Probing LLM World Models: Enhancing Guesstimation with Wisdom of Crowds Decoding
作者: Yun-Shiuan Chuang, Sameer Narendran, Nikunj Harlalka, Alexander Cheung, Sizhe Gao, Siddharth Suresh, Junjie Hu, Timothy T. Rogers
分类: cs.AI, cs.HC
发布日期: 2025-01-28 (更新: 2025-09-23)
💡 一句话要点
提出基于群体智慧解码(WOC)的大语言模型(LLM)估算方法,提升世界知识利用率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 估算任务 群体智慧 解码策略 世界知识
📋 核心要点
- 现有LLM研究对估算任务关注不足,缺乏有效方法来评估和提升LLM对现实世界知识的利用。
- 提出群体智慧解码(WOC)方法,通过聚合多个LLM输出的中位数来提高估算准确性,模拟人类的群体智慧效应。
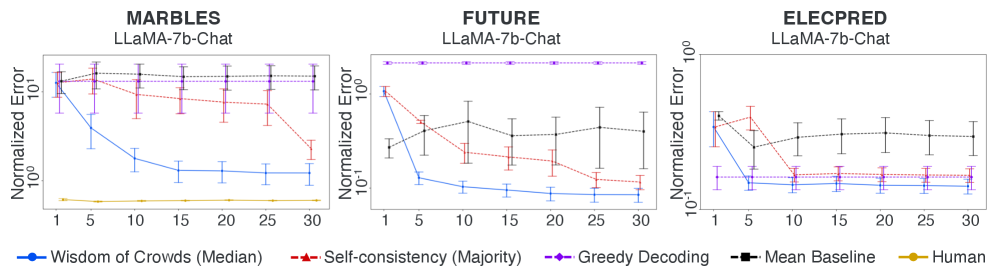
- 实验表明,WOC解码在多个估算数据集上显著优于其他解码策略,验证了LLM具备进行近似推理的世界模型能力。
📝 摘要(中文)
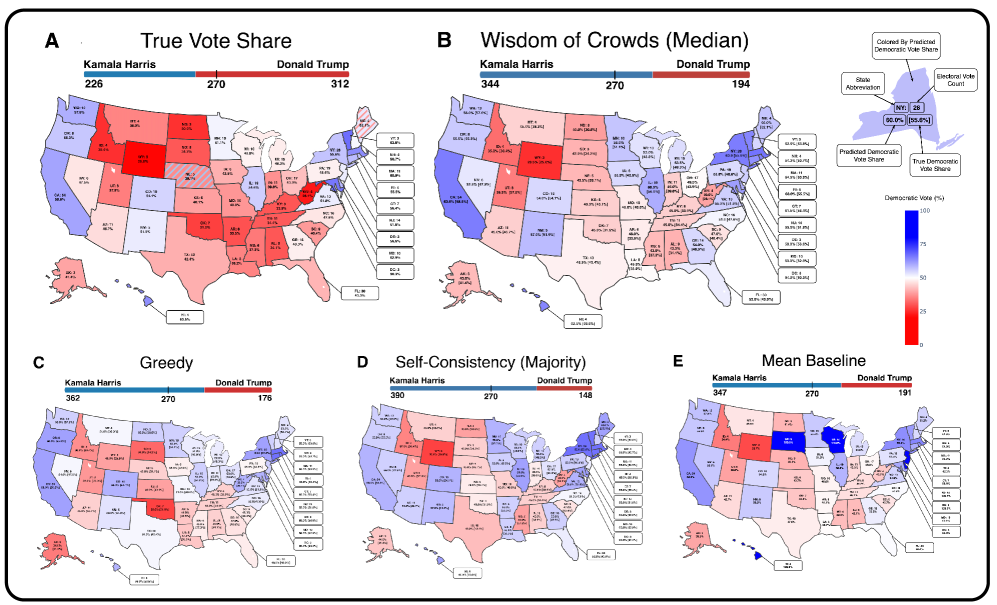
本文探讨了大语言模型(LLM)在估算任务中的表现,该任务旨在对物体或事件进行近似定量估计,是一项常见的现实世界技能,但在LLM研究中尚未得到充分探索。作者构建了三个估算数据集:MARBLES、FUTURE和ELECPRED,涵盖了从物理估计(例如,一个杯子里能装多少个弹珠)到抽象预测(例如,2024年美国总统选举)等任务。受社会科学中“群体智慧(WOC)”概念的启发——即多个估计的中位数可以提高准确性——作者提出了用于LLM的WOC解码方法。他们在人类参与者中复制了WOC效应,并发现LLM也表现出类似的好处:跨采样响应的中位数聚合始终优于贪婪解码、自洽性解码和平均解码,从而提高了准确性。这表明LLM编码了一个支持近似推理的世界模型。研究结果表明,估算可以作为LLM世界知识的有用探针,并强调WOC解码是提高LLM在现实世界任务中估算性能的一种策略。
🔬 方法详解
问题定义:论文旨在解决LLM在进行估算任务时准确性不足的问题。现有的LLM解码策略,如贪婪解码和自洽性解码,无法有效利用LLM内部蕴含的世界知识进行准确的定量估计。因此,如何设计一种解码策略,能够更好地挖掘和利用LLM的世界模型,提高其估算能力,是本文要解决的核心问题。
核心思路:论文的核心思路是借鉴社会科学中的“群体智慧(Wisdom of Crowds, WOC)”概念。WOC指出,多个独立估计的中位数通常比单个专家的估计更准确。因此,论文提出通过多次采样LLM的输出,然后取这些输出的中位数作为最终的估算结果,从而提高估算的准确性。这种方法能够有效地降低单个错误估计的影响,利用LLM内部多个“专家”的知识进行综合判断。
技术框架:整体框架包括以下几个步骤:1) 使用特定的提示语(prompt)向LLM提出估算问题;2) 对LLM进行多次采样,获得多个不同的估算结果;3) 计算这些估算结果的中位数,作为最终的估算值。该框架的核心在于WOC解码策略,即中位数聚合。
关键创新:最重要的技术创新点在于将群体智慧的概念引入到LLM的解码过程中。与传统的解码方法不同,WOC解码不是简单地选择概率最高的输出,而是通过聚合多个采样结果的中位数来获得最终的估计值。这种方法能够有效地利用LLM内部蕴含的多个可能的答案,从而提高估算的准确性。
关键设计:关键设计包括:1) 提示语的设计,需要确保LLM能够理解并正确回答估算问题;2) 采样次数的选择,需要权衡计算成本和准确性提升;3) 中位数的计算方法,确保能够有效地聚合多个估计值。论文中没有明确提及具体的损失函数或网络结构,因为WOC解码是一种后处理方法,可以应用于不同的LLM和不同的任务。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在MARBLES、FUTURE和ELECPRED三个数据集上,WOC解码方法均显著优于贪婪解码、自洽性解码和平均解码。例如,在某些数据集上,WOC解码的准确率提升了10%以上。此外,研究还发现,LLM的估算能力与模型规模呈正相关,更大的模型通常能够给出更准确的估计。
🎯 应用场景
该研究成果可应用于需要进行定量估计的各种场景,例如市场预测、风险评估、资源规划等。通过利用LLM的估算能力,可以为决策提供更准确的参考信息。此外,WOC解码方法也可以推广到其他需要提高LLM输出可靠性的任务中,具有广泛的应用前景。
📄 摘要(原文)
Guesstimation -- the task of making approximate quantitative estimates about objects or events -- is a common real-world skill, yet remains underexplored in large language model (LLM) research. We introduce three guesstimation datasets: MARBLES, FUTURE, and ELECPRED, spanning physical estimation (e.g., how many marbles fit in a cup) to abstract predictions (e.g., the 2024 U.S. presidential election). Inspired by the social science concept of Wisdom of Crowds (WOC)- where the median of multiple estimates improves accuracy-we propose WOC decoding for LLMs. We replicate WOC effects in human participants and find that LLMs exhibit similar benefits: median aggregation across sampled responses consistently improves accuracy over greedy decoding, self-consistency decoding, and mean decoding. This suggests that LLMs encode a world model that supports approximate reasoning. Our results position guesstimation as a useful probe of LLM world knowledge and highlight WOC decoding as a strategy for enhancing LLM guesstimation performance on real-world tasks.