Skewed Memorization in Large Language Models: Quantification and Decomposition
作者: Hao Li, Di Huang, Ziyu Wang, Amir M. Rahmani
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-02-03
💡 一句话要点
量化并分解大语言模型中的倾斜记忆现象,揭示其与训练数据的关系
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 记忆现象 隐私保护 监督微调 倾斜分布
📋 核心要点
- 现有LLM记忆分析侧重平均情况,忽略了记忆分布的高度倾斜性,无法有效应对隐私泄露风险。
- 论文通过分析序列长度上的记忆概率,将倾斜记忆与token生成过程关联,从而估计记忆并进行有效比较。
- 论文通过理论分析和实验验证,提出了检测和缓解记忆风险的策略,旨在提升LLM的隐私保护能力。
📝 摘要(中文)
大语言模型(LLM)中的记忆现象带来了隐私和安全风险,因为模型可能会无意中重现敏感或受版权保护的数据。现有的分析主要集中在平均情况,往往忽略了记忆的高度倾斜分布。本文研究了LLM监督微调(SFT)中的记忆现象,探讨了其与训练时长、数据集大小以及样本间相似性的关系。通过分析序列长度上的记忆概率,我们将这种倾斜与token生成过程联系起来,为估计记忆并将其与已建立的指标进行比较提供了见解。通过理论分析和实证评估,我们全面理解了记忆行为,并提出了检测和降低风险的策略,从而有助于构建更具隐私保护能力的大语言模型。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)在监督微调(SFT)过程中出现的“倾斜记忆”问题。现有方法主要关注平均情况下的记忆行为,忽略了记忆分布的高度倾斜性,导致无法准确评估和有效缓解隐私泄露风险。这种倾斜性意味着少数样本被模型过度记忆,而大多数样本则未被充分记忆,从而使得传统的平均指标难以反映真实的记忆风险。
核心思路:论文的核心思路是将倾斜记忆与token生成过程联系起来,通过分析不同序列长度上的记忆概率,揭示记忆行为的内在机制。具体来说,论文认为模型在生成token时,会受到训练数据中相似样本的影响,从而导致某些样本更容易被记忆。通过量化这种影响,可以更准确地估计记忆风险,并为缓解策略提供理论依据。
技术框架:论文的技术框架主要包括以下几个部分:1) 记忆概率分析:通过计算模型在生成特定token时,该token是否出现在训练数据中,来评估模型的记忆概率。2) 序列长度分析:分析不同序列长度上的记忆概率,揭示记忆行为与序列长度之间的关系。3) 相似性分析:分析训练数据中样本之间的相似性,探讨相似性对记忆行为的影响。4) 风险检测与缓解:基于上述分析,提出检测和缓解记忆风险的策略。
关键创新:论文的关键创新在于将倾斜记忆与token生成过程联系起来,并提出了基于序列长度分析的记忆概率估计方法。与现有方法相比,该方法能够更准确地评估记忆风险,并为缓解策略提供更有效的指导。此外,论文还深入探讨了训练数据相似性对记忆行为的影响,为理解和控制记忆现象提供了新的视角。
关键设计:论文的关键设计包括:1) 记忆概率的计算方法:采用精确匹配的方式,判断模型生成的token是否出现在训练数据中。2) 序列长度的划分:根据经验和实验结果,选择合适的序列长度范围,并进行分组分析。3) 相似性的度量:采用余弦相似度等方法,计算训练数据中样本之间的相似性。4) 风险缓解策略:提出了基于数据增强、正则化等方法的风险缓解策略,旨在降低模型的记忆能力。
🖼️ 关键图片
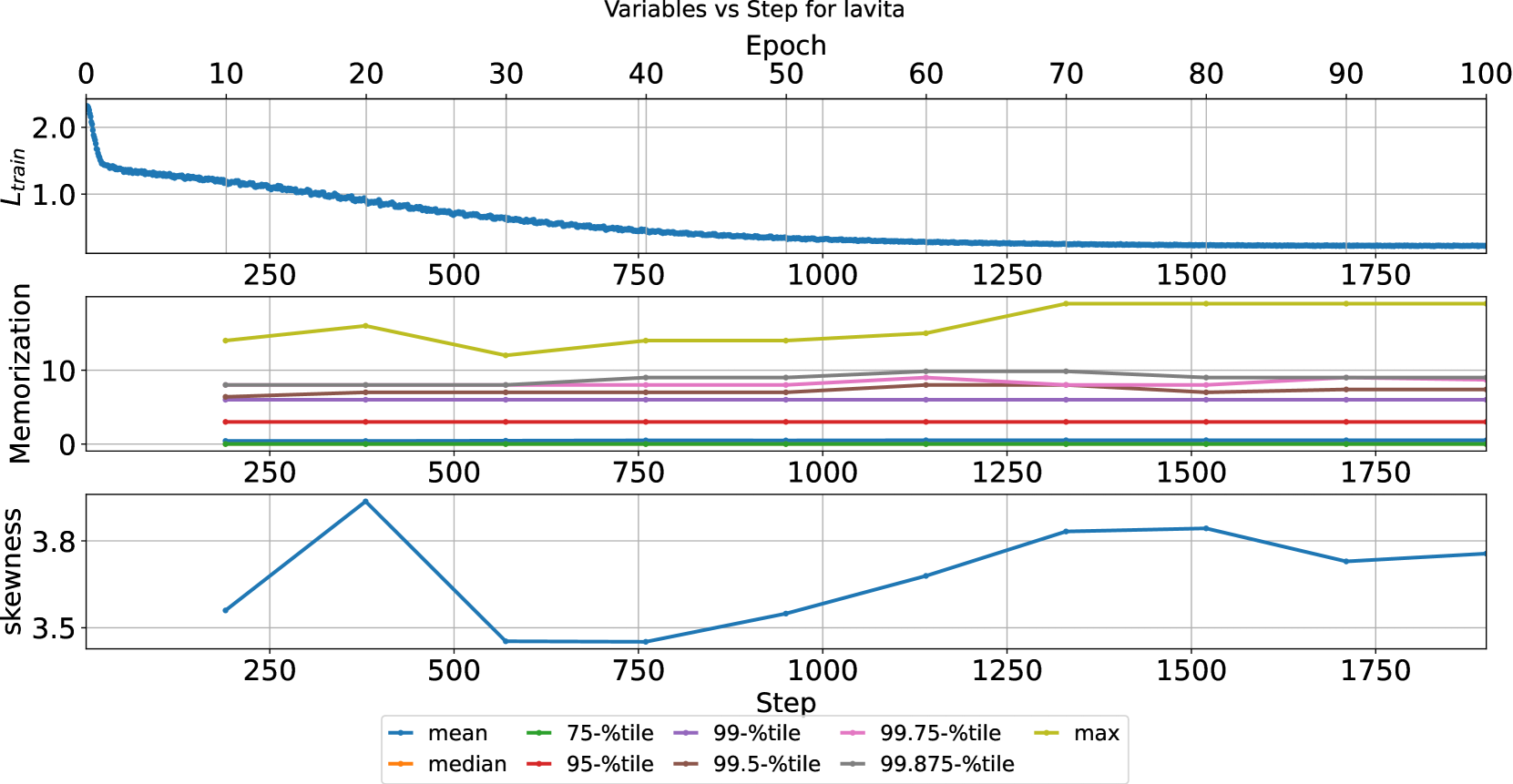
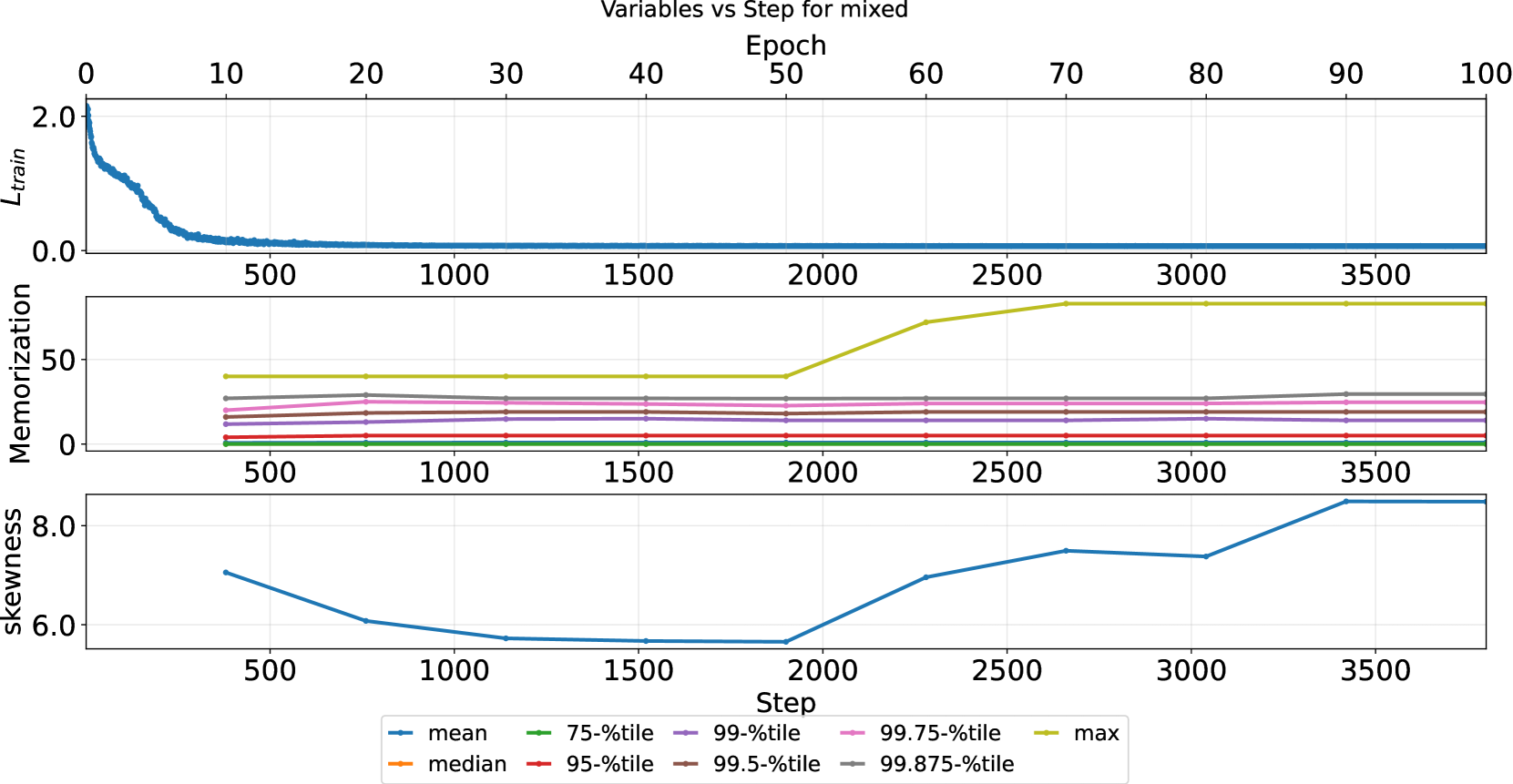
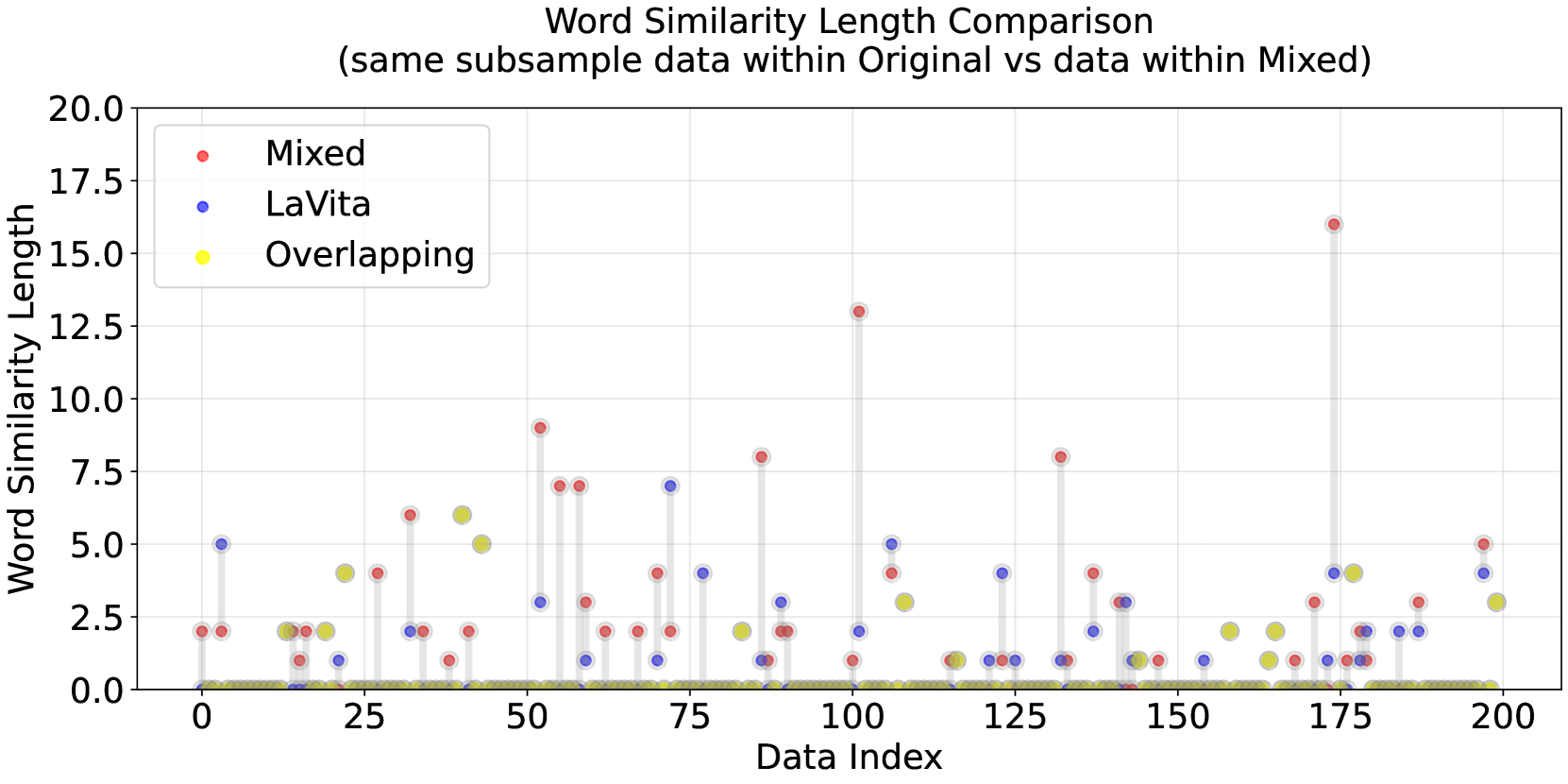
📊 实验亮点
论文通过实验验证了倾斜记忆现象的存在,并揭示了其与训练时长、数据集大小以及样本间相似性的关系。实验结果表明,随着训练时长的增加,模型的记忆能力会逐渐增强,且更容易记忆相似的样本。此外,论文还验证了基于序列长度分析的记忆概率估计方法的有效性,并证明了所提出的风险缓解策略能够有效降低模型的记忆能力。
🎯 应用场景
该研究成果可应用于提升大语言模型的隐私保护能力,降低模型泄露敏感信息的风险。例如,在医疗、金融等对数据隐私要求较高的领域,可以利用该研究成果来评估和缓解模型的记忆风险,从而确保用户数据的安全。此外,该研究还可以为模型训练过程中的数据选择和增强提供指导,从而构建更安全、可靠的大语言模型。
📄 摘要(原文)
Memorization in Large Language Models (LLMs) poses privacy and security risks, as models may unintentionally reproduce sensitive or copyrighted data. Existing analyses focus on average-case scenarios, often neglecting the highly skewed distribution of memorization. This paper examines memorization in LLM supervised fine-tuning (SFT), exploring its relationships with training duration, dataset size, and inter-sample similarity. By analyzing memorization probabilities over sequence lengths, we link this skewness to the token generation process, offering insights for estimating memorization and comparing it to established metrics. Through theoretical analysis and empirical evaluation, we provide a comprehensive understanding of memorization behaviors and propose strategies to detect and mitigate risks, contributing to more privacy-preserving LLMs.