VoicePrompter: Robust Zero-Shot Voice Conversion with Voice Prompt and Conditional Flow Matching
作者: Ha-Yeong Choi, Jaehan Park
分类: cs.SD, cs.AI, eess.AS, eess.SP
发布日期: 2025-01-29
备注: Accepted at ICASSP 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
VoicePrompter:基于语音提示和条件流匹配的鲁棒零样本语音转换
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语音转换 零样本学习 语音提示 条件流匹配 扩散模型 上下文学习 说话人相似度
📋 核心要点
- 零样本语音转换中,泛化和适应语音中的说话人特征具有挑战性,训练和推理过程的不匹配加剧了这一问题。
- VoicePrompter利用语音提示进行上下文学习,通过分解语音成分和条件流匹配解码器,实现更鲁棒的零样本语音转换。
- 通过潜在混合增强上下文学习,VoicePrompter在说话人相似度、语音清晰度和音频质量方面优于现有方法。
📝 摘要(中文)
本文提出了一种名为VoicePrompter的鲁棒零样本语音转换模型,旨在解决零样本场景下提升说话人相似度的难题。该模型利用语音提示进行上下文学习,由以下三个部分组成:(1) 解耦语音成分的分解方法;(2) 基于DiT的条件流匹配(CFM)解码器,该解码器以分解后的特征和语音提示为条件;(3) 潜在混合(latent mixup),通过组合不同的说话人特征来增强上下文学习。通过在潜在表示上应用混合,该方法提高了零样本语音转换中的说话人相似度和自然度。实验结果表明,VoicePrompter在说话人相似度、语音清晰度和音频质量方面优于现有的零样本语音转换系统。
🔬 方法详解
问题定义:零样本语音转换旨在将源语音的内容转换为目标说话人的声音,而无需目标说话人的训练数据。现有的零样本语音转换方法在说话人相似度方面表现不佳,尤其是在训练和推理阶段存在不匹配的情况下。这些方法难以有效地泛化和适应新的说话人特征。
核心思路:VoicePrompter的核心思路是利用语音提示进行上下文学习,从而更好地捕捉目标说话人的特征。通过将目标说话人的语音片段作为提示输入模型,模型可以更好地学习目标说话人的音色和韵律等特征,从而提高转换后的语音与目标说话人的相似度。此外,通过解耦语音内容和说话人特征,并使用条件流匹配解码器,可以更精确地控制转换过程。
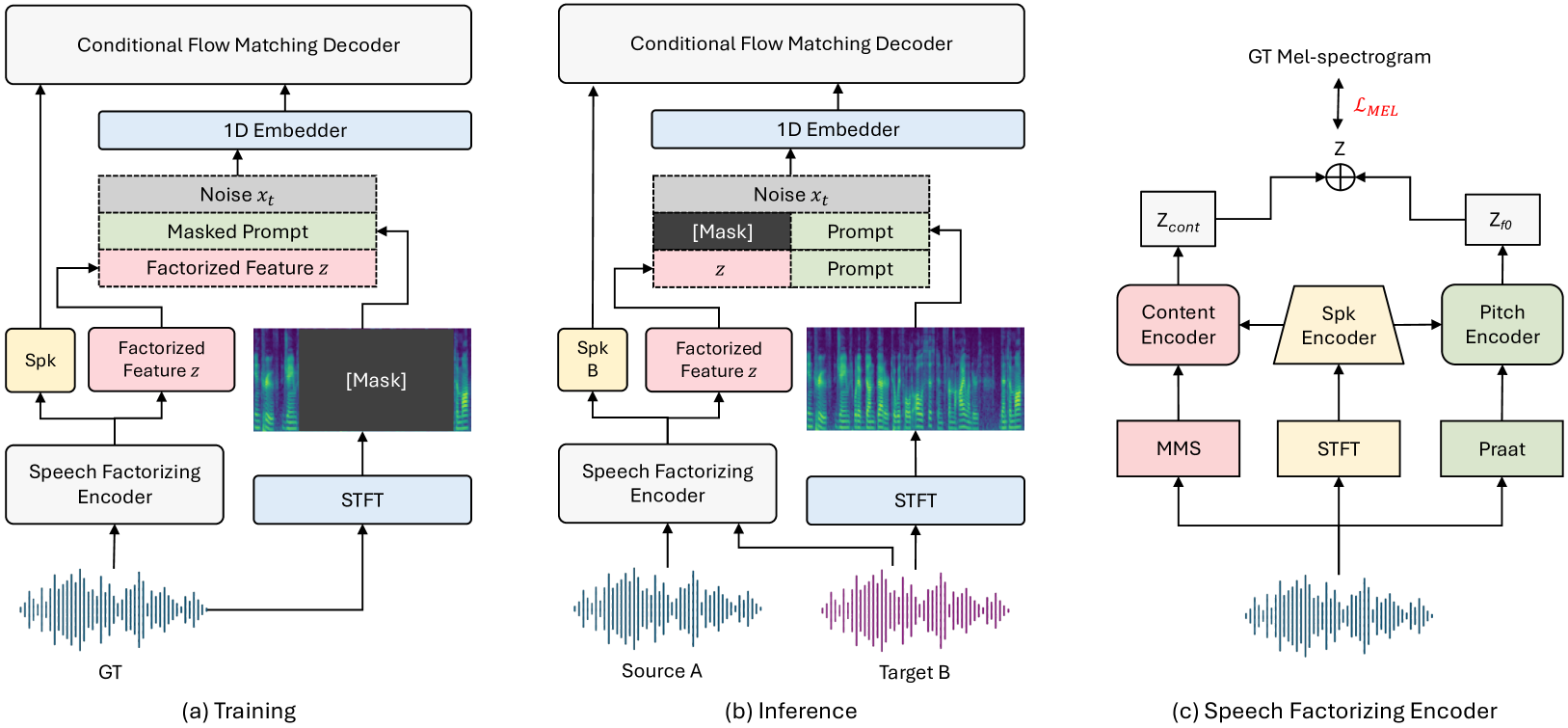
技术框架:VoicePrompter的整体框架包括三个主要模块:(1) 语音成分分解模块,用于将源语音分解为内容特征和说话人特征;(2) 基于DiT的条件流匹配(CFM)解码器,该解码器以分解后的特征和语音提示为条件,生成转换后的语音;(3) 潜在混合模块,用于通过组合不同的说话人特征来增强上下文学习。整个流程是:首先,源语音通过分解模块提取特征;然后,将提取的特征和目标说话人的语音提示输入到CFM解码器中;最后,解码器生成转换后的语音。
关键创新:VoicePrompter的关键创新在于以下几点:(1) 利用语音提示进行上下文学习,从而更好地捕捉目标说话人的特征;(2) 使用基于DiT的条件流匹配解码器,可以更精确地控制转换过程;(3) 引入潜在混合,通过组合不同的说话人特征来增强上下文学习。与现有方法相比,VoicePrompter能够更有效地泛化到新的说话人,并生成更高质量的转换语音。
关键设计:在语音成分分解模块中,使用了预训练的语音识别模型和说话人识别模型来提取内容特征和说话人特征。CFM解码器基于扩散模型,通过逐步添加噪声并学习逆过程来生成语音。潜在混合模块通过随机组合不同的说话人特征来增加训练数据的多样性。损失函数包括重建损失、对抗损失和说话人相似度损失,用于优化模型的性能。具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,VoicePrompter在说话人相似度、语音清晰度和音频质量方面均优于现有的零样本语音转换系统。具体而言,VoicePrompter在说话人相似度方面取得了显著提升,能够生成更接近目标说话人声音的转换语音。同时,VoicePrompter还能够保持较高的语音清晰度和自然度,避免了传统方法中常见的语音失真和噪声问题。具体的性能数据未知。
🎯 应用场景
VoicePrompter具有广泛的应用前景,包括个性化语音助手、语音克隆、娱乐内容创作、辅助言语治疗等。该技术可以用于创建具有特定说话人声音的语音合成系统,也可以用于改变现有语音的说话人特征。此外,该技术还可以用于帮助言语障碍患者恢复或改善语音功能。未来,VoicePrompter有望在人机交互、内容生成和医疗健康等领域发挥重要作用。
📄 摘要(原文)
Despite remarkable advancements in recent voice conversion (VC) systems, enhancing speaker similarity in zero-shot scenarios remains challenging. This challenge arises from the difficulty of generalizing and adapting speaker characteristics in speech within zero-shot environments, which is further complicated by mismatch between the training and inference processes. To address these challenges, we propose VoicePrompter, a robust zero-shot VC model that leverages in-context learning with voice prompts. VoicePrompter is composed of (1) a factorization method that disentangles speech components and (2) a DiT-based conditional flow matching (CFM) decoder that conditions on these factorized features and voice prompts. Additionally, (3) latent mixup is used to enhance in-context learning by combining various speaker features. This approach improves speaker similarity and naturalness in zero-shot VC by applying mixup to latent representations. Experimental results demonstrate that VoicePrompter outperforms existing zero-shot VC systems in terms of speaker similarity, speech intelligibility, and audio quality. Our demo is available at \url{https://hayeong0.github.io/VoicePrompter-demo/}.