Language Games as the Pathway to Artificial Superhuman Intelligence
作者: Ying Wen, Ziyu Wan, Shao Zhang
分类: cs.AI, cs.CL, cs.MA
发布日期: 2025-01-31
备注: This position paper argues that language games provide robust mechanism for achieving superhuman intelligence in large language models
💡 一句话要点
提出基于语言游戏的ASI演进框架,突破数据再生产陷阱
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言游戏 人工超人智能 数据再生产 多智能体系统 角色流动性 奖励多样性 规则可塑性
📋 核心要点
- 现有LLM训练方法易陷入数据再生产陷阱,模型仅重组现有知识,缺乏新知识探索。
- 提出基于语言游戏的框架,通过角色流动、奖励多样和规则可塑性打破循环,注入新颖性。
- 通过人机协同进化,语言游戏产生无限数据流,驱动LLM向人工超人智能演进。
📝 摘要(中文)
大型语言模型(LLMs)向人工超人智能(ASI)的演进依赖于数据再生产,这是一个模型生成、管理和重新训练新数据的循环过程,以完善能力。然而,当前的方法有陷入数据再生产陷阱的风险:在封闭循环中优化固定的人工生成分布内的输出会导致停滞,因为模型仅仅是重新组合现有知识,而不是探索新的领域。在本文中,我们提出语言游戏作为扩展数据再生产的途径,通过三种机制打破这个循环:(1)角色流动性,通过允许多智能体系统在任务中动态切换角色来增强数据的多样性和覆盖范围;(2)奖励多样性,嵌入多个反馈标准,可以驱动复杂的智能行为;(3)规则可塑性,迭代地演化交互约束以促进可学习性,从而注入持续的新颖性。通过将语言游戏扩展到全球社会技术生态系统中,人机协同进化产生无限的数据流,从而驱动开放式探索。这个框架将数据再生产重新定义为超人智能的引擎,而不是一个封闭的循环。
🔬 方法详解
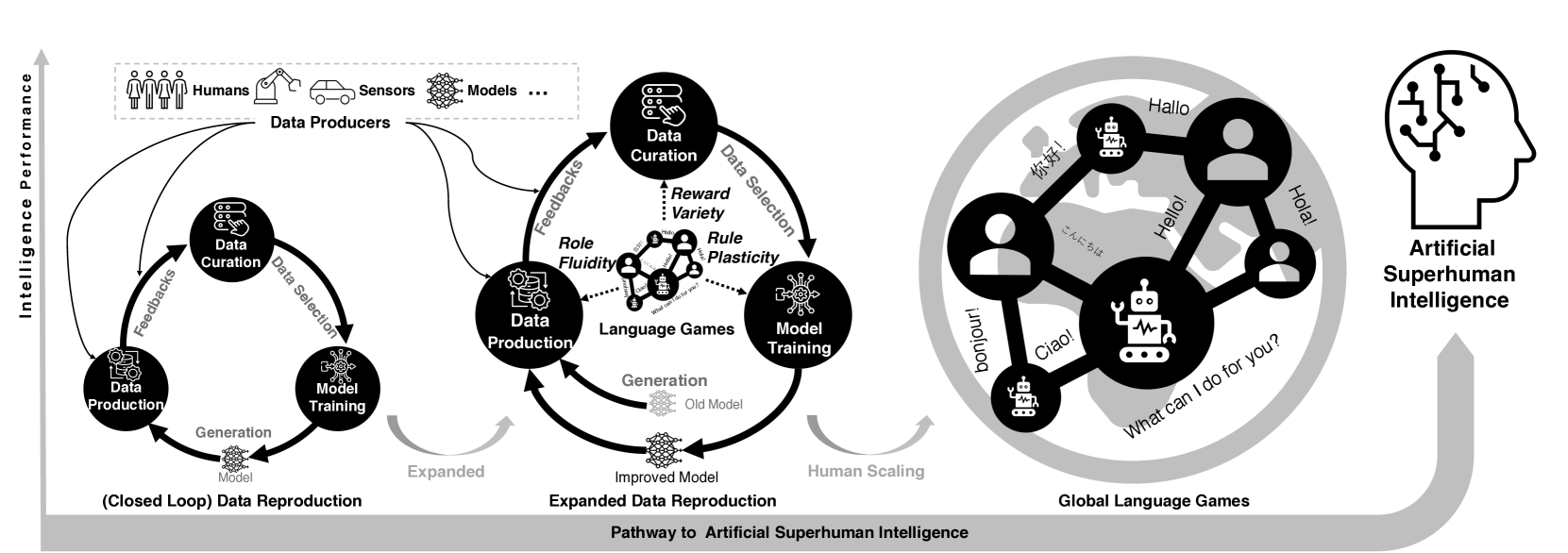
问题定义:当前大型语言模型(LLMs)的训练依赖于数据再生产,即模型生成数据,然后用这些数据进行自我训练。这种方法的痛点在于,如果模型仅仅在人类已有的数据分布上进行学习和再生产,就会陷入一个封闭的循环,无法突破现有知识的边界,导致模型能力的停滞。模型无法探索新的知识领域,最终限制了其向人工超人智能(ASI)的演进。
核心思路:论文的核心思路是利用“语言游戏”的概念,模拟人类社会中通过互动和规则演化来学习和创造新知识的过程。通过设计具有角色流动性、奖励多样性和规则可塑性的语言游戏,让模型在与环境和其他智能体的交互中,不断生成新的、多样化的数据,从而打破数据再生产的封闭循环,驱动模型能力的持续提升。这种方法借鉴了人类社会学习的开放性和创造性,为LLM的演进提供了一种新的思路。
技术框架:该框架的核心是构建一个多智能体系统,其中每个智能体扮演不同的角色,参与到特定的语言游戏中。整个流程包括以下几个主要阶段:1) 角色分配:智能体根据任务需求动态分配角色,角色具有不同的目标和行为模式。2) 游戏互动:智能体根据游戏规则进行互动,生成新的数据。3) 奖励反馈:根据智能体的行为表现,给予不同的奖励,引导智能体学习和优化策略。4) 规则演化:根据游戏的运行情况,迭代地调整游戏规则,以提高学习效率和促进新知识的产生。5) 数据再生产:将游戏生成的数据用于训练LLM,提升模型的能力。
关键创新:该论文最重要的技术创新点在于提出了“角色流动性”、“奖励多样性”和“规则可塑性”这三个机制,用于打破数据再生产的封闭循环。角色流动性允许智能体动态切换角色,从而生成更多样化的数据;奖励多样性通过引入多个反馈标准,驱动智能体学习更复杂的行为;规则可塑性则通过迭代地演化游戏规则,促进可学习性,并注入持续的新颖性。这些机制的结合,使得语言游戏能够不断产生新的知识,驱动LLM的持续演进。
关键设计:在角色流动性方面,可以采用基于强化学习的角色分配策略,让智能体根据自身能力和任务需求,选择最合适的角色。在奖励多样性方面,可以设计多个奖励函数,分别衡量智能体的不同行为表现,例如准确性、创造性和合作性。在规则可塑性方面,可以采用遗传算法或其他优化算法,迭代地调整游戏规则,以提高学习效率和促进新知识的产生。具体的参数设置和网络结构需要根据具体的语言游戏进行调整。
🖼️ 关键图片
📊 实验亮点
论文提出了角色流动性、奖励多样性和规则可塑性三种机制,旨在突破LLM数据再生产的瓶颈。虽然论文中没有给出具体的实验数据,但其提出的框架为LLM的持续学习和知识创新提供了一种新的思路,具有重要的理论价值和潜在的应用前景。未来的研究可以进一步验证该框架的有效性,并探索其在不同领域的应用。
🎯 应用场景
该研究成果具有广泛的应用前景,可应用于智能对话系统、游戏AI、教育机器人等领域。通过构建基于语言游戏的智能体,可以提升这些系统的智能水平和创造能力,使其能够更好地与人类进行互动和协作。此外,该研究还可以为人工智能的长期发展提供新的思路,推动人工超人智能的实现。
📄 摘要(原文)
The evolution of large language models (LLMs) toward artificial superhuman intelligence (ASI) hinges on data reproduction, a cyclical process in which models generate, curate and retrain on novel data to refine capabilities. Current methods, however, risk getting stuck in a data reproduction trap: optimizing outputs within fixed human-generated distributions in a closed loop leads to stagnation, as models merely recombine existing knowledge rather than explore new frontiers. In this paper, we propose language games as a pathway to expanded data reproduction, breaking this cycle through three mechanisms: (1) \textit{role fluidity}, which enhances data diversity and coverage by enabling multi-agent systems to dynamically shift roles across tasks; (2) \textit{reward variety}, embedding multiple feedback criteria that can drive complex intelligent behaviors; and (3) \textit{rule plasticity}, iteratively evolving interaction constraints to foster learnability, thereby injecting continual novelty. By scaling language games into global sociotechnical ecosystems, human-AI co-evolution generates unbounded data streams that drive open-ended exploration. This framework redefines data reproduction not as a closed loop but as an engine for superhuman intelligence.