Do LLMs Strategically Reveal, Conceal, and Infer Information? A Theoretical and Empirical Analysis in The Chameleon Game
作者: Mustafa O. Karabag, Jan Sobotka, Ufuk Topcu
分类: cs.AI, cs.GT, cs.LG
发布日期: 2025-01-31 (更新: 2025-10-20)
💡 一句话要点
通过变色龙游戏评估LLM在信息控制、推理和策略制定方面的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 信息控制 策略制定 博弈论 隐藏身份游戏
📋 核心要点
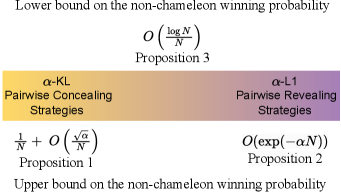
- 现有方法难以评估LLM在非合作博弈中的信息控制、策略制定和推理能力,缺乏针对性评估框架。
- 论文设计了“变色龙”游戏,要求LLM智能体在隐藏身份的同时识别对手,以此考察其信息控制能力。
- 实验表明,LLM在识别变色龙方面表现尚可,但在隐藏信息方面存在不足,且内部表征与信息揭示程度线性相关。
📝 摘要(中文)
本文研究了基于大型语言模型(LLM)的智能体在包含非合作方的环境中的信息控制和决策能力。在这种环境中,智能体需要对对手隐藏信息,向合作者揭示信息,并推断信息以识别其他智能体的特征。为了评估LLM是否具备这些能力,作者让LLM智能体玩基于语言的隐藏身份游戏“变色龙”。在这个游戏中,一群互不了解的非变色龙智能体旨在识别变色龙智能体,同时不泄露秘密。该游戏要求智能体同时具备作为变色龙和非变色龙的信息控制能力。作者首先对一系列策略(从隐藏到揭示)进行了理论分析,并提供了非变色龙获胜概率的界限。使用GPT、Gemini 2.5 Pro、Llama 3.1和Qwen3模型的实验结果表明,虽然非变色龙LLM智能体能够识别变色龙,但它们未能对变色龙隐藏秘密,并且它们的获胜概率远低于简单的策略。基于这些实验结果和理论分析,作者推断,基于LLM的智能体可能会向身份不明的智能体过度泄露信息。有趣的是,作者发现,当被指示采用信息揭示水平时,该水平线性编码在LLM的内部表示中。虽然仅靠指令通常无法使非变色龙LLM隐藏信息,但作者表明,直接以这种线性方向引导内部表示可以可靠地诱导隐藏行为。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在策略性信息控制方面的能力,具体场景设定为“变色龙”游戏。现有方法缺乏对LLM在非合作博弈中信息隐藏、信息揭示和信息推断能力的综合评估,难以量化LLM的策略性行为。
核心思路:论文的核心思路是通过设计一个语言驱动的隐藏身份游戏,即“变色龙”游戏,来模拟现实世界中需要策略性信息控制的场景。通过观察LLM在游戏中的行为,分析其信息控制策略,并与理论最优策略进行比较,从而评估LLM的信息控制能力。
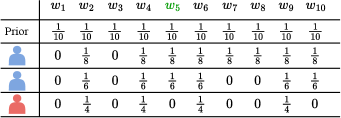
技术框架:整体框架包括以下几个主要模块:1) 游戏环境:设计“变色龙”游戏规则,包括角色分配(变色龙和非变色龙)、秘密信息、回合制对话等。2) LLM智能体:使用不同的LLM(GPT、Gemini、Llama、Qwen)作为智能体参与游戏。3) 策略分析:对一系列策略(从完全隐藏到完全揭示)进行理论分析,计算非变色龙获胜概率的上下界。4) 实验评估:让LLM智能体参与游戏,记录其行为和胜率,并与理论分析结果进行比较。5) 内部表征分析:分析LLM内部表征与信息揭示程度之间的关系,探索通过操纵内部表征来控制LLM行为的可能性。
关键创新:论文的关键创新在于:1) 游戏设计:设计了“变色龙”游戏,提供了一个评估LLM策略性信息控制能力的标准化平台。2) 理论分析:对不同信息控制策略进行了理论分析,为评估LLM行为提供了基准。3) 内部表征操纵:发现LLM内部表征与信息揭示程度之间的线性关系,并探索了通过操纵内部表征来控制LLM行为的方法。
关键设计:1) 游戏规则:精心设计的游戏规则确保了信息隐藏和信息揭示之间的平衡,使得LLM需要同时具备这两种能力才能取得好的结果。2) 指令设计:通过不同的指令来引导LLM采用不同的信息控制策略,例如“尽可能隐藏秘密”或“尽可能揭示秘密”。3) 内部表征分析方法:使用线性探针来分析LLM内部表征与信息揭示程度之间的关系,并使用梯度下降等方法来操纵内部表征。
🖼️ 关键图片

📊 实验亮点
实验结果表明,非变色龙LLM智能体虽然能够识别变色龙,但无法有效隐藏秘密,胜率远低于理论最优值。更有趣的是,研究发现LLM的信息揭示程度线性编码在其内部表征中,通过操纵内部表征可以直接诱导LLM的隐藏行为。例如,通过引导内部表征,可以使LLM在隐藏秘密方面表现更好。
🎯 应用场景
该研究成果可应用于开发更安全、更可靠的LLM智能体,尤其是在涉及隐私保护、安全通信和策略谈判等领域。例如,可以利用该研究成果来防止LLM泄露敏感信息,或提高LLM在谈判中的表现。此外,该研究也为理解LLM的内部工作机制提供了新的视角。
📄 摘要(原文)
Large language model-based (LLM-based) agents have become common in settings that include non-cooperative parties. In such settings, agents' decision-making needs to conceal information from their adversaries, reveal information to their cooperators, and infer information to identify the other agents' characteristics. To investigate whether LLMs have these information control and decision-making capabilities, we make LLM agents play the language-based hidden-identity game, The Chameleon. In this game, a group of non-chameleon agents who do not know each other aim to identify the chameleon agent without revealing a secret. The game requires the aforementioned information control capabilities both as a chameleon and a non-chameleon. We begin with a theoretical analysis for a spectrum of strategies, from concealing to revealing, and provide bounds on the non-chameleons' winning probability. The empirical results with GPT, Gemini 2.5 Pro, Llama 3.1, and Qwen3 models show that while non-chameleon LLM agents identify the chameleon, they fail to conceal the secret from the chameleon, and their winning probability is far from the levels of even trivial strategies. Based on these empirical results and our theoretical analysis, we deduce that LLM-based agents may reveal excessive information to agents of unknown identities. Interestingly, we find that, when instructed to adopt an information-revealing level, this level is linearly encoded in the LLM's internal representations. While the instructions alone are often ineffective at making non-chameleon LLMs conceal, we show that steering the internal representations in this linear direction directly can reliably induce concealing behavior.