Synthetic User Behavior Sequence Generation with Large Language Models for Smart Homes
作者: Zhiyao Xu, Dan Zhao, Qingsong Zou, Jingyu Xiao, Yong Jiang, Zhenhui Yuan, Qing Li
分类: cs.AI, cs.LG, cs.NI
发布日期: 2025-01-31
💡 一句话要点
提出基于大语言模型的IoTGen框架,用于生成智能家居用户行为序列数据,提升下游模型泛化性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 智能家居安全 大语言模型 合成数据生成 物联网行为数据 数据增强
📋 核心要点
- 现有智能家居安全解决方案依赖固定数据集,数据收集耗时且难以适应环境变化,同时存在用户隐私泄露风险。
- 提出基于大语言模型的IoTGen框架,通过生成合成数据来增强智能家居模型的泛化能力,解决数据收集和隐私问题。
- 该框架包含结构模式感知压缩(SPPC)方法,用于减少token消耗,并设计了系统方法来生成规范合理的物联网数据。
📝 摘要(中文)
随着智能家居系统的普及,安全问题日益突出。现有的异常检测和行为预测模型通常使用预先收集的固定数据集进行训练,但数据收集耗时且缺乏灵活性,难以适应不断变化的智能家居环境,同时个人数据收集也引发了隐私问题。本文提出了一种基于大语言模型(LLM)的合成数据集生成框架IoTGen,旨在增强下游智能家居智能模型的泛化能力。通过生成反映环境变化的新合成数据集,智能家居智能模型可以重新训练,克服固定和过时数据的局限性,更好地适应真实家庭环境的动态性。具体而言,我们首先提出了一种针对物联网行为数据的结构模式感知压缩(SPPC)方法,该方法在显著减少token消耗的同时,保留了数据中最有用的信息。然后,我们提出了一种系统的方法来创建提示并实现数据生成,以自动生成具有规范性和合理性的物联网合成数据,辅助任务模型进行自适应训练,从而提高泛化能力和实际性能。
🔬 方法详解
问题定义:现有智能家居安全模型依赖于预先收集的固定数据集进行训练,这些数据集难以适应智能家居环境的动态变化,导致模型泛化能力不足。此外,数据收集过程耗时,且涉及用户隐私泄露的风险。因此,需要一种能够灵活生成数据,同时保护用户隐私的方法来训练智能家居安全模型。
核心思路:利用大语言模型(LLM)强大的自然语言处理、推理和问题解决能力,生成具有规范性和合理性的合成物联网行为数据。通过对LLM进行适当的提示工程,使其能够模拟真实用户的行为模式,从而生成多样化的数据集,用于训练和评估智能家居安全模型。这样可以避免直接收集用户数据,保护用户隐私,同时提高模型的泛化能力。
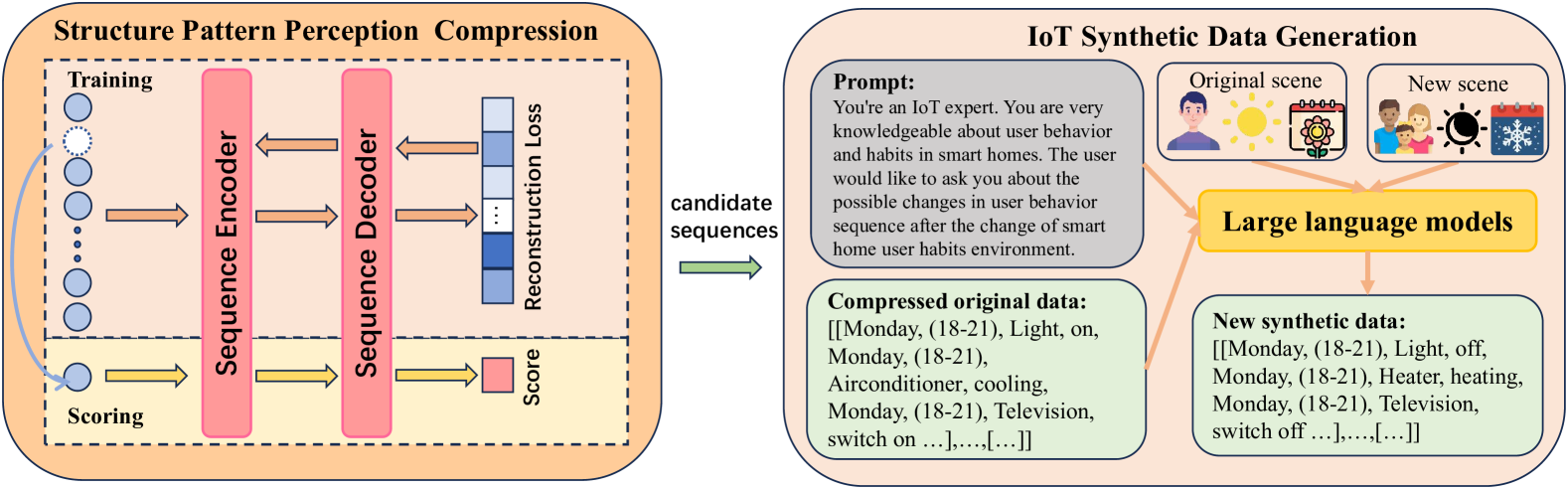
技术框架:IoTGen框架主要包含两个核心模块:结构模式感知压缩(SPPC)和数据生成模块。首先,SPPC模块对原始物联网行为数据进行压缩,提取关键信息,减少LLM的token消耗。然后,数据生成模块根据预定义的提示,利用LLM生成新的合成数据。生成的数据可以用于训练下游的智能家居安全模型,例如异常检测和行为预测模型。
关键创新:该论文的关键创新在于将大语言模型应用于智能家居行为数据的合成生成,并提出了一种结构模式感知压缩(SPPC)方法。SPPC方法能够有效地减少LLM的token消耗,使其能够处理更长的行为序列。此外,该论文还设计了一套系统的提示工程方法,用于指导LLM生成具有规范性和合理性的合成数据。
关键设计:SPPC方法通过提取物联网行为数据中的结构化模式,例如设备类型、操作时间和操作顺序等,并将这些模式压缩成更简洁的表示形式。数据生成模块使用预定义的提示,例如“用户在早上7点起床,打开灯,然后去厨房做早餐”,来指导LLM生成相应的行为序列。提示的设计需要考虑到智能家居环境的特点和用户的日常行为习惯。
🖼️ 关键图片

📊 实验亮点
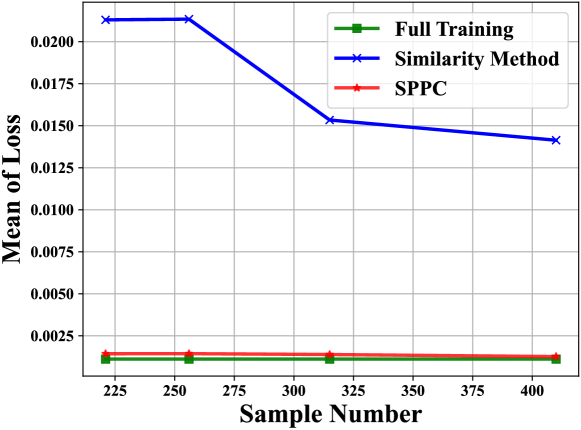
论文提出了SPPC压缩方法,有效降低了token消耗,使得LLM能够处理更长的用户行为序列。通过实验验证,使用IoTGen生成的合成数据训练的智能家居模型,在泛化能力和实际性能方面均有显著提升(具体性能数据未知)。与使用真实数据训练的模型相比,使用合成数据训练的模型在某些场景下表现更好(具体场景未知)。
🎯 应用场景
该研究成果可应用于智能家居安全、智能家居设备测试与评估、以及个性化智能家居服务等领域。通过生成多样化的用户行为数据,可以提升智能家居安全模型的鲁棒性和泛化能力,有效应对各种潜在的安全威胁。此外,合成数据还可以用于评估智能家居设备的性能和用户体验,为产品设计和优化提供数据支持。未来,该技术有望应用于更广泛的物联网领域,促进物联网技术的智能化发展。
📄 摘要(原文)
In recent years, as smart home systems have become more widespread, security concerns within these environments have become a growing threat. Currently, most smart home security solutions, such as anomaly detection and behavior prediction models, are trained using fixed datasets that are precollected. However, the process of dataset collection is time-consuming and lacks the flexibility needed to adapt to the constantly evolving smart home environment. Additionally, the collection of personal data raises significant privacy concerns for users. Lately, large language models (LLMs) have emerged as a powerful tool for a wide range of tasks across diverse application domains, thanks to their strong capabilities in natural language processing, reasoning, and problem-solving. In this paper, we propose an LLM-based synthetic dataset generation IoTGen framework to enhance the generalization of downstream smart home intelligent models. By generating new synthetic datasets that reflect changes in the environment, smart home intelligent models can be retrained to overcome the limitations of fixed and outdated data, allowing them to better align with the dynamic nature of real-world home environments. Specifically, we first propose a Structure Pattern Perception Compression (SPPC) method tailored for IoT behavior data, which preserves the most informative content in the data while significantly reducing token consumption. Then, we propose a systematic approach to create prompts and implement data generation to automatically generate IoT synthetic data with normative and reasonable properties, assisting task models in adaptive training to improve generalization and real-world performance.