LLM-RecG: A Semantic Bias-Aware Framework for Zero-Shot Sequential Recommendation
作者: Yunzhe Li, Junting Wang, Hari Sundaram, Zhining Liu
分类: cs.IR, cs.AI
发布日期: 2025-01-31 (更新: 2025-07-17)
备注: 10 pages, Recsys'25 Spotlight Oral
💡 一句话要点
LLM-RecG:一种语义偏差感知的零样本序列推荐框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 跨域推荐 序列推荐 大型语言模型 语义偏差
📋 核心要点
- 现有零样本跨域序列推荐方法受限于领域语义偏差,导致项目嵌入错位,降低跨域泛化能力。
- 提出LLM-RecG框架,通过在项目和序列层面进行跨域对齐,缓解语义偏差问题,提升推荐效果。
- 实验结果表明,该方法在零样本跨域序列推荐任务上表现出色,显著提升了推荐性能。
📝 摘要(中文)
零样本跨域序列推荐(ZCDSR)能够在未见过的领域进行预测,无需额外的训练或微调,从而解决了传统模型在稀疏数据环境中的局限性。大型语言模型(LLM)的最新进展通过丰富的预训练表示,显著增强了ZCDSR的性能,促进了跨域知识的迁移。尽管取得了这些进展,领域语义偏差(源于领域之间词汇和内容重点的差异)仍然是一个持续的挑战,导致项目嵌入错位并降低了跨域泛化能力。为了解决这个问题,我们提出了一种新颖的语义偏差感知框架,通过在项目和序列级别上改进跨域对齐来增强基于LLM的ZCDSR。在项目级别,我们引入了一种泛化损失,该损失对齐跨域的项目嵌入(域间紧凑性),同时保留每个项目在其自身域内的独特特征(域内多样性)。这确保了项目嵌入可以在域之间有效地转移,而不会崩溃为过于通用或统一的表示。在序列级别,我们开发了一种通过聚类源域用户序列并在目标域推理期间应用基于注意力的聚合来转移用户行为模式的方法。我们动态地将用户嵌入适应到未见过的域,从而实现有效的零样本推荐,而无需目标域交互。
🔬 方法详解
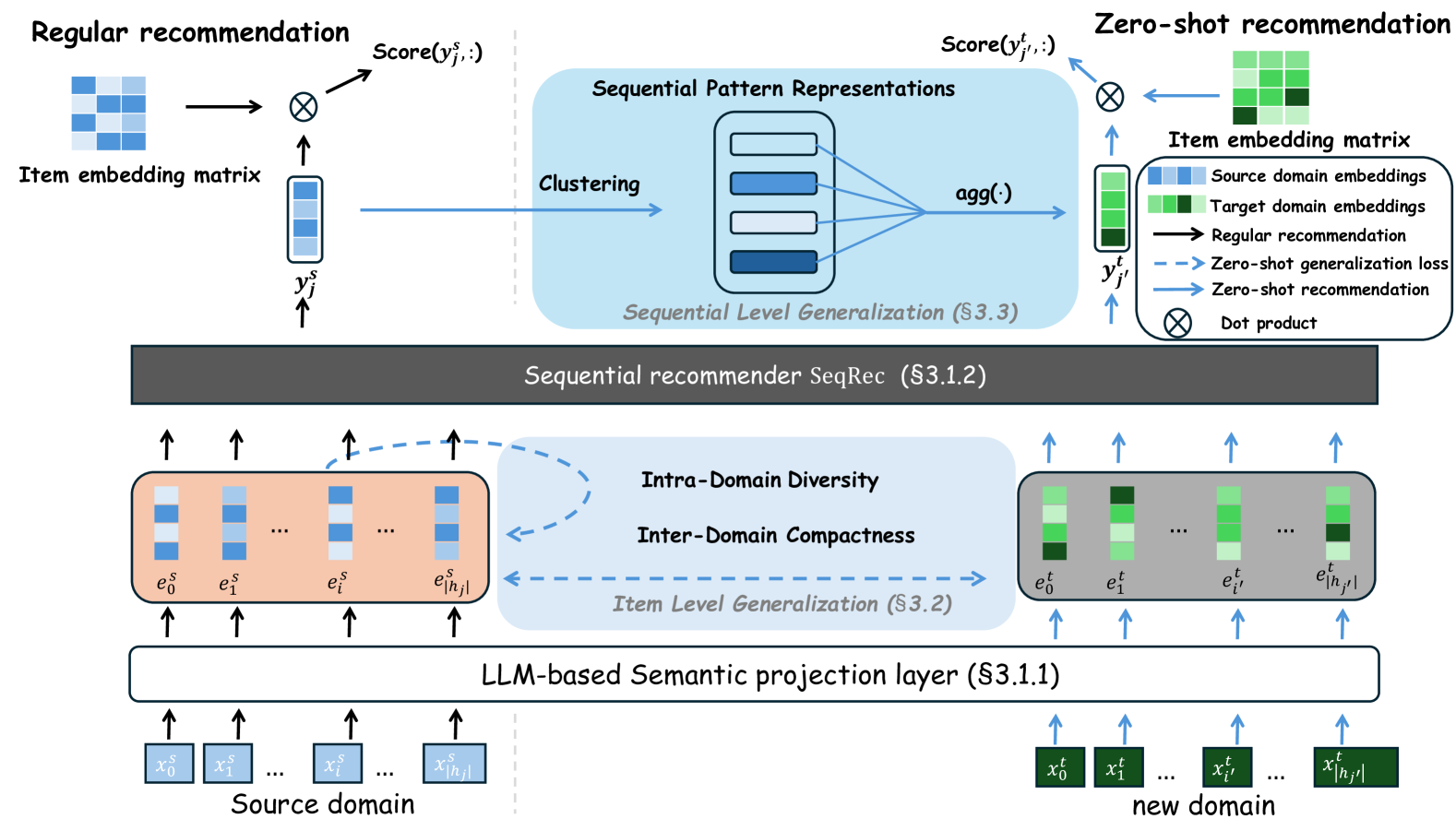
问题定义:论文旨在解决零样本跨域序列推荐(ZCDSR)中由于领域语义偏差导致的跨域泛化能力不足的问题。现有方法忽略了不同领域之间词汇和内容重点的差异,导致项目嵌入错位,无法有效进行知识迁移。
核心思路:论文的核心思路是通过在项目级别和序列级别上进行跨域对齐,从而缓解领域语义偏差。在项目级别,通过泛化损失函数实现域间紧凑性和域内多样性;在序列级别,通过迁移用户行为模式,动态适应用户嵌入到未见过的域。
技术框架:LLM-RecG框架包含两个主要模块:项目级别对齐和序列级别对齐。项目级别对齐模块利用大型语言模型生成项目嵌入,并使用泛化损失函数进行跨域对齐。序列级别对齐模块首先对源域用户序列进行聚类,然后使用基于注意力的聚合方法将用户行为模式迁移到目标域。在目标域推理时,动态调整用户嵌入,实现零样本推荐。
关键创新:论文的关键创新在于提出了一个语义偏差感知的框架,能够同时在项目级别和序列级别上进行跨域对齐。泛化损失函数的设计,既保证了跨域项目嵌入的紧凑性,又保留了每个项目在其自身域内的独特性。序列级别的用户行为模式迁移方法,能够动态适应用户嵌入到未见过的域。
关键设计:泛化损失函数包含两部分:域间紧凑性损失和域内多样性损失。域间紧凑性损失旨在拉近不同域中相似项目的嵌入距离,域内多样性损失旨在保持同一域内不同项目的嵌入差异。序列级别的用户行为模式迁移方法使用注意力机制,根据用户历史行为对不同聚类中心进行加权聚合,从而动态调整用户嵌入。
🖼️ 关键图片
📊 实验亮点
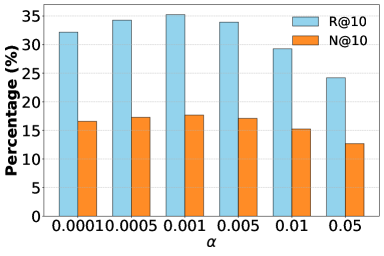
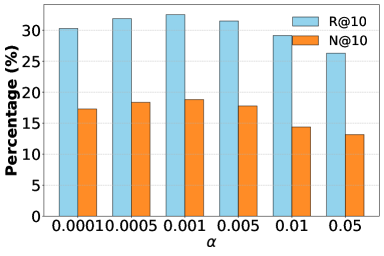
实验结果表明,LLM-RecG框架在多个零样本跨域序列推荐数据集上取得了显著的性能提升。相较于现有基线方法,LLM-RecG在Recall@K和NDCG@K等指标上均有明显提高,证明了其有效性。例如,在某数据集上,Recall@10提升了超过10%。
🎯 应用场景
该研究成果可应用于电商、在线教育、新闻推荐等领域,尤其适用于新领域或冷启动场景。通过跨域知识迁移,能够有效提升推荐系统的性能,改善用户体验,并为企业带来更大的商业价值。未来,该方法可以扩展到更多模态的数据,例如图像、视频等,进一步提升推荐效果。
📄 摘要(原文)
Zero-shot cross-domain sequential recommendation (ZCDSR) enables predictions in unseen domains without additional training or fine-tuning, addressing the limitations of traditional models in sparse data environments. Recent advancements in large language models (LLMs) have significantly enhanced ZCDSR by facilitating cross-domain knowledge transfer through rich, pretrained representations. Despite this progress, domain semantic bias -- arising from differences in vocabulary and content focus between domains -- remains a persistent challenge, leading to misaligned item embeddings and reduced generalization across domains. To address this, we propose a novel semantic bias-aware framework that enhances LLM-based ZCDSR by improving cross-domain alignment at both the item and sequential levels. At the item level, we introduce a generalization loss that aligns the embeddings of items across domains (inter-domain compactness), while preserving the unique characteristics of each item within its own domain (intra-domain diversity). This ensures that item embeddings can be transferred effectively between domains without collapsing into overly generic or uniform representations. At the sequential level, we develop a method to transfer user behavioral patterns by clustering source domain user sequences and applying attention-based aggregation during target domain inference. We dynamically adapt user embeddings to unseen domains, enabling effective zero-shot recommendations without requiring target-domain interactions...