Examining Two Hop Reasoning Through Information Content Scaling
作者: David Johnston, Nora Belrose
分类: cs.AI, cs.LG
发布日期: 2025-02-05 (更新: 2025-03-21)
💡 一句话要点
通过信息内容缩放研究Transformer在双跳推理中的能力瓶颈
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 双跳推理 Transformer 容量缩放 知识容量 问答系统
📋 核心要点
- Transformer在学习潜在双跳推理问答时表现不稳定,现有方法难以解释其根本原因。
- 通过研究模型容量随数据集规模的缩放规律,揭示双跳推理对模型知识容量的需求。
- 实验表明,潜在双跳问答需要模型重复学习事实,而思维链方法则不然,并发现小模型易陷入记忆陷阱。
📝 摘要(中文)
先前的工作表明,Transformer在学习回答潜在的双跳问题(例如“Bob的母亲的老板是谁?”)方面能力不一致。本文通过研究Transformer学习双跳问答数据集的能力如何随模型大小缩放来探究其原因,这受到了先前关于Transformer对简单事实记忆的知识容量研究的启发。研究发现,容量缩放和泛化都支持以下假设:潜在的双跳问答要求Transformer学习每个事实两次,而具有思维链的双跳问答则不需要。此外,研究表明,通过适当的数据集参数,可以将非常小的模型“困”在一种独立记忆双跳问题答案的状态,即使它们可以通过函数组合来更好地回答这些问题。研究结果表明,容量缩放的测量可以补充现有的可解释性方法,尽管将其用于此目的存在挑战。
🔬 方法详解
问题定义:论文旨在解决Transformer在处理潜在双跳推理问答时表现不一致的问题。现有方法缺乏对模型容量需求的深入理解,难以解释为何Transformer在某些情况下无法有效学习和泛化双跳推理能力。这种不一致性阻碍了Transformer在复杂推理任务中的应用。
核心思路:论文的核心思路是通过研究Transformer的容量缩放规律来理解其在双跳推理中的学习瓶颈。具体来说,通过分析模型在不同大小的数据集上的性能表现,推断双跳推理对模型知识容量的需求,并揭示模型学习过程中的潜在问题,例如记忆陷阱。
技术框架:论文采用实验驱动的方法,主要包括以下几个阶段:1)构建包含双跳问答对的数据集,并控制数据集的规模和信息内容;2)训练不同大小的Transformer模型;3)分析模型的容量缩放曲线,即模型性能随数据集规模的变化;4)设计实验来验证关于模型学习行为的假设,例如模型是否陷入记忆陷阱。
关键创新:论文的关键创新在于将容量缩放分析方法应用于研究Transformer在双跳推理中的学习行为。通过这种方法,论文揭示了潜在双跳问答需要模型重复学习事实的现象,并发现了小模型容易陷入记忆陷阱的问题。这些发现为理解Transformer的推理能力提供了新的视角。
关键设计:论文的关键设计包括:1)构建具有不同信息内容和规模的双跳问答数据集;2)使用不同大小的Transformer模型进行训练;3)采用容量缩放曲线来分析模型的学习行为;4)设计特定的实验来验证关于模型学习行为的假设,例如通过控制数据集参数来诱导模型陷入记忆陷阱。具体参数设置和损失函数等细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
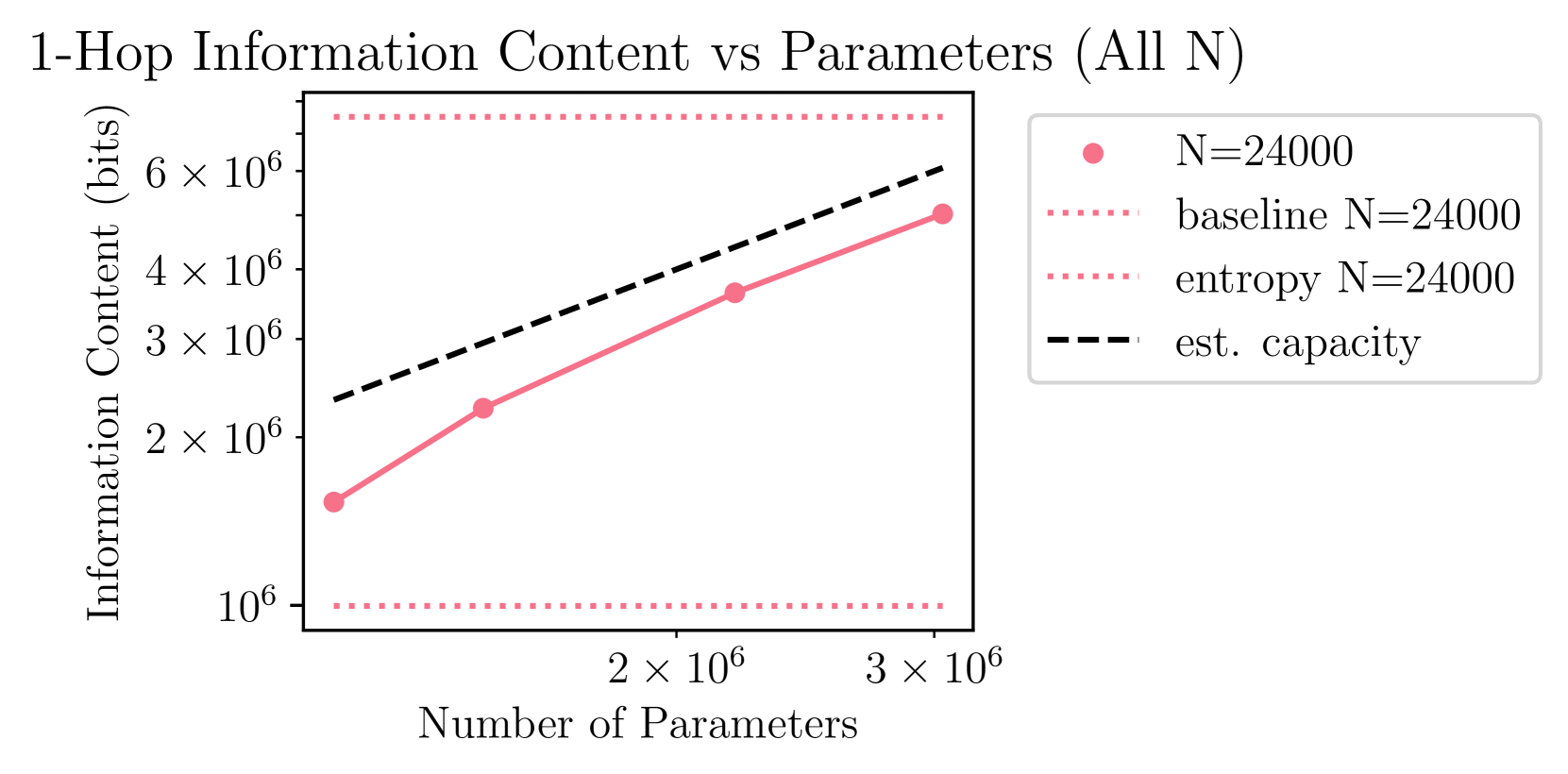
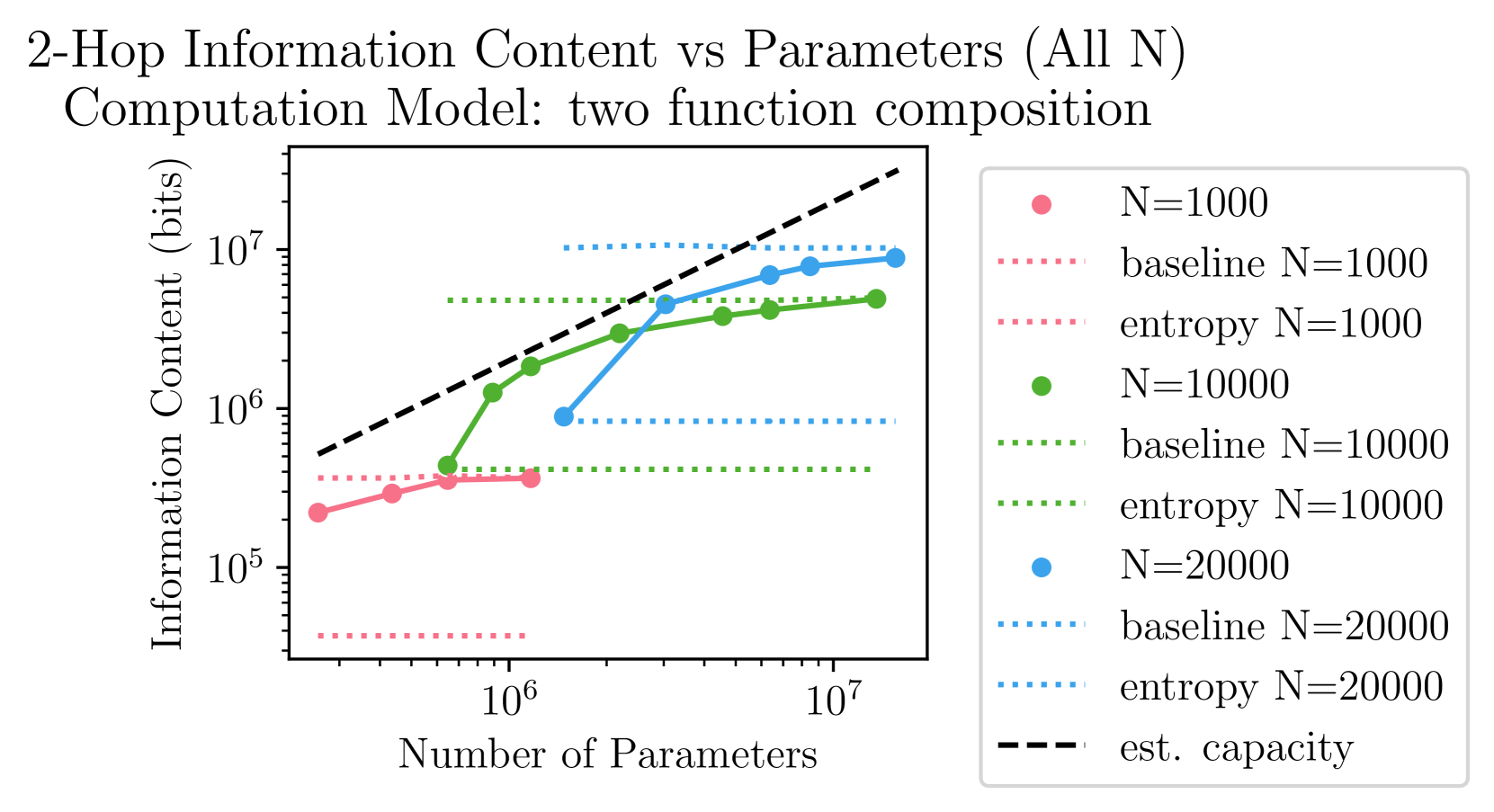
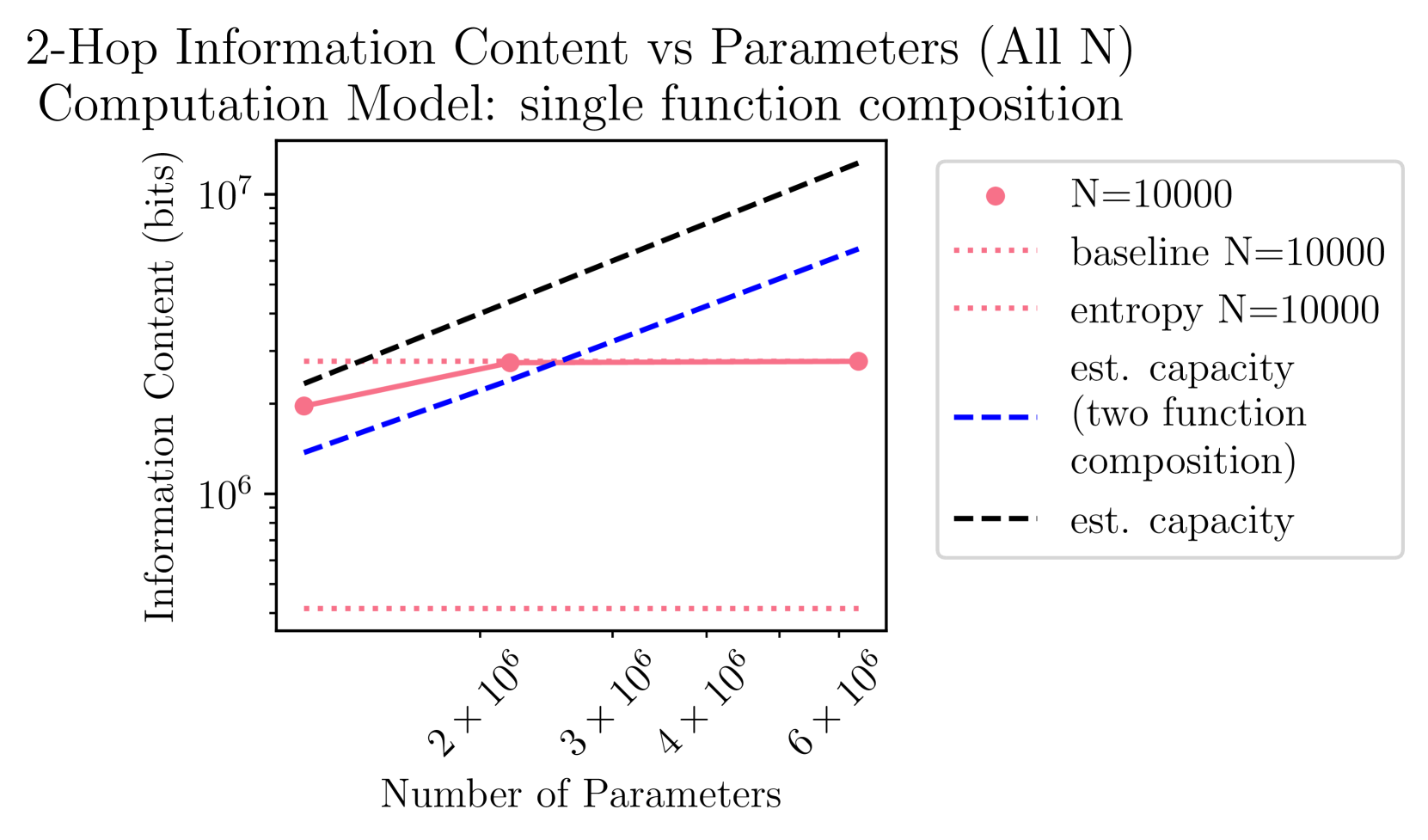
📊 实验亮点
实验结果表明,潜在双跳问答需要Transformer学习每个事实两次,而具有思维链的双跳问答则不需要。此外,研究发现,通过适当的数据集参数,可以将非常小的模型“困”在一种独立记忆双跳问题答案的状态。这些发现为理解Transformer的推理能力提供了新的视角。
🎯 应用场景
该研究成果可应用于提升Transformer在复杂推理任务中的性能,例如知识图谱问答、常识推理等。通过理解模型容量需求和避免记忆陷阱,可以设计更有效的训练策略和模型架构,从而提高Transformer在实际应用中的可靠性和泛化能力。该研究也为模型可解释性研究提供了新的思路。
📄 摘要(原文)
Prior work has found that transformers have an inconsistent ability to learn to answer latent two-hop questions -- questions of the form "Who is Bob's mother's boss?" We study why this is the case by examining how transformers' capacity to learn datasets of two-hop questions and answers (two-hop QA) scales with their size, motivated by prior work on transformer knowledge capacity for simple factual memorization. We find that capacity scaling and generalization both support the hypothesis that latent two-hop QA requires transformers to learn each fact twice, while two-hop QA with chain of thought does not. We also show that with appropriate dataset parameters, it is possible to "trap" very small models in a regime where they memorize answers to two-hop questions independently, even though they would perform better if they could learn to answer them with function composition. Our findings show that measurement of capacity scaling can complement existing interpretability methods, though there are challenges in using it for this purpose.