MCTS-SQL: Light-Weight LLMs can Master the Text-to-SQL through Monte Carlo Tree Search
作者: Shuozhi Yuan, Limin Chen, Miaomiao Yuan, Zhao Jin
分类: cs.DB, cs.AI, cs.CL, cs.PL
发布日期: 2025-01-28 (更新: 2025-11-27)
备注: Accepted by AAAI 2026
💡 一句话要点
提出MCTS-SQL框架,利用蒙特卡洛树搜索提升轻量级LLM在Text-to-SQL任务上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text-to-SQL 蒙特卡洛树搜索 轻量级LLM SQL生成 数据库查询
📋 核心要点
- 现有Text-to-SQL方法依赖于参数量巨大的LLM或昂贵的API,难以在资源受限的环境中应用,轻量级模型的性能有待提升。
- MCTS-SQL框架利用蒙特卡洛树搜索指导SQL生成,通过多步细化和反馈机制,提升轻量级模型在Text-to-SQL任务上的性能。
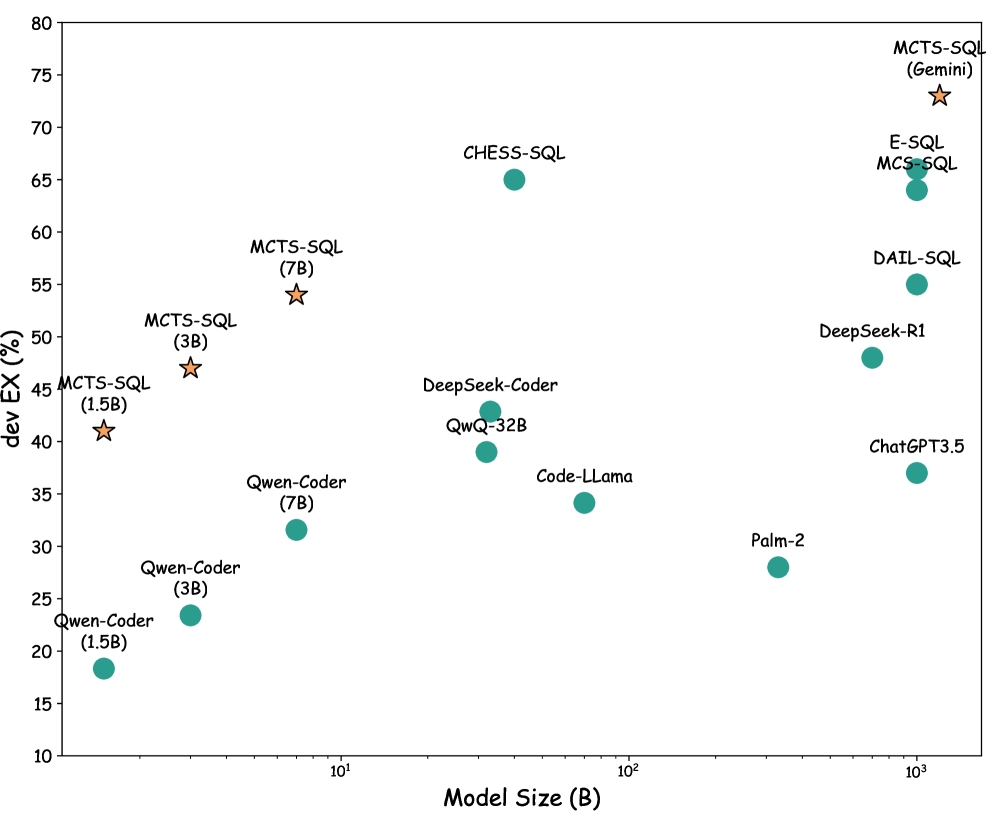
- 实验结果表明,使用Qwen2.5-Coder-1.5B模型,MCTS-SQL优于ChatGPT-3.5,使用Gemini 2.5模型时,性能可与SOTA模型竞争。
📝 摘要(中文)
Text-to-SQL是自然语言处理领域一项基础但具有挑战性的任务,旨在将自然语言问题翻译成SQL查询。虽然大型语言模型(LLM)的最新进展极大地提高了性能,但现有方法大多依赖于具有数百亿参数的模型或昂贵的API,限制了它们在资源受限环境中的适用性。对于现实世界,尤其是在边缘设备上,Text-to-SQL的成本效益至关重要。因此,使轻量级模型能够用于Text-to-SQL具有重要的实际意义。然而,较小的LLM通常难以处理复杂的用户指令、冗余的模式链接或语法正确性。为了解决这些挑战,我们提出了一种新颖的框架MCTS-SQL,该框架使用蒙特卡洛树搜索通过多步细化来指导SQL生成。由于轻量级模型在单次预测方面的性能较弱,我们通过多次试验和反馈来生成更好的结果。然而,直接应用基于MCTS的方法不可避免地会导致大量的时间和计算开销。为了解决这个问题,我们提出了一种token级别的prefix-cache机制,该机制在迭代期间存储先验信息,从而有效地提高了执行速度。在SPIDER和BIRD基准上的实验结果证明了我们方法的有效性。使用小型开源Qwen2.5-Coder-1.5B,我们的方法优于ChatGPT-3.5。当利用更强大的模型Gemini 2.5来探索性能上限时,我们取得了与SOTA竞争的结果。我们的发现表明,即使是小型模型也可以通过正确的策略有效地部署在实际的Text-to-SQL系统中。
🔬 方法详解
问题定义:Text-to-SQL任务旨在将自然语言问题转化为SQL查询语句。现有方法通常依赖于大型语言模型,计算成本高昂,难以在资源受限的环境中部署。轻量级模型虽然成本较低,但在处理复杂指令、模式链接和保证语法正确性方面存在困难。
核心思路:论文的核心思路是利用蒙特卡洛树搜索(MCTS)来指导SQL语句的生成过程。MCTS通过多次模拟和评估,逐步优化SQL语句,从而克服了轻量级模型单次生成能力不足的问题。这种方法允许模型通过试错和反馈来逐步完善SQL语句,提高生成质量。
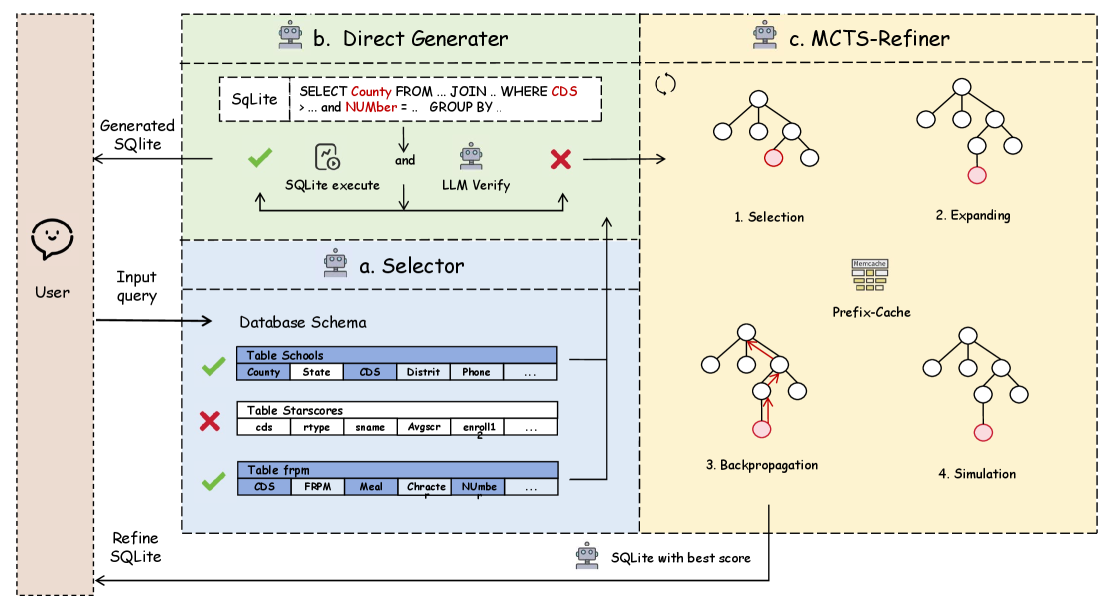
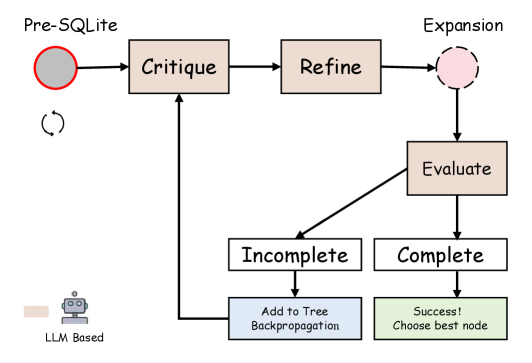
技术框架:MCTS-SQL框架主要包含以下几个阶段:1) 初始化:根据自然语言问题和数据库模式,生成初始的SQL语句候选集。2) 扩展:利用轻量级LLM,对候选SQL语句进行扩展,生成新的候选语句。3) 模拟:执行候选SQL语句,并根据执行结果(例如,是否成功执行,返回结果的质量等)进行评估。4) 反向传播:根据评估结果,更新MCTS树中节点的价值,从而指导后续的搜索过程。5) 选择:根据节点的价值,选择最优的SQL语句作为最终结果。
关键创新:该论文的关键创新在于将蒙特卡洛树搜索与轻量级LLM相结合,用于Text-to-SQL任务。此外,论文还提出了一种token级别的prefix-cache机制,用于存储迭代过程中的先验信息,从而加速MCTS的搜索过程。这与传统的Text-to-SQL方法依赖于大型模型或复杂的后处理步骤有本质区别。
关键设计:token级别的prefix-cache机制是关键设计之一,它通过缓存已生成token的概率分布,避免重复计算,从而显著提高了MCTS的效率。此外,奖励函数的设计也至关重要,它需要综合考虑SQL语句的语法正确性、执行成功率以及返回结果的质量。具体的参数设置(例如,MCTS的迭代次数、扩展节点的数量等)需要根据具体的任务和模型进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在SPIDER和BIRD基准测试中,使用Qwen2.5-Coder-1.5B模型,MCTS-SQL框架的性能优于ChatGPT-3.5。当使用更强大的Gemini 2.5模型时,MCTS-SQL的性能可以与SOTA模型相媲美。这表明,即使是小型模型,通过有效的搜索策略,也可以在Text-to-SQL任务上取得良好的性能。
🎯 应用场景
MCTS-SQL框架可应用于各种需要将自然语言转化为SQL查询的场景,例如智能助手、数据库查询工具、数据分析平台等。该方法尤其适用于资源受限的环境,例如移动设备、嵌入式系统等。通过降低对大型模型和昂贵API的依赖,MCTS-SQL可以促进Text-to-SQL技术在更广泛的领域得到应用,并降低开发和部署成本。
📄 摘要(原文)
Text-to-SQL is a fundamental yet challenging task in the NLP area, aiming at translating natural language questions into SQL queries. While recent advances in large language models have greatly improved performance, most existing approaches depend on models with tens of billions of parameters or costly APIs, limiting their applicability in resource-constrained environments. For real world, especially on edge devices, it is crucial for Text-to-SQL to ensure cost-effectiveness. Therefore, enabling the light-weight models for Text-to-SQL is of great practical significance. However, smaller LLMs often struggle with complicated user instruction, redundant schema linking or syntax correctness. To address these challenges, we propose MCTS-SQL, a novel framework that uses Monte Carlo Tree Search to guide SQL generation through multi-step refinement. Since the light-weight models' weak performance of single-shot prediction, we generate better results through several trials with feedback. However, directly applying MCTS-based methods inevitably leads to significant time and computational overhead. Driven by this issue, we propose a token-level prefix-cache mechanism that stores prior information during iterations, effectively improved the execution speed. Experiments results on the SPIDER and BIRD benchmarks demonstrate the effectiveness of our approach. Using a small open-source Qwen2.5-Coder-1.5B, our method outperforms ChatGPT-3.5. When leveraging a more powerful model Gemini 2.5 to explore the performance upper bound, we achieved results competitive with the SOTA. Our findings demonstrate that even small models can be effectively deployed in practical Text-to-SQL systems with the right strategy.