Graph of Attacks with Pruning: Optimizing Stealthy Jailbreak Prompt Generation for Enhanced LLM Content Moderation
作者: Daniel Schwartz, Dmitriy Bespalov, Zhe Wang, Ninad Kulkarni, Yanjun Qi
分类: cs.CR, cs.AI, cs.CL
发布日期: 2025-01-28 (更新: 2025-11-12)
备注: 14 pages, 5 figures; published in EMNLP 2025 ; Code at: https://github.com/dsbuddy/GAP-LLM-Safety
🔗 代码/项目: GITHUB
💡 一句话要点
提出GAP框架,通过图结构优化对抗性提示生成,提升LLM内容审核能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对抗攻击 Jailbreak攻击 内容审核 图神经网络
📋 核心要点
- 现有基于树的LLM jailbreak方法存在攻击路径信息孤立,难以有效利用跨路径知识的局限性。
- GAP框架采用图结构连接不同的攻击路径,实现知识共享,并通过剪枝优化搜索效率,提升jailbreak提示的生成质量。
- 实验表明,GAP在攻击成功率和查询效率上均优于现有方法,并能有效提升内容审核系统的性能。
📝 摘要(中文)
本文提出了一种名为GAP(Graph of Attacks with Pruning)的框架,用于生成隐蔽的jailbreak提示,以评估和增强大型语言模型(LLM)的安全性。GAP通过实现互连的图结构,克服了现有基于树的LLM jailbreak方法的局限性,从而实现跨攻击路径的知识共享。实验结果表明,GAP优于现有技术,攻击成功率提高了20.8%,同时查询成本降低了62.7%。GAP在攻击开放和封闭LLM方面始终优于最先进的方法,攻击成功率>96%。此外,我们还提出了专门的变体,如用于自动种子生成的GAP-Auto和用于多模态攻击的GAP-VLM。GAP生成的提示在改进内容审核系统方面非常有效,当用于微调时,真阳性检测率提高了108.5%,准确率提高了183.6%。我们的实现可在https://github.com/dsbuddy/GAP-LLM-Safety上找到。
🔬 方法详解
问题定义:当前针对LLM的对抗攻击,特别是jailbreak攻击,旨在绕过模型的安全防护机制,使其生成有害或不当内容。现有的基于树结构的攻击方法,例如AutoDAN等,在探索攻击空间时,各个分支之间缺乏信息共享,导致效率较低,且容易陷入局部最优。因此,如何更有效地生成能够绕过LLM安全防护的对抗性提示,是一个重要的研究问题。
核心思路:GAP的核心思路是将攻击过程建模成一个图结构,图中的节点代表不同的提示,边代表对提示的修改操作。通过图结构,不同的攻击路径可以相互连接,实现知识共享。同时,GAP采用剪枝策略,移除不太可能成功的路径,从而提高搜索效率。这种图结构和剪枝策略的结合,使得GAP能够更有效地探索攻击空间,找到更隐蔽、更有效的jailbreak提示。
技术框架:GAP框架主要包含以下几个模块:1) 图构建模块:根据初始种子提示,通过一系列的修改操作(例如添加、删除、替换词语)生成新的提示,并将这些提示添加到图中。2) 评估模块:使用目标LLM评估每个提示的攻击效果,例如判断是否生成了有害内容。3) 剪枝模块:根据提示的攻击效果和一些启发式规则,移除图中不太可能成功的路径,从而减少搜索空间。4) 优化模块:利用图结构中的信息,例如不同路径的相似性,对提示进行进一步优化,提高攻击成功率。
关键创新:GAP最重要的技术创新点在于其图结构的引入。与传统的树结构相比,图结构能够更好地表示攻击空间,并允许不同攻击路径之间进行信息共享。此外,GAP的剪枝策略也能够有效地减少搜索空间,提高攻击效率。这种图结构和剪枝策略的结合,使得GAP能够更有效地生成对抗性提示。与现有方法的本质区别在于,GAP不再是孤立地探索攻击路径,而是通过图结构将它们连接起来,从而实现知识共享和协同优化。
关键设计:GAP的关键设计包括:1) 图的表示:如何有效地表示提示和修改操作,以及如何将它们组织成图结构。2) 剪枝策略:如何选择合适的剪枝规则,以在保证攻击成功率的同时,减少搜索空间。3) 优化算法:如何利用图结构中的信息,对提示进行进一步优化。例如,可以使用图神经网络来学习提示的表示,并根据其在图中的位置和邻居节点的特征,预测其攻击效果。此外,GAP还提出了GAP-Auto和GAP-VLM等变体,分别用于自动种子生成和多模态攻击。
🖼️ 关键图片

📊 实验亮点
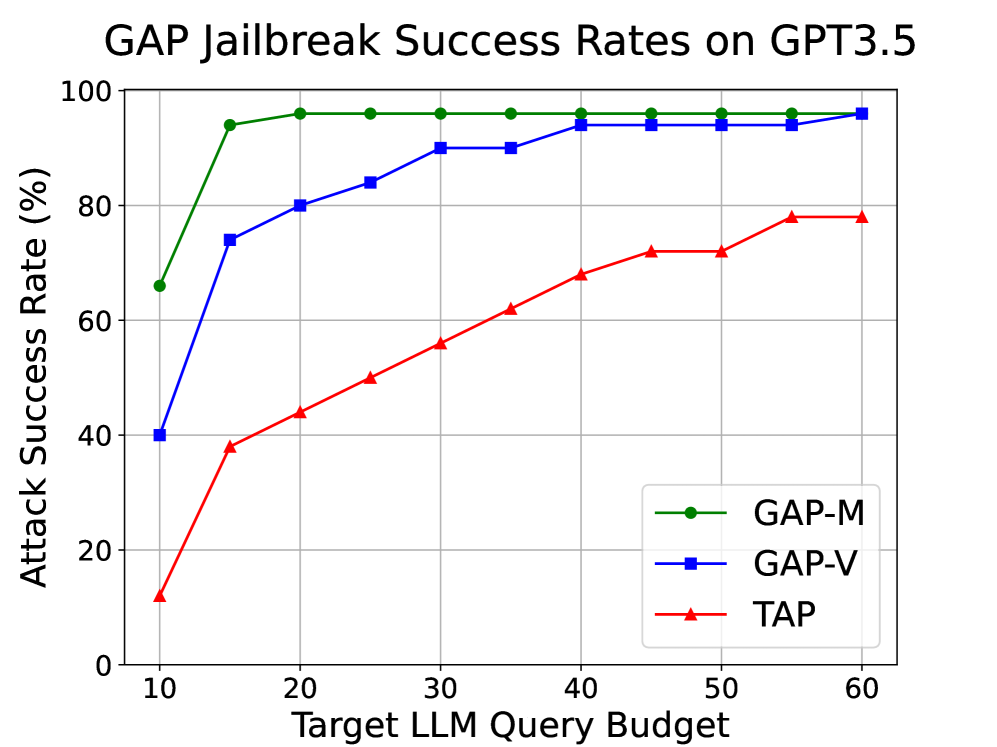
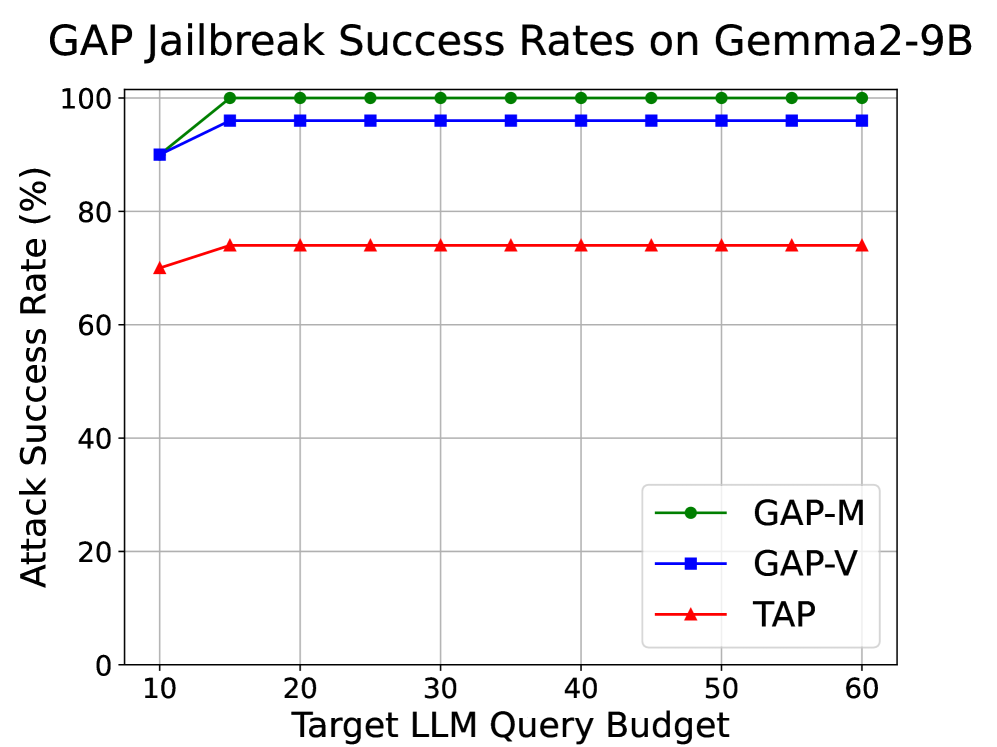
GAP在攻击LLM方面取得了显著的性能提升。实验结果表明,GAP的攻击成功率比现有方法提高了20.8%,同时查询成本降低了62.7%。在攻击开放和封闭LLM时,GAP的攻击成功率均超过96%。此外,使用GAP生成的提示对内容审核系统进行微调后,真阳性检测率提高了108.5%,准确率提高了183.6%。这些结果表明,GAP是一种非常有效的对抗性提示生成方法,可以显著提升LLM的安全性和内容审核能力。
🎯 应用场景
GAP框架生成的对抗性提示可以用于评估和增强LLM的内容审核系统。通过使用这些提示对内容审核模型进行微调,可以提高模型对恶意内容的检测能力,从而减少LLM被滥用的风险。此外,GAP还可以用于评估不同LLM的安全防护能力,帮助开发者发现和修复潜在的安全漏洞。该研究对于构建更安全、更可靠的LLM应用具有重要意义。
📄 摘要(原文)
As large language models (LLMs) become increasingly prevalent, ensuring their robustness against adversarial misuse is crucial. This paper introduces the GAP (Graph of Attacks with Pruning) framework, an advanced approach for generating stealthy jailbreak prompts to evaluate and enhance LLM safeguards. GAP addresses limitations in existing tree-based LLM jailbreak methods by implementing an interconnected graph structure that enables knowledge sharing across attack paths. Our experimental evaluation demonstrates GAP's superiority over existing techniques, achieving a 20.8% increase in attack success rates while reducing query costs by 62.7%. GAP consistently outperforms state-of-the-art methods for attacking both open and closed LLMs, with attack success rates of >96%. Additionally, we present specialized variants like GAP-Auto for automated seed generation and GAP-VLM for multimodal attacks. GAP-generated prompts prove highly effective in improving content moderation systems, increasing true positive detection rates by 108.5% and accuracy by 183.6% when used for fine-tuning. Our implementation is available at https://github.com/dsbuddy/GAP-LLM-Safety.