An Empirical Game-Theoretic Analysis of Autonomous Cyber-Defence Agents
作者: Gregory Palmer, Luke Swaby, Daniel J. B. Harrold, Matthew Stewart, Alex Hiles, Chris Willis, Ian Miles, Sara Farmer
分类: cs.AI, cs.CR, cs.GT
发布日期: 2025-01-31
备注: 21 pages, 17 figures, 10 tables
💡 一句话要点
提出基于潜在奖励塑造和多响应预言机的深度强化学习网络攻防博弈分析框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自主网络防御 深度强化学习 博弈论 双预言机 奖励塑造 多响应预言机 网络安全 攻防博弈
📋 核心要点
- 现有自主网络防御(ACD)代理在面对复杂多变的网络攻击时,泛化能力不足,且缺乏有效的验证方法。
- 论文提出一种基于双预言机(DO)算法的实证博弈论分析框架,并引入潜在奖励塑造加速学习过程。
- 通过扩展DO算法到多响应预言机(MRO),实现了对多种开源ACD-DRL方法的综合评估。
📝 摘要(中文)
为了应对日益复杂的网络攻击,本文提出了一种稳健且具有弹性的自主网络防御(ACD)代理方法。考虑到网络攻击策略、技术和程序(TTPs)的多样性,需要能够返回通用策略的学习方法。同时,ACD代理的可靠性仍然是一个开放的挑战。本文通过对ACD的深度强化学习(DRL)方法进行实证博弈论分析,并使用基于原则的双预言机(DO)算法来解决这两个挑战。该算法依赖于对抗者迭代地学习彼此策略的(近似)最佳响应;对于自主网络操作代理来说,这是一项计算量大的工作。在这项工作中,我们介绍并评估了一种理论上合理的、基于势的奖励塑造方法,以加速这一过程。此外,鉴于越来越多的开源ACD-DRL方法,我们扩展了DO公式以允许多个响应预言机(MRO),从而为ACD方法的整体评估提供了一个框架。
🔬 方法详解
问题定义:论文旨在解决自主网络防御(ACD)代理的泛化能力和验证问题。现有的ACD代理在面对不断演化的网络攻击时,难以适应新的攻击模式,并且缺乏一个统一的评估框架来比较不同ACD代理的性能。双预言机算法虽然可以用于评估,但计算成本高昂。
核心思路:论文的核心思路是利用双预言机(DO)算法进行博弈论分析,评估ACD代理的性能。为了降低DO算法的计算复杂度,引入了基于势的奖励塑造方法,加速学习过程。此外,通过扩展DO算法到多响应预言机(MRO),可以同时评估多个ACD代理,从而提供更全面的评估结果。
技术框架:整体框架包括以下几个主要模块:1) 网络攻防环境模拟器;2) 基于深度强化学习的ACD代理;3) 双预言机(DO)算法,用于迭代学习攻防策略;4) 潜在奖励塑造模块,用于加速学习过程;5) 多响应预言机(MRO)模块,用于同时评估多个ACD代理。攻防双方通过在模拟环境中进行对抗,不断学习和优化各自的策略。
关键创新:论文的关键创新点在于:1) 引入了基于势的奖励塑造方法,显著加速了双预言机算法的学习过程;2) 提出了多响应预言机(MRO)的概念,扩展了DO算法的应用范围,使其能够同时评估多个ACD代理。这为ACD代理的综合评估提供了一个新的框架。
关键设计:潜在奖励塑造函数的设计需要保证势函数的梯度能够引导智能体朝着更有利的方向探索,同时避免引入额外的偏差。多响应预言机(MRO)的实现需要考虑如何有效地整合来自不同ACD代理的响应,并选择最佳的响应策略。具体的网络结构和损失函数取决于所使用的深度强化学习算法,例如可以使用DQN、PPO等算法。
🖼️ 关键图片

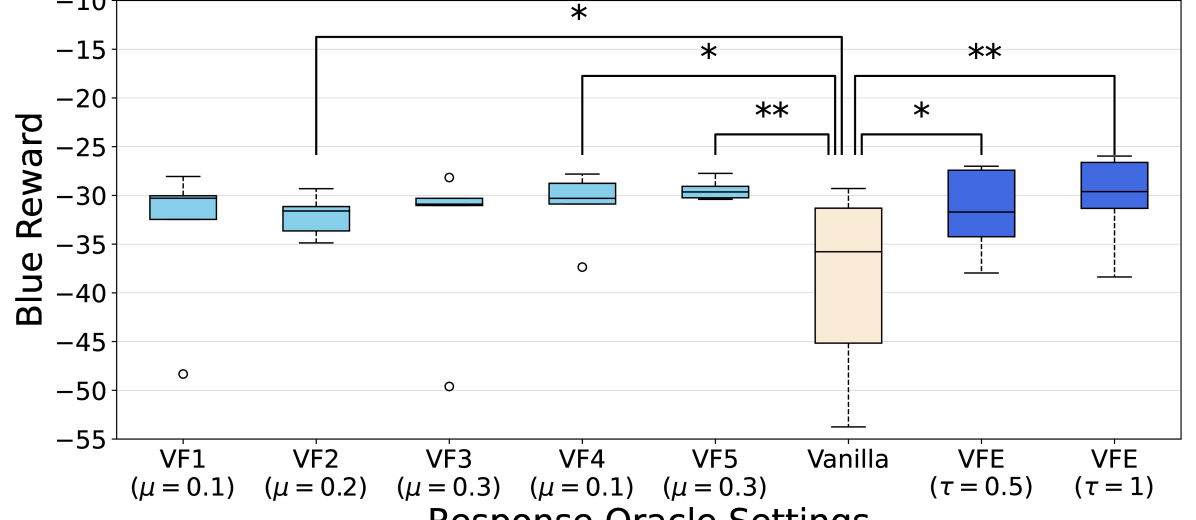

📊 实验亮点
论文通过实验验证了潜在奖励塑造方法能够显著加速双预言机算法的学习过程,提高了ACD代理的训练效率。多响应预言机框架能够有效地评估多个ACD代理的性能,并识别出最佳的防御策略。具体的性能数据和提升幅度在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于构建更智能、更可靠的自主网络防御系统,提升网络安全防护能力。通过多响应预言机框架,可以对各种开源ACD-DRL方法进行全面评估,为实际部署提供参考。此外,该方法还可用于其他安全领域的对抗博弈分析,例如恶意软件检测、入侵检测等。
📄 摘要(原文)
The recent rise in increasingly sophisticated cyber-attacks raises the need for robust and resilient autonomous cyber-defence (ACD) agents. Given the variety of cyber-attack tactics, techniques and procedures (TTPs) employed, learning approaches that can return generalisable policies are desirable. Meanwhile, the assurance of ACD agents remains an open challenge. We address both challenges via an empirical game-theoretic analysis of deep reinforcement learning (DRL) approaches for ACD using the principled double oracle (DO) algorithm. This algorithm relies on adversaries iteratively learning (approximate) best responses against each others' policies; a computationally expensive endeavour for autonomous cyber operations agents. In this work we introduce and evaluate a theoretically-sound, potential-based reward shaping approach to expedite this process. In addition, given the increasing number of open-source ACD-DRL approaches, we extend the DO formulation to allow for multiple response oracles (MRO), providing a framework for a holistic evaluation of ACD approaches.