SHARPIE: A Modular Framework for Reinforcement Learning and Human-AI Interaction Experiments
作者: Hüseyin Aydın, Kevin Godin-Dubois, Libio Goncalvez Braz, Floris den Hengst, Kim Baraka, Mustafa Mert Çelikok, Andreas Sauter, Shihan Wang, Frans A. Oliehoek
分类: cs.AI, cs.HC
发布日期: 2025-01-31 (更新: 2025-02-03)
💡 一句话要点
SHARPIE:用于人机交互强化学习实验的模块化通用框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人机交互 强化学习 实验平台 模块化设计 通用框架
📋 核心要点
- 现有强化学习人机交互实验缺乏通用框架,阻碍了研究的标准化和复现。
- SHARPIE提供模块化平台,集成了环境封装、Web界面、日志记录和云部署,简化实验流程。
- 该平台支持多种人机交互研究,如奖励塑造、反馈学习、行为委托等,促进人机协作。
📝 摘要(中文)
本文提出了SHARPIE(共享人机交互强化学习平台),旨在满足对支持强化学习智能体与人类交互实验的通用框架的需求。SHARPIE采用模块化设计,包含一个用于强化学习环境和算法库的通用封装器、一个面向参与者的Web界面、日志记录工具,并支持在流行的云平台和参与者招募平台上部署。它使研究人员能够研究与人类和强化学习智能体之间交互相关的各种研究问题,包括交互式奖励规范和学习、从人类反馈中学习、行动委托、偏好获取、用户建模和人机协作。该平台基于人机交互的通用接口,旨在标准化人机环境下的强化学习研究领域。
🔬 方法详解
问题定义:现有的人机交互强化学习研究通常依赖于定制化的实验环境和代码,缺乏一个通用的、可复用的平台。这使得研究结果难以比较和推广,同时也增加了研究人员的开发成本。因此,需要一个标准化的平台来支持各种人机交互强化学习实验。
核心思路:SHARPIE的核心思路是提供一个模块化的、可扩展的平台,将强化学习环境、算法、人机交互界面和实验管理工具集成在一起。通过定义清晰的接口和协议,SHARPIE允许研究人员轻松地构建和部署各种人机交互实验,并收集和分析实验数据。
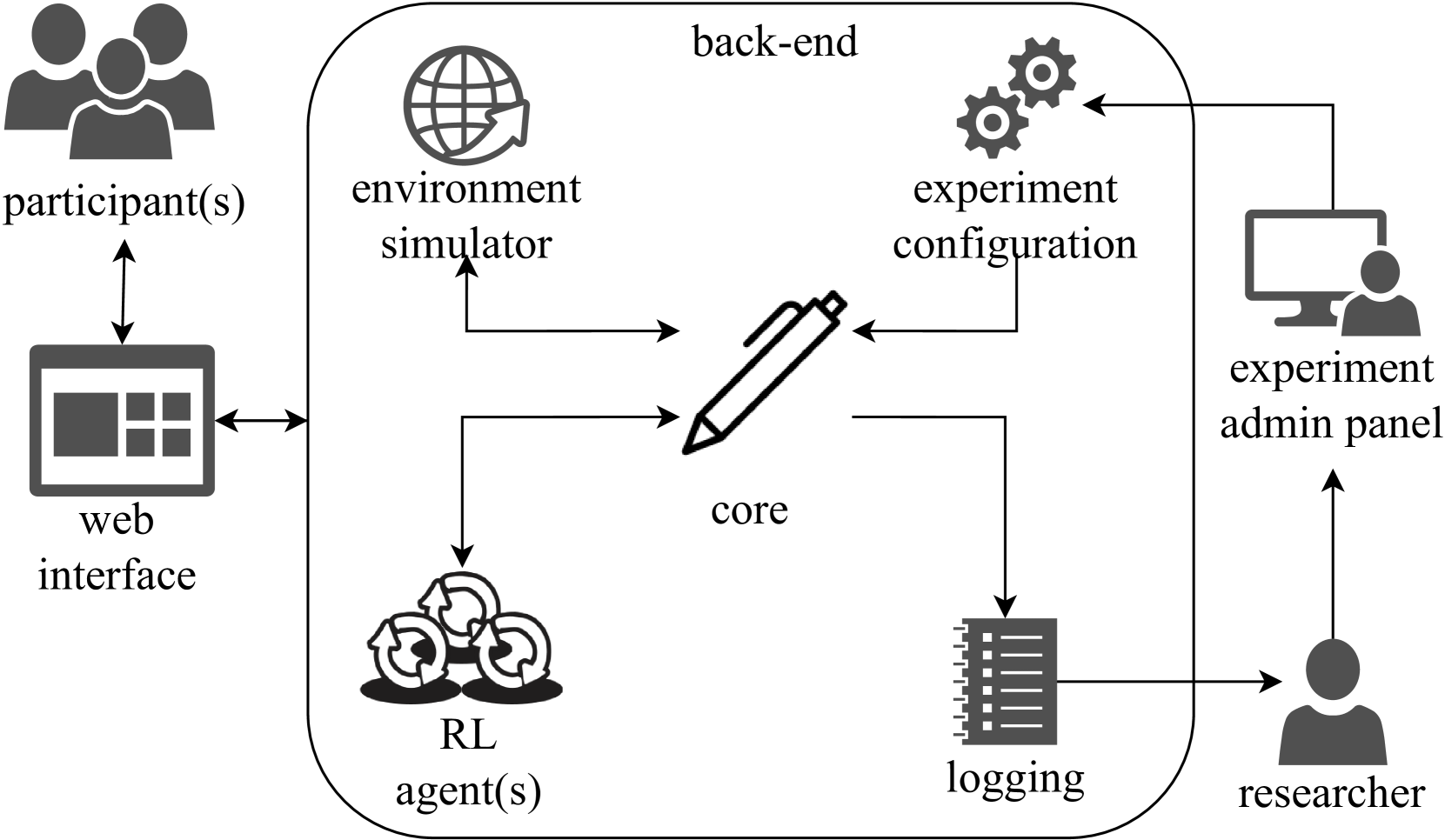
技术框架:SHARPIE的整体架构包括以下几个主要模块:1) 环境封装器:用于将各种强化学习环境(如OpenAI Gym)封装成统一的接口;2) 算法库:包含常用的强化学习算法,如Q-learning、SARSA、Policy Gradient等;3) Web界面:提供用户友好的交互界面,允许人类参与者与强化学习智能体进行交互;4) 日志记录:记录实验过程中的各种数据,如人类参与者的行为、智能体的状态和奖励等;5) 云部署:支持在流行的云平台(如AWS、Azure)上部署实验。
关键创新:SHARPIE的关键创新在于其模块化和通用性。它提供了一个标准化的平台,可以支持各种人机交互强化学习实验,从而促进了该领域的研究进展。此外,SHARPIE还提供了一个用户友好的Web界面和强大的日志记录功能,使得实验更加易于管理和分析。
关键设计:SHARPIE的关键设计包括:1) 使用RESTful API进行模块之间的通信;2) 使用JSON格式存储实验数据;3) 使用Docker容器化部署实验;4) 提供灵活的配置选项,允许研究人员自定义实验参数。
🖼️ 关键图片
📊 实验亮点
论文提出了一个通用的人机交互强化学习平台SHARPIE,它通过模块化的设计,集成了环境封装、算法库、Web界面、日志记录和云部署等功能,使得研究人员可以更加方便地进行人机交互实验。该平台支持多种人机交互研究,例如交互式奖励规范和学习、从人类反馈中学习、行动委托、偏好获取、用户建模和人机协作等。
🎯 应用场景
SHARPIE可应用于各种人机协作场景,例如:辅助驾驶、智能家居、医疗诊断等。通过该平台,研究人员可以探索如何设计更智能、更人性化的AI系统,从而提高人机协作的效率和安全性。未来,SHARPIE有望成为人机交互强化学习研究的标准平台。
📄 摘要(原文)
Reinforcement learning (RL) offers a general approach for modeling and training AI agents, including human-AI interaction scenarios. In this paper, we propose SHARPIE (Shared Human-AI Reinforcement Learning Platform for Interactive Experiments) to address the need for a generic framework to support experiments with RL agents and humans. Its modular design consists of a versatile wrapper for RL environments and algorithm libraries, a participant-facing web interface, logging utilities, deployment on popular cloud and participant recruitment platforms. It empowers researchers to study a wide variety of research questions related to the interaction between humans and RL agents, including those related to interactive reward specification and learning, learning from human feedback, action delegation, preference elicitation, user-modeling, and human-AI teaming. The platform is based on a generic interface for human-RL interactions that aims to standardize the field of study on RL in human contexts.