BFS-Prover: Scalable Best-First Tree Search for LLM-based Automatic Theorem Proving
作者: Ran Xin, Chenguang Xi, Jie Yang, Feng Chen, Hang Wu, Xia Xiao, Yifan Sun, Shen Zheng, Kai Shen
分类: cs.AI
发布日期: 2025-02-05 (更新: 2025-10-09)
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
BFS-Prover:一种可扩展的基于最佳优先树搜索的LLM自动定理证明方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动定理证明 最佳优先搜索 大型语言模型 专家迭代 直接偏好优化
📋 核心要点
- 现有自动定理证明方法依赖价值函数或MCTS,但最佳优先搜索(BFS)的潜力未被充分挖掘。
- BFS-Prover通过战略数据过滤、DPO优化和长度归一化,提升了BFS在定理证明中的性能。
- 实验表明,BFS-Prover在MiniF2F测试集上达到72.95%的SOTA分数,证明BFS的竞争力。
📝 摘要(中文)
大型语言模型(LLMs)的最新进展激发了人们对使用Lean4进行自动定理证明的兴趣,其中有效的树搜索方法对于导航潜在的大型证明搜索空间至关重要。虽然现有的方法主要依赖于价值函数和/或蒙特卡洛树搜索(MCTS),但像最佳优先树搜索(BFS)这样更简单的方法的潜力仍未被充分探索。在本文中,我们研究了BFS是否可以在大规模定理证明任务中实现有竞争力的性能。我们提出了BFS-Prover,一个可扩展的专家迭代框架,具有三个关键创新。首先,我们实施了战略性数据过滤,在每个专家迭代轮次中排除可以通过波束搜索节点扩展解决的问题,以专注于更难的案例。其次,我们通过直接偏好优化(DPO)提高了BFS的样本效率,DPO应用于自动标注了编译器错误反馈的状态-策略对,从而改进了LLM的策略以优先考虑高效的扩展。第三,我们在BFS中采用长度归一化来鼓励探索更深的证明路径。BFS-Prover在MiniF2F测试集上实现了72.95%的最先进的分数,因此挑战了对复杂树搜索方法必要性的认知,表明BFS在适当扩展时可以实现有竞争力的性能。为了促进该领域进一步的研究和开发,我们已在https://huggingface.co/ByteDance-Seed/BFS-Prover-V1-7B上开源了我们的模型。
🔬 方法详解
问题定义:论文旨在解决使用大型语言模型(LLM)进行自动定理证明时,如何在庞大的搜索空间中高效找到正确证明的问题。现有方法如基于价值函数或蒙特卡洛树搜索(MCTS)的方法虽然有效,但计算成本高昂且复杂,而更简单的最佳优先搜索(BFS)方法的潜力尚未被充分挖掘。因此,论文旨在探索BFS在自动定理证明中的性能上限,并克服其在扩展性方面的挑战。
核心思路:论文的核心思路是通过改进BFS算法,使其能够在大规模定理证明任务中达到与复杂方法相当甚至更好的性能。具体来说,通过战略性数据过滤,专注于更难的证明问题;利用直接偏好优化(DPO)提高样本效率,使LLM策略更有效;以及通过长度归一化鼓励探索更深的证明路径。这样设计的目的是在保证搜索效率的同时,提高找到正确证明的可能性。
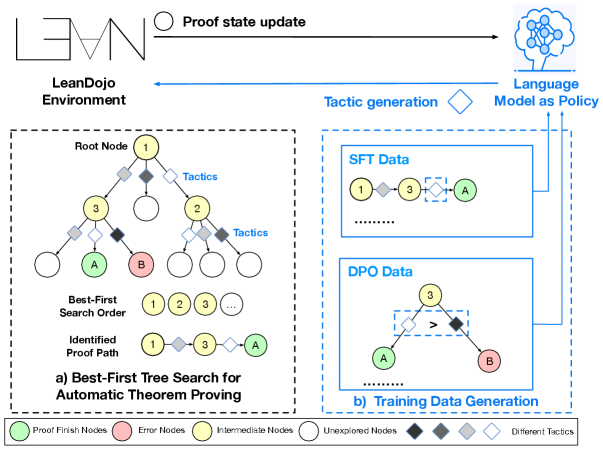
技术框架:BFS-Prover是一个专家迭代框架,主要包含以下几个阶段:1) 数据收集:使用LLM生成定理证明的候选步骤。2) 数据过滤:排除可以通过简单波束搜索解决的问题,保留更难的案例。3) 模型训练:使用DPO方法,基于编译器错误反馈优化LLM策略,鼓励生成更有效的证明步骤。4) 搜索:使用改进的BFS算法进行定理证明,包括长度归一化。5) 迭代:重复以上步骤,不断提升模型性能。
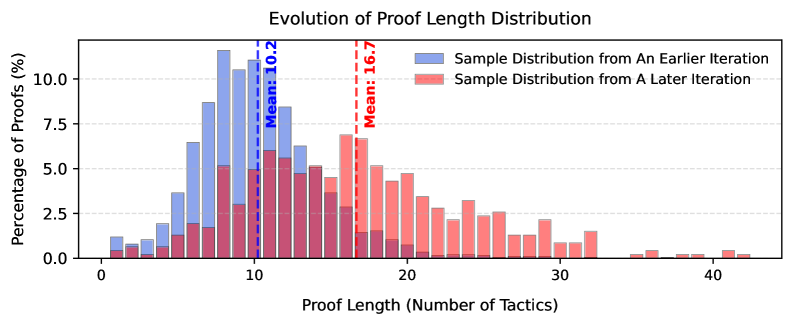
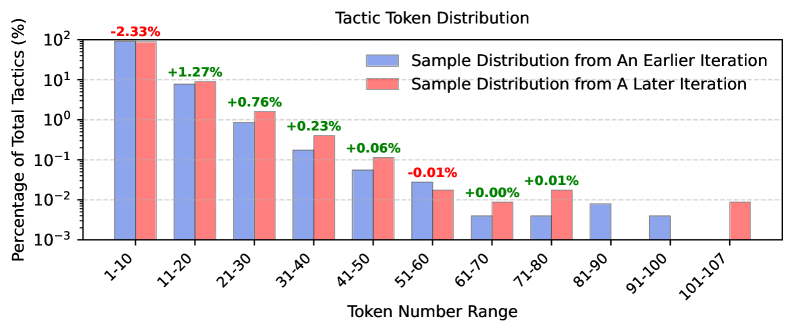
关键创新:论文的关键创新在于以下三点:1) 战略性数据过滤:通过排除简单案例,使模型专注于学习更难的证明策略。2) 基于DPO的策略优化:利用编译器错误反馈,更有效地训练LLM,提高样本效率。3) 长度归一化:鼓励BFS探索更深的证明路径,避免陷入局部最优。这些创新使得BFS能够在复杂的定理证明任务中表现出色。
关键设计:在数据过滤方面,使用波束搜索作为简单案例的判断标准,设定合适的波束宽度。在DPO训练中,使用状态-策略对作为训练数据,编译器错误反馈作为奖励信号。在BFS搜索中,长度归一化的具体实现方式未知,但其目的是平衡广度和深度搜索,避免过早停止。
🖼️ 关键图片
📊 实验亮点
BFS-Prover在MiniF2F测试集上取得了72.95%的SOTA分数,显著优于现有方法。这一结果表明,通过适当的改进和扩展,BFS可以在大规模定理证明任务中达到与复杂树搜索方法相当甚至更好的性能,挑战了以往对BFS能力的认知。
🎯 应用场景
该研究成果可应用于自动定理证明、程序验证、AI安全等领域。通过提高自动定理证明的效率和准确性,可以帮助研究人员和工程师验证软件和硬件系统的正确性,减少错误和漏洞。此外,该方法还可以用于开发更智能的AI系统,使其能够进行更复杂的推理和决策。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have spurred growing interest in automatic theorem proving using Lean4, where effective tree search methods are crucial for navigating the underlying large proof search spaces. While the existing approaches primarily rely on value functions and/or Monte Carlo Tree Search (MCTS), the potential of simpler methods like Best-First Tree Search (BFS) remains underexplored. In this paper, we investigate whether BFS can achieve competitive performance in large-scale theorem proving tasks. We present BFS-Prover, a scalable expert iteration framework, featuring three key innovations. First, we implement strategic data filtering at each expert iteration round, excluding problems solvable via beam search node expansion to focus on harder cases. Second, we improve the sample efficiency of BFS through Direct Preference Optimization (DPO) applied to state-tactic pairs automatically annotated with compiler error feedback, refining the LLM's policy to prioritize productive expansions. Third, we employ length normalization in BFS to encourage exploration of deeper proof paths. BFS-Prover achieves a state-of-the-art score of $72.95\%$ on the MiniF2F test set and therefore challenges the perceived necessity of complex tree search methods, demonstrating that BFS can achieve competitive performance when properly scaled. To facilitate further research and development in this area, we have open-sourced our model at https://huggingface.co/ByteDance-Seed/BFS-Prover-V1-7B.