We're Different, We're the Same: Creative Homogeneity Across LLMs
作者: Emily Wenger, Yoed Kenett
分类: cs.CY, cs.AI, cs.CL, cs.LG
发布日期: 2025-01-31
💡 一句话要点
揭示大语言模型在创意生成上的同质性:不同模型,相似结果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 创意生成 同质性 多样性 创造力测试
📋 核心要点
- 现有研究表明,使用单一LLM进行创意生成会导致输出范围变窄,但未考察是否为LLM的普遍现象。
- 该研究通过对比人类和多个LLM在标准化创造力测试中的表现,评估LLM在创意生成上的同质性。
- 实验结果表明,LLM的创意输出比人类更具同质性,即使控制了响应结构等变量后依然如此。
📝 摘要(中文)
目前,大量强大的大语言模型(LLM)被用作写作辅助工具、创意生成器等。尽管这些LLM被宣传为有用的创意助手,但一些研究表明,使用LLM作为创意伙伴会导致创意输出范围变窄。然而,这些研究只考虑了与单个LLM交互的影响,引出了一个问题:这种创造力的窄化是源于使用特定的LLM(其输出范围可能有限),还是源于普遍使用LLM作为创意助手?为了研究这个问题,我们使用标准化的创造力测试,从人类和广泛的LLM集合中获取创造性响应,并比较响应在群体层面的多样性。我们发现,即使在控制了响应结构和其他关键变量后,LLM响应彼此之间的相似性也远高于人类响应之间的相似性。我们评估的LLM在创意输出方面表现出显著的同质性,这一发现为当前关于创造力和LLM的讨论增加了一个新的维度。如果今天的LLM表现相似,那么无论使用哪种模型,将它们用作创意伙伴都可能将所有用户推向一组有限的“创意”输出。
🔬 方法详解
问题定义:现有研究表明,使用单个LLM作为创意伙伴会限制创意输出的多样性。然而,这些研究未能区分这种现象是特定于某个LLM的,还是所有LLM的共性。因此,该论文旨在研究不同LLM在创意生成任务中是否表现出同质性,以及这种同质性是否会限制用户的创意空间。现有方法主要关注单个LLM的性能,缺乏对多个LLM之间创意输出差异的系统性比较。
核心思路:该论文的核心思路是通过比较人类和多个LLM在标准化创造力测试中的表现,来评估LLM在创意生成上的同质性。如果LLM的输出比人类更相似,则表明LLM在创意生成上存在同质性,这可能会限制用户的创意空间。通过控制响应结构等变量,可以更准确地评估LLM的内在同质性。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择多个具有代表性的LLM;2) 设计标准化的创造力测试,例如发散性思维测试;3) 收集人类和LLM的响应;4) 对响应进行预处理,例如去除停用词、词干化等;5) 计算响应之间的相似度,例如使用余弦相似度;6) 比较人类和LLM响应的相似度分布,并进行统计显著性检验。
关键创新:该论文的关键创新在于首次系统性地研究了多个LLM在创意生成上的同质性。以往的研究主要关注单个LLM的性能,而忽略了不同LLM之间的差异。该论文通过比较人类和LLM的响应,揭示了LLM在创意生成上存在的同质性问题,为未来的研究提供了新的视角。
关键设计:该研究的关键设计包括:1) 选择具有代表性的LLM,例如不同架构、不同训练数据的LLM;2) 设计标准化的创造力测试,以确保测试的有效性和可靠性;3) 使用合适的相似度度量方法,例如余弦相似度,来衡量响应之间的相似度;4) 使用统计显著性检验,例如t检验,来评估人类和LLM响应相似度分布的差异。
🖼️ 关键图片
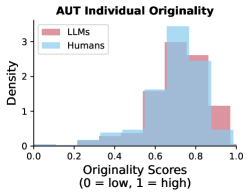
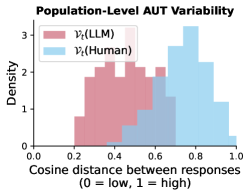
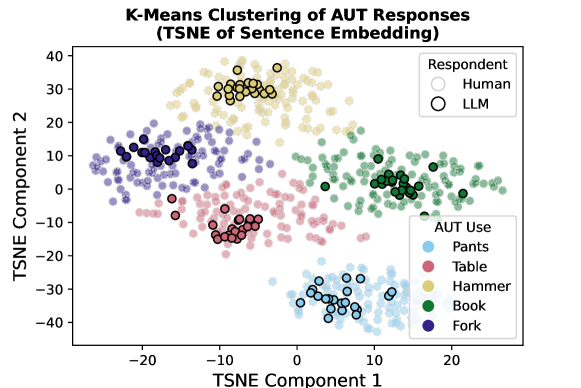
📊 实验亮点
实验结果表明,LLM的创意输出比人类更具同质性,即使在控制了响应结构和其他关键变量后,LLM响应彼此之间的相似性也远高于人类响应之间的相似性。这表明,无论使用哪种LLM,都可能导致用户产生相似的创意,从而限制了创意空间。具体的性能数据和对比基线在论文中进行了详细的描述。
🎯 应用场景
该研究结果对LLM在创意领域的应用具有重要意义。如果LLM在创意生成上存在同质性,那么用户在使用LLM作为创意伙伴时,需要意识到这种局限性,并采取相应的措施来避免创意输出的窄化。例如,可以尝试使用多种不同的LLM,或者结合人类的创意,来提高创意输出的多样性。该研究还可以指导LLM的开发,使其能够生成更多样化的创意。
📄 摘要(原文)
Numerous powerful large language models (LLMs) are now available for use as writing support tools, idea generators, and beyond. Although these LLMs are marketed as helpful creative assistants, several works have shown that using an LLM as a creative partner results in a narrower set of creative outputs. However, these studies only consider the effects of interacting with a single LLM, begging the question of whether such narrowed creativity stems from using a particular LLM -- which arguably has a limited range of outputs -- or from using LLMs in general as creative assistants. To study this question, we elicit creative responses from humans and a broad set of LLMs using standardized creativity tests and compare the population-level diversity of responses. We find that LLM responses are much more similar to other LLM responses than human responses are to each other, even after controlling for response structure and other key variables. This finding of significant homogeneity in creative outputs across the LLMs we evaluate adds a new dimension to the ongoing conversation about creativity and LLMs. If today's LLMs behave similarly, using them as a creative partners -- regardless of the model used -- may drive all users towards a limited set of "creative" outputs.