From Natural Language to Extensive-Form Game Representations
作者: Shilong Deng, Yongzhao Wang, Rahul Savani
分类: cs.AI, cs.CL, cs.GT, cs.MA
发布日期: 2025-01-28 (更新: 2025-01-31)
备注: This work has been accepted as a full paper for AAMAS 2025. This is a full version of the AAMAS 2025 proceedings
💡 一句话要点
提出一种基于LLM和上下文学习的框架,将自然语言博弈描述转换为扩展式博弈表示
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言处理 博弈论 扩展式博弈 大型语言模型 上下文学习
📋 核心要点
- 现有方法难以将自然语言博弈描述有效转换为扩展式博弈表示,尤其是在处理不完全信息博弈时。
- 该框架采用两阶段方法,首先识别信息集和部分树结构,然后利用上下文学习和自调试生成完整博弈树。
- 实验表明,该框架在生成准确的扩展式博弈方面显著优于基线模型,证明了各模块的关键作用。
📝 摘要(中文)
本文介绍了一个框架,利用大型语言模型(LLMs)和上下文学习,将自然语言描述的博弈转换为博弈论中的扩展式表示。考虑到博弈策略复杂性的不同层次,例如完全信息与不完全信息博弈,直接应用上下文学习是不够的。为了解决这个问题,我们引入了一个具有专用模块的两阶段框架,以增强上下文学习,使其能够有效地分而治之。在第一阶段,我们通过开发一个识别信息集及其对应的部分树结构的模块来解决不完全信息带来的挑战。有了这些信息,第二阶段利用上下文学习和一个自调试模块来生成一个完整的扩展式博弈树,该博弈树使用pygambit(Gambit的Python API,Gambit是一个公认的博弈论分析工具)表示。使用这种Python表示可以自动执行诸如直接从自然语言描述中计算纳什均衡等任务。我们使用各种LLM在不同策略复杂程度的博弈上评估了完整框架及其各个组件的性能。实验结果表明,该框架在生成准确的扩展式博弈方面明显优于基线模型,并且每个模块都在其成功中发挥了关键作用。
🔬 方法详解
问题定义:论文旨在解决将自然语言描述的博弈转换为扩展式博弈表示的问题。现有方法,特别是直接应用上下文学习的方法,在处理具有不完全信息的复杂博弈时表现不足,无法准确捕捉博弈中的信息集和策略关系。这限制了从自然语言描述中自动进行博弈分析和求解的能力。
核心思路:论文的核心思路是将问题分解为两个阶段,并针对每个阶段设计专门的模块来增强上下文学习的效果。第一阶段专注于识别不完全信息博弈中的信息集,构建部分博弈树结构。第二阶段则利用第一阶段的结果,结合上下文学习和自调试机制,生成完整的扩展式博弈树。这种分而治之的策略能够更有效地处理复杂博弈,提高转换的准确性。
技术框架:该框架包含两个主要阶段:信息集识别和完整博弈树生成。第一阶段,信息集识别模块利用LLM识别博弈描述中的信息集,并构建对应的部分博弈树结构。第二阶段,完整博弈树生成模块利用第一阶段的结果,结合上下文学习和自调试机制,生成完整的扩展式博弈树,并使用pygambit进行表示。自调试模块用于纠正LLM生成的错误,提高博弈树的准确性。
关键创新:该论文的关键创新在于提出了一个两阶段框架,专门针对不完全信息博弈的转换问题进行优化。通过信息集识别模块和自调试模块,显著提高了LLM在生成扩展式博弈表示方面的准确性和可靠性。与直接应用上下文学习的方法相比,该框架能够更好地处理复杂博弈,并生成更准确的博弈表示。
关键设计:信息集识别模块的设计依赖于LLM的理解能力,通过精心设计的prompt来引导LLM识别信息集。自调试模块则通过分析LLM生成的博弈树,检测潜在的错误,并利用LLM进行纠正。框架使用pygambit作为博弈树的表示工具,方便后续的博弈分析和求解。具体的参数设置和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
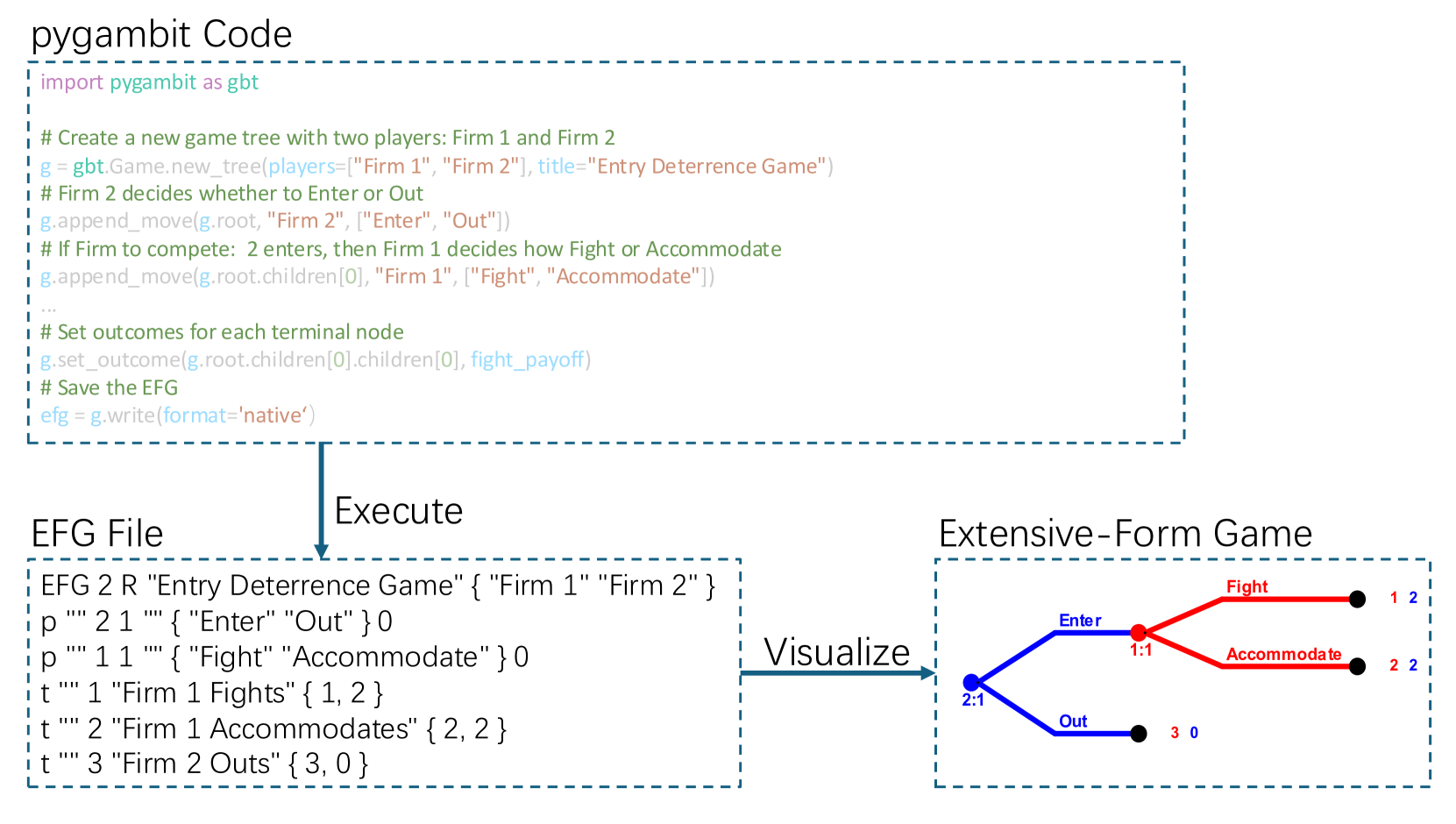
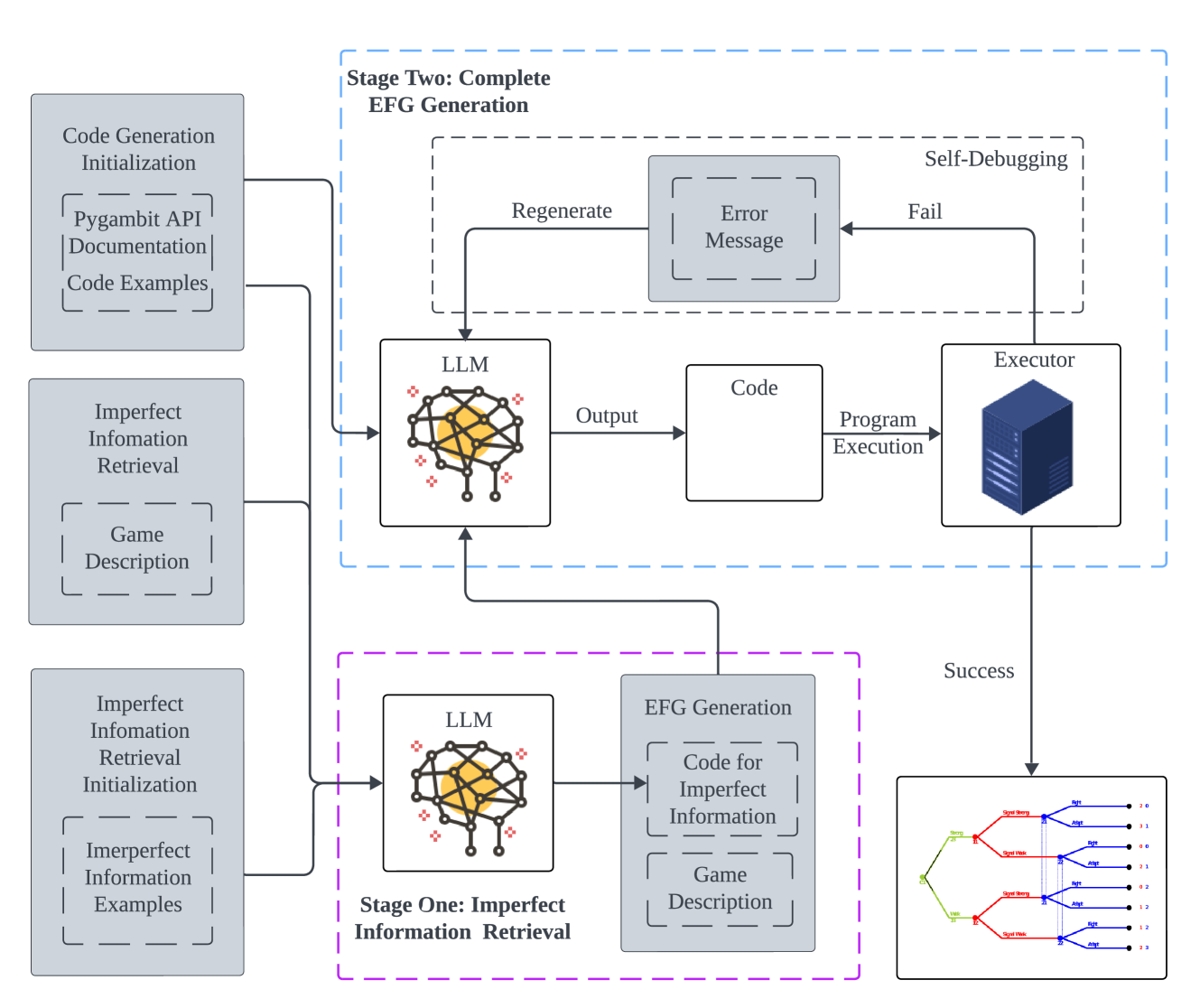
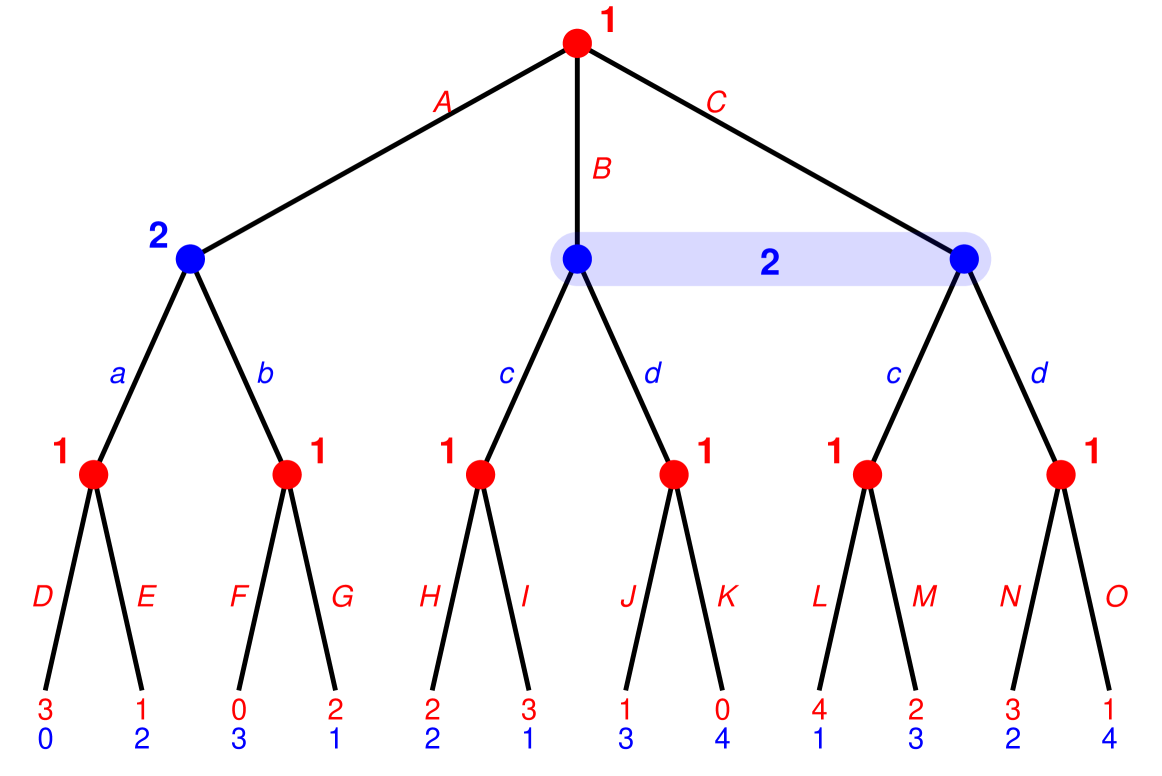
📊 实验亮点
实验结果表明,该框架在生成准确的扩展式博弈方面显著优于基线模型。具体性能数据和提升幅度在摘要中未明确给出,属于未知信息。但论文强调,框架中的每个模块都对其成功起到了关键作用,证明了该框架的有效性。
🎯 应用场景
该研究成果可应用于自动化博弈建模、策略游戏AI开发、谈判策略分析等领域。通过将自然语言描述的博弈自动转换为扩展式表示,可以方便地进行博弈分析和求解,为决策者提供更有效的支持。未来,该技术可进一步扩展到更复杂的博弈场景,例如多智能体系统和经济模型。
📄 摘要(原文)
We introduce a framework for translating game descriptions in natural language into extensive-form representations in game theory, leveraging Large Language Models (LLMs) and in-context learning. Given the varying levels of strategic complexity in games, such as perfect versus imperfect information, directly applying in-context learning would be insufficient. To address this, we introduce a two-stage framework with specialized modules to enhance in-context learning, enabling it to divide and conquer the problem effectively. In the first stage, we tackle the challenge of imperfect information by developing a module that identifies information sets along and the corresponding partial tree structure. With this information, the second stage leverages in-context learning alongside a self-debugging module to produce a complete extensive-form game tree represented using pygambit, the Python API of a recognized game-theoretic analysis tool called Gambit. Using this python representation enables the automation of tasks such as computing Nash equilibria directly from natural language descriptions. We evaluate the performance of the full framework, as well as its individual components, using various LLMs on games with different levels of strategic complexity. Our experimental results show that the framework significantly outperforms baseline models in generating accurate extensive-form games, with each module playing a critical role in its success.