Learning to Generate Unit Tests for Automated Debugging
作者: Archiki Prasad, Elias Stengel-Eskin, Justin Chih-Yao Chen, Zaid Khan, Mohit Bansal
分类: cs.SE, cs.AI, cs.CL, cs.LG
发布日期: 2025-02-03 (更新: 2025-08-21)
备注: Accepted to COLM 2025. Dataset and Code: https://github.com/archiki/UTGenDebug
💡 一句话要点
UTGen:学习生成单元测试以辅助LLM自动化调试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 单元测试生成 自动化调试 大型语言模型 代码正确性 错误揭示
📋 核心要点
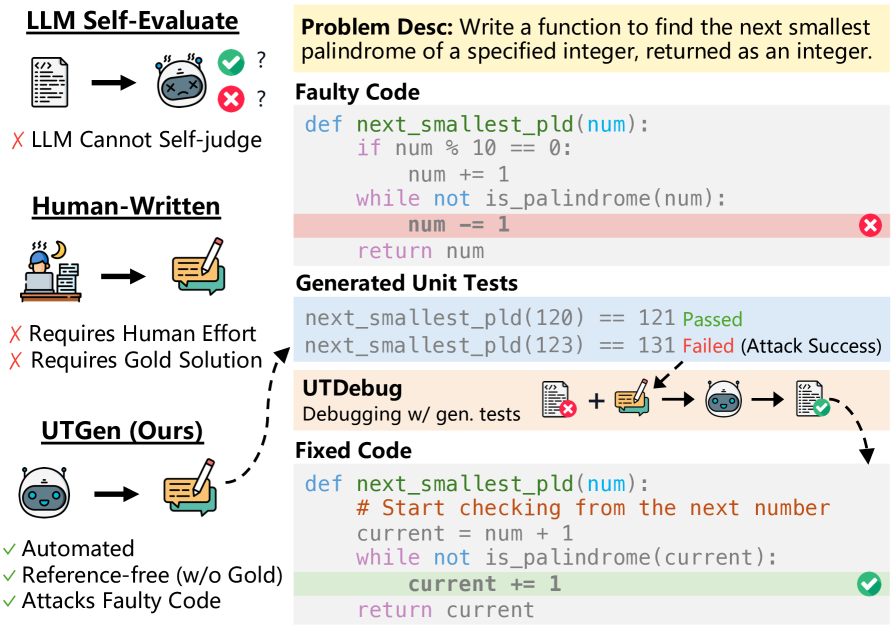
- 现有单元测试生成方法难以兼顾错误揭示和输出预测的准确性,存在trade-off。
- UTGen通过教导LLM生成既能揭示错误又能预测正确输出的单元测试输入来解决上述问题。
- UTGen结合UTDebug,显著提升了LLM在代码调试任务上的性能,并在代码正确性判断上超越了现有奖励模型。
📝 摘要(中文)
单元测试(UTs)在评估代码正确性以及为大型语言模型(LLMs)提供反馈方面发挥着重要作用,这推动了自动化测试生成的需求。然而,我们发现,在生成能够揭示错误的代码的单元测试输入与在没有黄金标准答案的情况下正确预测单元测试输出之间存在权衡。为了解决这一问题,我们提出了UTGen,它教导LLMs生成能够揭示错误的单元测试输入,以及基于任务描述的正确的预期输出。由于模型生成的测试可能提供噪声信号(例如,来自不正确预测的输出),我们提出了UTDebug,它(i)通过测试时计算来扩展UTGen,以提高UT输出预测;(ii)基于多个生成的UT验证和回溯编辑,以避免过拟合,并帮助LLMs有效地进行调试。我们表明,基于衡量错误揭示UT输入和正确UT输出的指标,UTGen优于其他基于LLM的基线7.59%。当与UTDebug一起使用时,我们发现来自UTGen的单元测试的反馈使Qwen2.5 32B在HumanEvalFix和我们自己更难的MBPP+调试分割上的pass@1准确率分别提高了3.17%和12.35%(相对于其他基于LLM的UT生成基线)。此外,我们观察到,基于Qwen2.5 32B的UTGen模型的反馈可以增强像GPT-4o这样的前沿LLMs的调试能力,提升幅度达到13.8%。最后,我们证明UTGen是代码正确性的更好判断者,在使用Qwen2.5 7B进行best-of-10抽样时,在HumanEval+上优于最先进的训练过的8B奖励模型4.43%。
🔬 方法详解
问题定义:现有单元测试生成方法在生成单元测试输入时,难以同时保证生成的测试用例能够有效地揭示代码中的错误,并准确预测在没有标准答案情况下的单元测试输出。这导致了在错误揭示能力和输出预测准确性之间的权衡,限制了自动化调试的效率和可靠性。
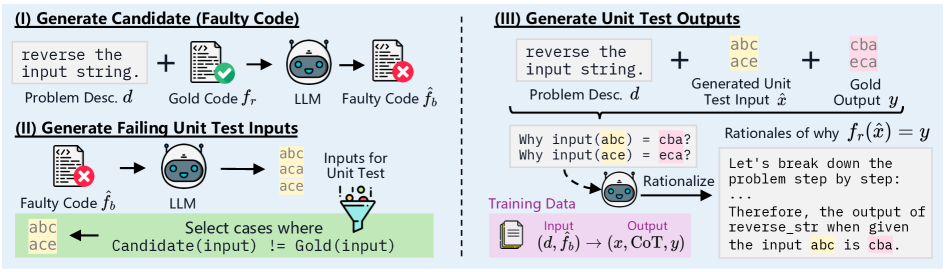
核心思路:UTGen的核心思路是训练LLM生成既能揭示错误又能预测正确输出的单元测试。通过让LLM同时学习生成能够暴露代码缺陷的输入和对应的正确输出,从而打破了错误揭示和输出预测之间的trade-off。这种方法旨在提供更全面、更可靠的单元测试,以辅助LLM进行自动化调试。
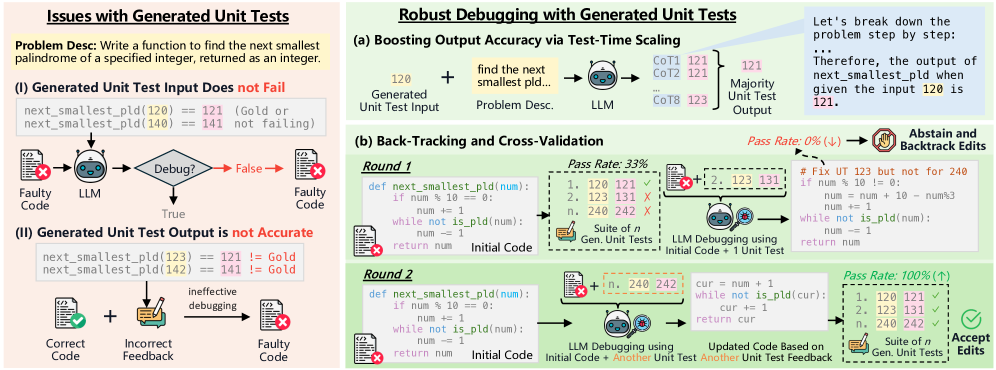
技术框架:UTGen包含两个主要模块:UTGen本身和UTDebug。UTGen负责生成单元测试输入和预期输出。UTDebug则利用UTGen生成的测试用例,通过测试时计算来提高UT输出预测的准确性,并基于多个生成的UT验证和回溯编辑,以避免过拟合。整个流程旨在利用生成的单元测试反馈来改进LLM的代码调试能力。
关键创新:UTGen的关键创新在于它能够同时生成错误揭示的单元测试输入和正确的预期输出,从而解决了现有方法中存在的trade-off。此外,UTDebug通过测试时计算和多重验证机制,进一步提高了单元测试的可靠性和有效性。
关键设计:UTGen的具体实现细节未知,但可以推测其训练过程可能涉及特殊的损失函数,以鼓励LLM生成既能揭示错误又能预测正确输出的单元测试。UTDebug可能采用了集成学习或自适应验证策略,以提高UT输出预测的准确性并避免过拟合。具体的网络结构和参数设置在论文中可能有所描述,但此处无法得知。
🖼️ 关键图片
📊 实验亮点
UTGen在HumanEvalFix和MBPP+调试分割上的pass@1准确率分别提高了3.17%和12.35%。UTGen增强了GPT-4o的调试能力,提升幅度达到13.8%。UTGen在HumanEval+上优于最先进的训练过的8B奖励模型4.43%。
🎯 应用场景
UTGen可应用于软件开发的自动化测试、代码调试和代码质量评估等领域。通过自动生成高质量的单元测试,可以帮助开发者快速发现和修复代码中的错误,提高软件的可靠性和稳定性。此外,UTGen还可以作为代码正确性的评估工具,辅助代码审查和质量控制。
📄 摘要(原文)
Unit tests (UTs) play an instrumental role in assessing code correctness as well as providing feedback to large language models (LLMs), motivating automated test generation. However, we uncover a trade-off between generating unit test inputs that reveal errors when given a faulty code and correctly predicting the unit test output without access to the gold solution. To address this trade-off, we propose UTGen, which teaches LLMs to generate unit test inputs that reveal errors along with their correct expected outputs based on task descriptions. Since model-generated tests can provide noisy signals (e.g., from incorrectly predicted outputs), we propose UTDebug that (i) scales UTGen via test-time compute to improve UT output prediction, and (ii) validates and backtracks edits based on multiple generated UTs to avoid overfitting, and helps LLMs debug effectively. We show that UTGen outperforms other LLM-based baselines by 7.59% based on a metric measuring the presence of both error-revealing UT inputs and correct UT outputs. When used with UTDebug, we find that feedback from UTGen's unit tests improves pass@1 accuracy of Qwen2.5 32B on HumanEvalFix and our own harder debugging split of MBPP+ by over 3.17% and 12.35% (respectively) over other LLM-based UT generation baselines. Moreover, we observe that feedback from Qwen2.5 32B-based UTGen model can enhance debugging with frontier LLMs like GPT-4o by 13.8%. Lastly, we demonstrate that UTGen is a better judge for code correctness, outperforming a state-of-the-art trained 8B reward model by 4.43% on HumanEval+ with best-of-10 sampling using Qwen2.5 7B.