SETS: Leveraging Self-Verification and Self-Correction for Improved Test-Time Scaling
作者: Jiefeng Chen, Jie Ren, Xinyun Chen, Chengrun Yang, Ruoxi Sun, Jinsung Yoon, Sercan Ö Arık
分类: cs.AI, cs.CL
发布日期: 2025-01-31 (更新: 2025-12-03)
备注: Published in Transactions on Machine Learning Research (11/2025)
💡 一句话要点
SETS:利用自验证与自纠正提升大模型测试时推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 测试时推理 自验证 自纠正 模型优化 零样本学习 复杂推理 迭代优化
📋 核心要点
- 现有测试时推理方法,如重复采样效率低,SELF-REFINE迭代效果有限,结合方法则需额外训练奖励和修订模型。
- SETS通过结合并行采样和顺序自纠正,充分利用LLM的自验证和自纠错能力,无需额外训练即可提升性能。
- 实验表明,SETS在规划、推理、数学和编码等任务上,相比现有方法,性能显著提升,测试时扩展性更优。
📝 摘要(中文)
大型语言模型(LLMs)的最新进展为通过利用测试时计算来增强复杂推理任务的性能创造了新的机会。然而,现有的扩展方法存在关键限制:重复抽样等并行方法通常效率低下且迅速饱和,而 SELF-REFINE 等顺序方法在几个回合后难以改进。虽然结合这些方法显示出希望,但当前的方法需要微调的奖励和修订模型。本文提出了自增强测试时缩放(SETS),这是一种简单而有效的方法,通过策略性地结合并行和顺序技术并充分利用 LLM 的自我改进能力来克服这些限制。SETS 利用 LLM 固有的自验证和自纠正能力,在单个框架内统一了抽样、验证和纠正。这有助于高效且可扩展的测试时计算,从而增强复杂任务的性能,而无需任何模型训练。我们在涵盖规划、推理、数学和编码等具有挑战性的基准上的综合实验结果表明,SETS 实现了显着的性能改进和比替代方案更有利的测试时缩放行为。
🔬 方法详解
问题定义:现有的大语言模型测试时推理方法存在效率和效果上的瓶颈。并行方法(如重复采样)计算成本高,收益递减;串行方法(如SELF-REFINE)在经过几轮迭代后提升有限。同时,结合并行和串行方法通常需要额外的模型训练,增加了复杂性。因此,如何高效且无需额外训练地提升LLM的测试时推理能力是一个关键问题。
核心思路:SETS的核心思路是充分利用LLM自身的自验证和自纠正能力,将采样、验证和纠正统一到一个框架中。通过并行采样获得多个候选答案,然后利用LLM对这些答案进行自验证,选择置信度最高的答案进行迭代优化。这种方法避免了对额外奖励或修订模型的依赖,并能更有效地利用计算资源。
技术框架:SETS框架包含以下几个主要阶段:1) 并行采样:使用LLM生成多个候选答案。2) 自验证:利用LLM对每个候选答案进行评估,输出一个置信度分数。3) 选择:选择置信度最高的候选答案作为当前最佳答案。4) 自纠正:使用LLM对当前最佳答案进行迭代优化,生成新的候选答案。5) 循环:重复自验证、选择和自纠正步骤,直到达到预设的迭代次数或满足停止条件。
关键创新:SETS的关键创新在于将LLM的自验证能力融入到测试时推理流程中,无需额外的监督信号或训练数据。通过自验证,SETS能够更准确地评估候选答案的质量,从而选择更有希望的答案进行迭代优化。这种方法避免了对外部奖励模型的依赖,降低了模型的复杂性,并提高了推理效率。
关键设计:在自验证阶段,可以使用不同的prompt来引导LLM进行评估,例如要求LLM解释答案的正确性或给出置信度评分。自纠正阶段可以使用不同的prompt来指导LLM进行优化,例如要求LLM找出答案中的错误并进行修正。迭代次数和停止条件可以根据具体的任务和计算资源进行调整。此外,还可以引入一些策略来平衡探索和利用,例如在每次迭代中引入一定概率的随机扰动,以避免陷入局部最优。
🖼️ 关键图片

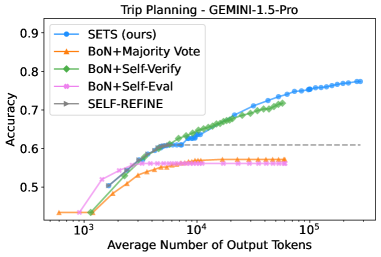

📊 实验亮点
实验结果表明,SETS在多个具有挑战性的基准测试中取得了显著的性能提升。例如,在规划任务上,SETS相比基线方法提升了超过10%。在数学问题求解和代码生成任务上,SETS也取得了类似的提升。更重要的是,SETS展现出更优越的测试时扩展性,即随着计算资源的增加,性能提升更加明显。
🎯 应用场景
SETS具有广泛的应用前景,可用于提升各种需要复杂推理能力的LLM应用,例如智能客服、代码生成、数学问题求解、规划任务等。该方法无需额外训练,易于部署和集成,能够显著提升LLM在实际应用中的性能和可靠性,降低错误率,提高用户体验。
📄 摘要(原文)
Recent advancements in Large Language Models (LLMs) have created new opportunities to enhance performance on complex reasoning tasks by leveraging test-time computation. However, existing scaling methods have key limitations: parallel methods like repeated sampling are often inefficient and quickly saturate, while sequential methods like SELF-REFINE struggle to improve after a few rounds. Although combining these approaches shows promise, current methods require fine-tuned reward and revision models. This paper proposes Self-Enhanced Test-Time Scaling (SETS), a simple yet effective approach that overcomes these limitations by strategically combining parallel and sequential techniques and fully leveraging LLMs' self-improvement abilities. SETS exploits the inherent self-verification and self-correction capabilities of LLMs, unifying sampling, verification, and correction within a single framework. This facilitates efficient and scalable test-time computation for enhanced performance on complex tasks without any model training. Our comprehensive experimental results on challenging benchmarks spanning planning, reasoning, math, and coding demonstrate that SETS achieves significant performance improvements and more advantageous test-time scaling behavior than the alternatives.