Neural Operator based Reinforcement Learning for Control of first-order PDEs with Spatially-Varying State Delay
作者: Jiaqi Hu, Jie Qi, Jing Zhang
分类: cs.AI, eess.SY
发布日期: 2025-01-30
备注: 6 Pages, 7 Figures
💡 一句话要点
提出基于神经算子的强化学习方法,用于控制具有空间变化状态延迟的一阶偏微分方程
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 神经算子 强化学习 偏微分方程控制 空间变化延迟 反步控制 DeepONet 软演员-评论家
📋 核心要点
- 控制具有空间变化延迟的分布式参数系统是一个难题,现有方法通常需要对延迟函数进行假设。
- 论文提出结合PDE反步控制和深度强化学习,使用DeepONet近似反步控制器,从而消除对延迟函数的假设。
- 实验结果表明,该算法优于没有先验反步知识的基线SAC和解析控制器,验证了方法的有效性。
📝 摘要(中文)
本文研究了受延迟影响的分布式参数系统的控制问题,特别是当延迟依赖于空间变量时。将解析控制理论与基于学习的控制集成到统一的控制方案中,这种思想正变得越来越有希望和优势。本文通过结合偏微分方程反步控制策略和深度强化学习(RL),解决了控制具有空间变化延迟的不稳定一阶双曲偏微分方程的问题。为了消除反步设计中对延迟函数的假设,我们提出了一种软演员-评论家(SAC)架构,该架构结合了DeepONet来近似反步控制器。DeepONet从反步控制器中提取特征,并将它们输入到策略网络中。在仿真中,我们的算法优于没有先验反步知识的基线SAC和解析控制器。
🔬 方法详解
问题定义:论文旨在解决具有空间变化状态延迟的不稳定一阶双曲偏微分方程的控制问题。现有方法,如传统的反步控制,通常需要对延迟函数有明确的假设,这在实际应用中可能难以满足。因此,如何设计一种无需精确延迟函数信息的控制器是本研究的核心问题。
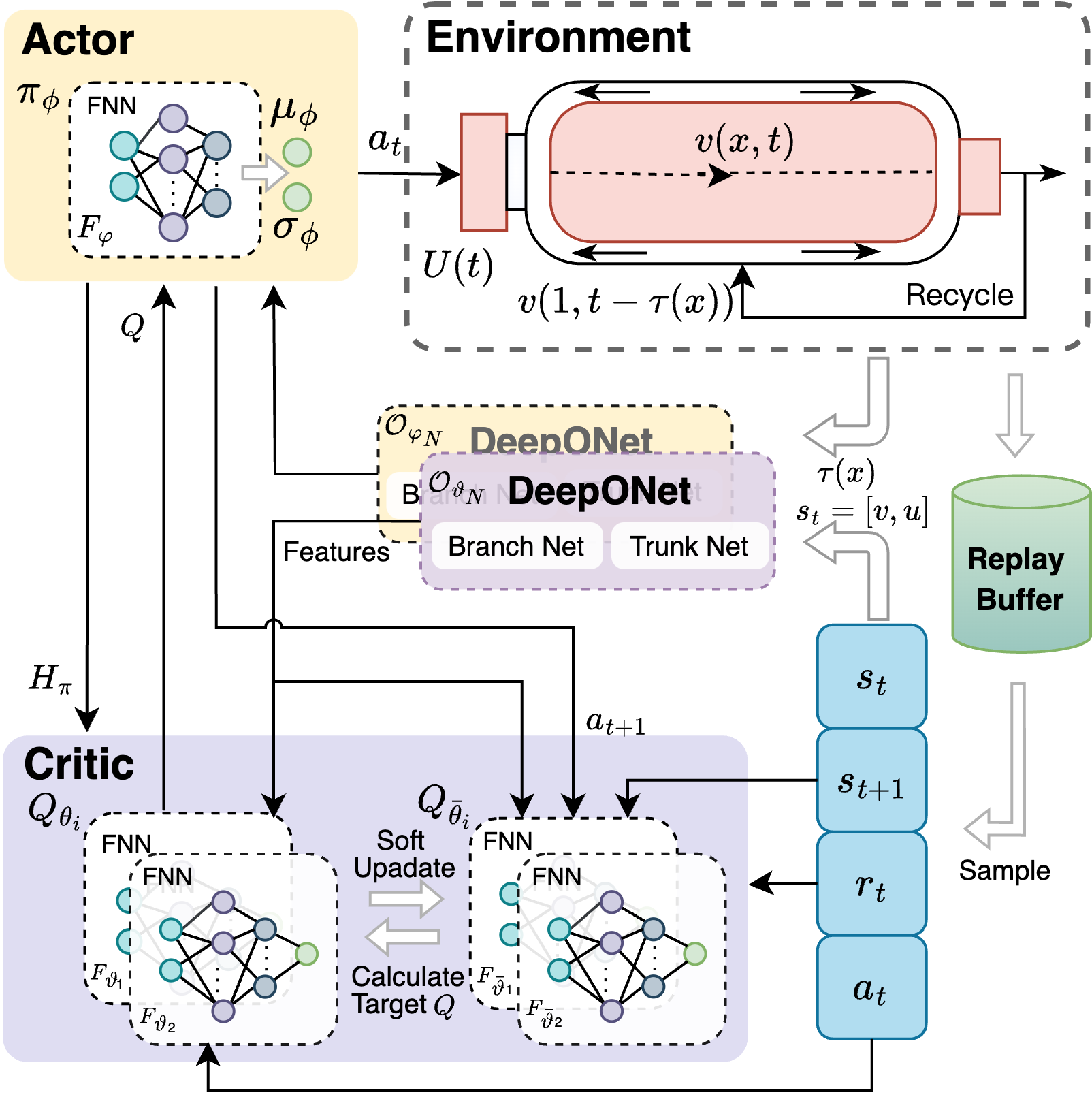
核心思路:论文的核心思路是将PDE反步控制与深度强化学习相结合。首先,利用反步控制的思想设计控制器结构,然后使用深度强化学习来学习控制器的参数,从而避免了对延迟函数的精确建模。DeepONet被用来近似反步控制器,从而提取特征并输入到策略网络中。
技术框架:整体框架包含以下几个主要模块:1) PDE系统模型;2) 基于反步控制的控制器结构设计;3) DeepONet,用于近似反步控制器;4) 软演员-评论家(SAC)算法,用于训练DeepONet。流程如下:首先,根据PDE系统模型和反步控制思想设计控制器结构。然后,使用DeepONet学习控制器参数,DeepONet的输入是空间变量,输出是控制器的参数。最后,使用SAC算法训练DeepONet,目标是最小化控制误差。
关键创新:最重要的技术创新点在于将DeepONet引入到反步控制中,用于近似反步控制器。与传统的反步控制相比,该方法不需要对延迟函数进行精确建模,从而具有更强的鲁棒性和适应性。此外,将DeepONet提取的特征输入到策略网络中,可以有效地利用反步控制的先验知识,加速强化学习的训练过程。
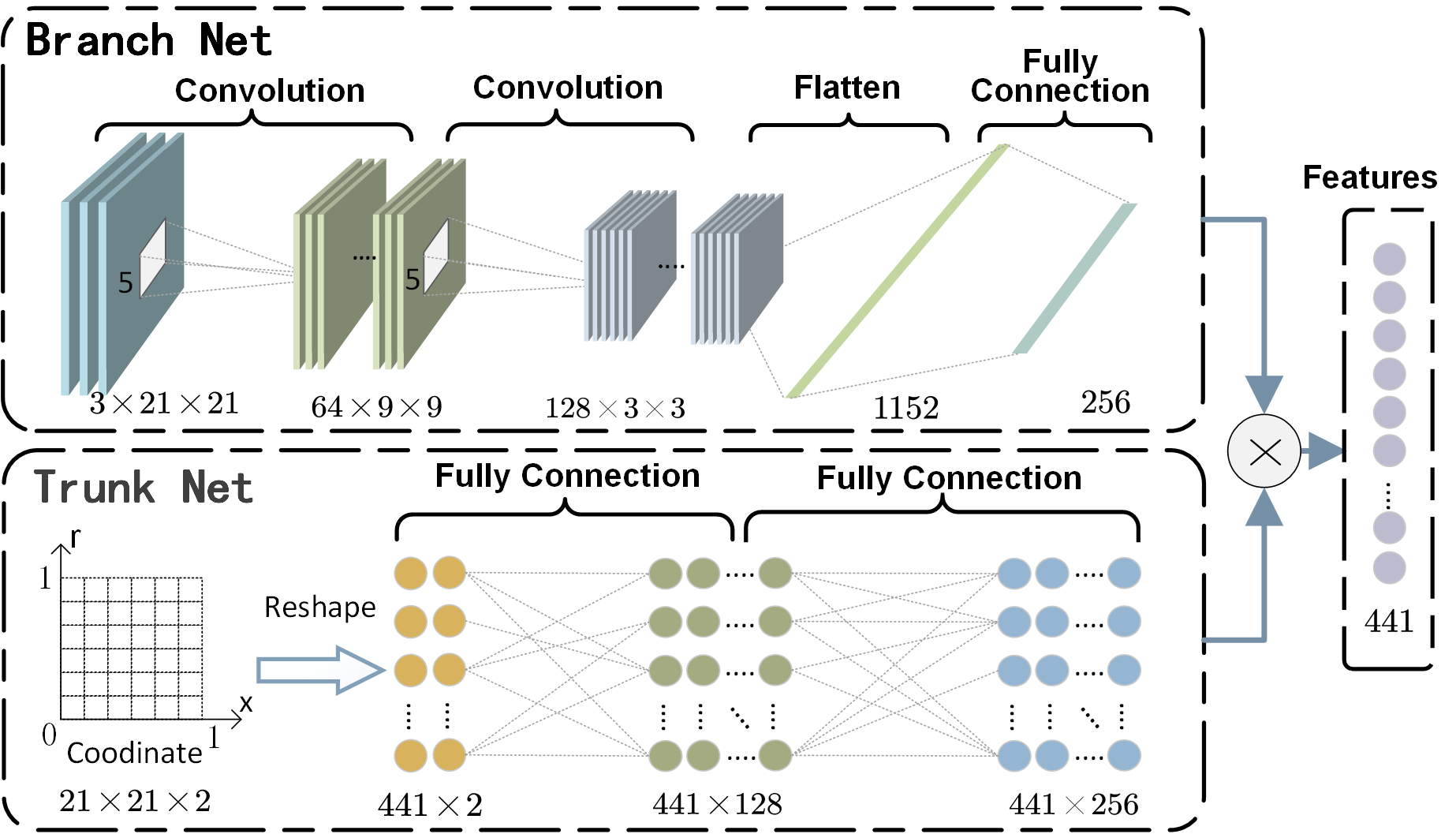
关键设计:DeepONet的网络结构包括一个branch net和一个trunk net。Branch net的输入是空间变量,trunk net的输入是时间变量。两个网络的输出通过内积运算得到DeepONet的最终输出,即反步控制器的参数。损失函数采用均方误差损失函数,目标是最小化控制误差。SAC算法采用标准的参数设置,包括学习率、折扣因子、目标网络更新频率等。具体数值未知。
🖼️ 关键图片

📊 实验亮点
仿真结果表明,所提出的算法优于基线SAC算法和解析控制器。具体来说,与没有先验反步知识的基线SAC相比,该算法能够更快地收敛到最优策略,并获得更低的控制误差。与解析控制器相比,该算法对延迟函数的不确定性具有更强的鲁棒性。具体性能提升幅度未知。
🎯 应用场景
该研究成果可应用于各种具有空间变化延迟的分布式参数系统的控制,例如管道中的流体控制、化学反应器控制、以及交通流控制等。通过学习控制策略,可以提高系统的稳定性和控制性能,降低对系统模型的依赖,具有重要的实际应用价值和潜在的未来影响。
📄 摘要(原文)
Control of distributed parameter systems affected by delays is a challenging task, particularly when the delays depend on spatial variables. The idea of integrating analytical control theory with learning-based control within a unified control scheme is becoming increasingly promising and advantageous. In this paper, we address the problem of controlling an unstable first-order hyperbolic PDE with spatially-varying delays by combining PDE backstepping control strategies and deep reinforcement learning (RL). To eliminate the assumption on the delay function required for the backstepping design, we propose a soft actor-critic (SAC) architecture incorporating a DeepONet to approximate the backstepping controller. The DeepONet extracts features from the backstepping controller and feeds them into the policy network. In simulations, our algorithm outperforms the baseline SAC without prior backstepping knowledge and the analytical controller.