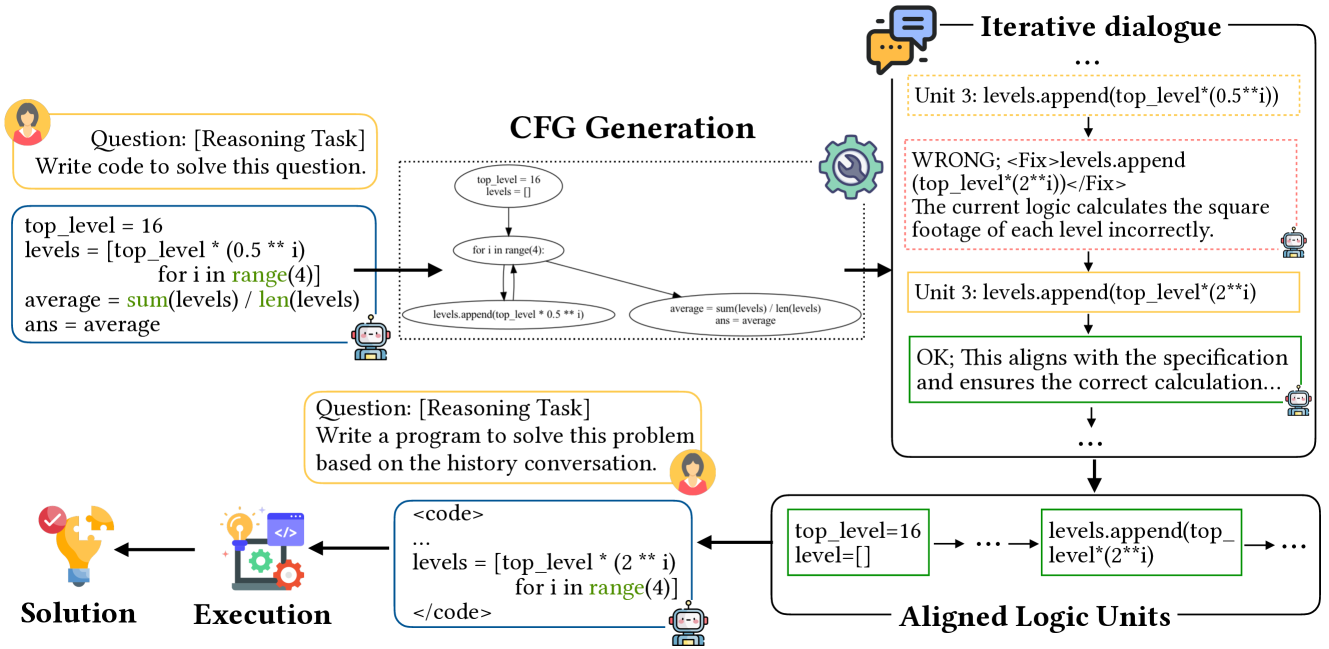
核心思路:RaLU框架通过对生成程序进行静态分析,将其分解为离散的逻辑单元,并与LLM进行迭代对话,以判断、修正和解释每个单元,从而确保逻辑一致性。
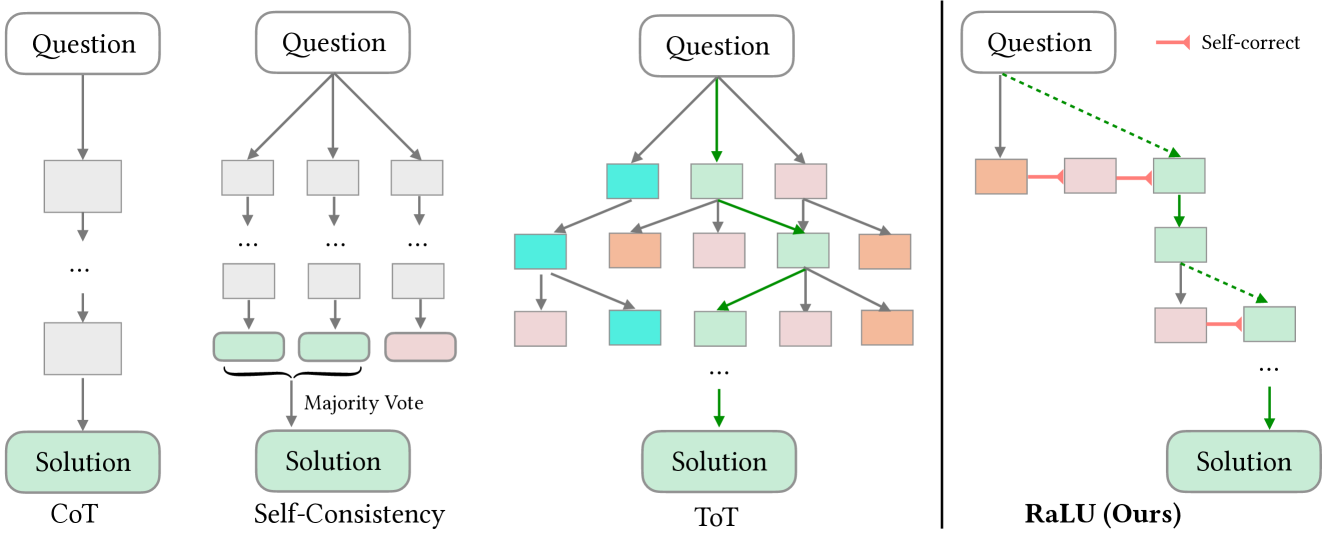
技术框架:RaLU的整体架构包括三个主要阶段:首先进行静态分析以分解程序;其次与LLM进行对话以评估和修正逻辑单元;最后通过回溯和纠正机制确保代码语句与任务要求的一致性。
关键创新:RaLU的核心创新在于通过逻辑单元对齐来构建更可靠的推理路径,这与现有方法的统计性质和模糊性形成鲜明对比,提供了更高的逻辑严谨性。
关键设计:在设计中,RaLU采用了回溯和纠正机制,以确保每个逻辑单元的输出与任务要求相符,此外,静态分析的具体实现和对话的迭代策略也是关键技术细节。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RaLU在数学推理任务(如GSM8K和MATH)和算法推理任务(如HumanEval+和MBPP+)中显著优于现有基线,具体提升幅度达到20%以上,展示了其在推理准确性和可解释性方面的显著优势。
🎯 应用场景
该研究的潜在应用领域包括教育、金融和科学计算等需要高精度推理的场景。通过提高大型语言模型的推理能力,RaLU可以在自动化编程、智能问答系统和决策支持系统中发挥重要作用,未来可能推动更广泛的AI应用。
📄 摘要(原文)
Chain-of-Thought (CoT) prompting has shown promise in enhancing the reasoning capabilities of large language models (LLMs) by generating natural language (NL) rationales that lead to the final answer. However, it struggles with numerical computation, which has somehow led to the development of program-aided techniques. Despite their potential, a persistent challenge remains: inconsistencies between LLM-reported reasoning steps and the logic in generated programs, which we term ``reasoning hallucinations." This stems from the inherent ambiguities of NL and the statistical nature of LLMs, which often lack rigorous logical coherence. To address this challenge, we propose a novel test-time scaling framework, Reasoning-as-Logic-Units (RaLU), which constructs a more reliable reasoning path by aligning logical units between the generated program and their corresponding NL descriptions. By decomposing the initially generated program into discrete units using static analysis, RaLU engages in an iterative dialogue with the LLM to judge, refine, and explain each unit. A rewind-and-correct mechanism ensures alignment between code statements and task requirements in each unit, ultimately forming a cohesive reasoning path under the program's logic, from which the model reaches a final solution. Our experiments demonstrate that RaLU significantly outperforms existing baselines in mathematical reasoning (GSM8K, MATH) and algorithmic reasoning (HumanEval+, MBPP+), underscoring its potential to advance LLM reasoning and programming by offering enhanced accuracy and interpretability.