Learning to Plan & Reason for Evaluation with Thinking-LLM-as-a-Judge
作者: Swarnadeep Saha, Xian Li, Marjan Ghazvininejad, Jason Weston, Tianlu Wang
分类: cs.AI, cs.CL
发布日期: 2025-01-30 (更新: 2025-07-08)
备注: ICML 2025
💡 一句话要点
提出EvalPlanner,通过规划与推理提升LLM作为裁判的评估能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM裁判 思维链 评估规划 自训练 偏好优化
📋 核心要点
- 现有LLM裁判模型缺乏人工标注数据,推理过程受限于手工设计的组件和结构,限制了其评估能力。
- EvalPlanner通过先生成无约束的评估计划,再执行并判断,解耦规划与推理,提升评估的灵活性和准确性。
- EvalPlanner在RewardBench上取得了93.9的新SOTA,并在其他基准测试中表现出优越的性能,验证了其有效性。
📝 摘要(中文)
LLM-as-a-Judge模型生成思维链(CoT)序列,旨在捕捉评估响应的逐步推理过程。然而,由于缺乏人工标注的评估CoT,有效推理轨迹所需的组件和结构仍未得到充分研究。以往方法通常(1)将推理轨迹约束为手工设计的组件,例如标准列表、参考答案或验证问题,并且(2)以规划与评估推理交织的方式构建它们。本文提出了EvalPlanner,一种用于Thinking-LLM-as-a-Judge的偏好优化算法,它首先生成无约束的评估计划,然后执行该计划,最后进行判断。在一个自训练循环中,EvalPlanner迭代地优化合成构建的评估计划和执行,从而产生更好的最终结果。我们的方法在RewardBench上实现了生成奖励模型的新state-of-the-art性能(得分为93.9),尽管训练数据量较少且是合成生成的偏好对。在RM-Bench、JudgeBench和FollowBenchEval等其他基准上的额外实验进一步突出了规划和推理对于构建鲁棒的LLM-as-a-Judge推理模型的效用。
🔬 方法详解
问题定义:现有LLM裁判模型在评估生成文本时,推理过程往往依赖于人工设计的规则或组件,例如预定义的标准列表或参考答案。这种方式限制了模型的灵活性和泛化能力,难以适应各种复杂的评估场景。此外,规划和推理交织在一起,使得模型难以有效地组织和执行评估过程。缺乏高质量的标注数据也加剧了这一问题。
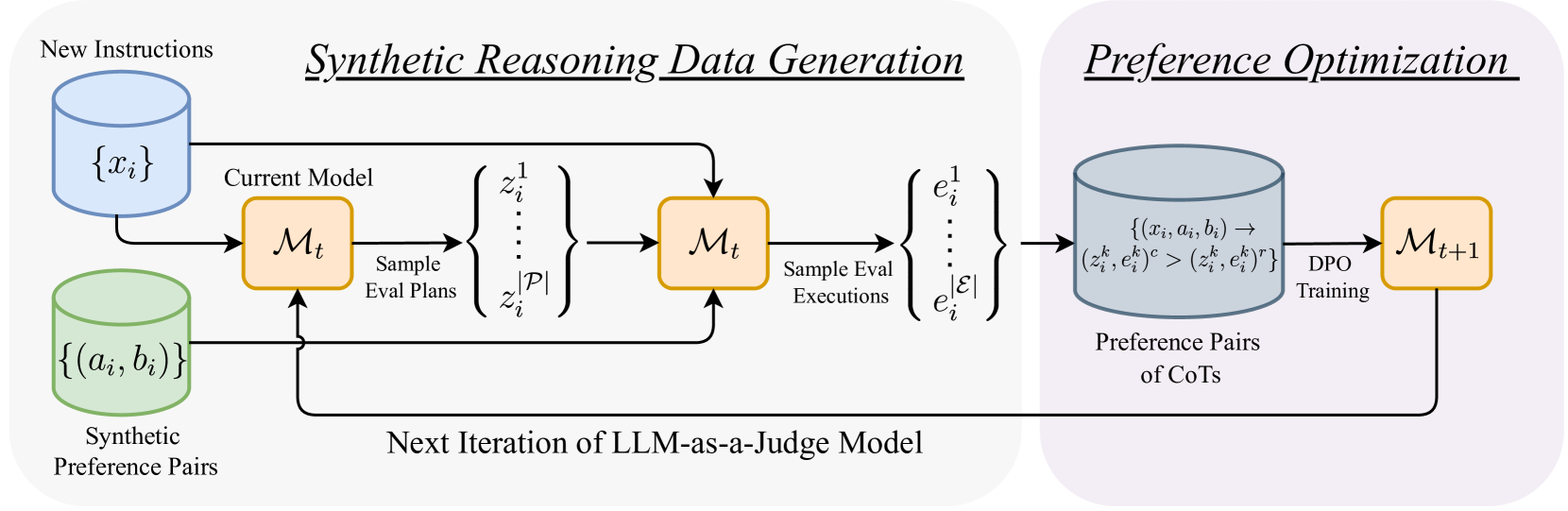
核心思路:EvalPlanner的核心思路是将评估过程解耦为规划和执行两个阶段。首先,模型生成一个无约束的评估计划,明确评估的目标和步骤。然后,模型根据该计划执行推理,并最终给出判断。这种解耦使得模型可以更灵活地组织评估过程,并更好地利用自身的知识和推理能力。通过自训练循环,模型可以不断优化评估计划和执行策略,从而提高评估的准确性和鲁棒性。
技术框架:EvalPlanner的整体框架包括三个主要模块:评估计划生成器、评估执行器和偏好优化器。评估计划生成器负责生成无约束的评估计划,可以使用LLM直接生成。评估执行器根据评估计划执行推理,并生成最终的判断结果。偏好优化器利用合成生成的偏好对,通过强化学习或监督学习的方式,优化评估计划生成器和评估执行器的参数。整个过程在一个自训练循环中迭代进行,不断提升模型的评估能力。
关键创新:EvalPlanner最重要的创新点在于将评估过程解耦为规划和执行两个阶段,并利用自训练循环优化评估计划和执行策略。与现有方法相比,EvalPlanner不再依赖于人工设计的规则或组件,而是通过学习的方式自动生成评估计划,从而提高了模型的灵活性和泛化能力。此外,EvalPlanner的自训练循环可以有效地利用未标注数据,进一步提升模型的性能。
关键设计:EvalPlanner的关键设计包括:(1) 使用LLM作为评估计划生成器和评估执行器,充分利用LLM的知识和推理能力;(2) 设计合适的奖励函数或损失函数,用于优化评估计划生成器和评估执行器的参数;(3) 设计有效的自训练策略,例如利用对抗学习或数据增强等方式,生成高质量的偏好对;(4) 探索不同的评估计划表示方式,例如使用自然语言描述或结构化表示。
🖼️ 关键图片
📊 实验亮点
EvalPlanner在RewardBench上取得了93.9的新SOTA,相比之前的SOTA模型提升显著。此外,在RM-Bench、JudgeBench和FollowBenchEval等其他基准测试中,EvalPlanner也表现出优越的性能,验证了其有效性和泛化能力。实验结果表明,规划和推理对于构建鲁棒的LLM-as-a-Judge推理模型至关重要。
🎯 应用场景
EvalPlanner可应用于各种需要自动评估生成文本的场景,例如机器翻译、文本摘要、对话生成等。它可以作为奖励模型,用于训练生成模型,提高生成文本的质量。此外,EvalPlanner还可以用于自动评估学生的作业或论文,减轻教师的负担。未来,该研究可以扩展到多模态评估,例如评估图像或视频的质量。
📄 摘要(原文)
LLM-as-a-Judge models generate chain-of-thought (CoT) sequences intended to capture the step-bystep reasoning process that underlies the final evaluation of a response. However, due to the lack of human annotated CoTs for evaluation, the required components and structure of effective reasoning traces remain understudied. Consequently, previous approaches often (1) constrain reasoning traces to hand-designed components, such as a list of criteria, reference answers, or verification questions and (2) structure them such that planning is intertwined with the reasoning for evaluation. In this work, we propose EvalPlanner, a preference optimization algorithm for Thinking-LLM-as-a-Judge that first generates an unconstrained evaluation plan, followed by its execution, and then the final judgment. In a self-training loop, EvalPlanner iteratively optimizes over synthetically constructed evaluation plans and executions, leading to better final verdicts. Our method achieves a new state-of-the-art performance for generative reward models on RewardBench (with a score of 93.9), despite being trained on fewer amount of, and synthetically generated, preference pairs. Additional experiments on other benchmarks like RM-Bench, JudgeBench, and FollowBenchEval further highlight the utility of both planning and reasoning for building robust LLM-as-a-Judge reasoning models.