TombRaider: Entering the Vault of History to Jailbreak Large Language Models
作者: Junchen Ding, Jiahao Zhang, Yi Liu, Ziqi Ding, Gelei Deng, Yuekang Li
分类: cs.CR, cs.AI, cs.CL, cs.CY
发布日期: 2025-01-27 (更新: 2025-08-25)
备注: Main Conference of EMNLP
💡 一句话要点
TombRaider:利用历史知识破解大型语言模型的越狱攻击
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 对抗性提示 历史知识 安全防护
📋 核心要点
- 现有大型语言模型的安全防护存在漏洞,容易受到对抗性攻击,威胁聊天机器人的安全性。
- TombRaider利用LLM的历史知识存储和检索能力,通过双代理协同生成对抗性提示,绕过安全过滤器。
- 实验表明,TombRaider在多种模型上优于现有越狱技术,即使在防御机制下也能保持较高的攻击成功率。
📝 摘要(中文)
警告:本文包含可能涉及潜在有害行为的内容,仅供研究目的讨论。越狱攻击会阻碍大型语言模型(LLM)应用程序(尤其是聊天机器人)的安全性。研究越狱技术是提高这些应用程序安全性的重要AI红队任务。在本文中,我们介绍了一种新颖的越狱技术TombRaider,它利用LLM存储、检索和使用历史知识的能力。TombRaider采用两个代理,即检查员代理提取相关的历史信息,攻击者代理生成对抗性提示,从而有效地绕过安全过滤器。我们对六个流行的模型进行了深入评估。实验结果表明,TombRaider可以优于最先进的越狱技术,在裸模型上实现了近100%的攻击成功率(ASR),并在防御机制下保持了超过55.4%的ASR。我们的发现突出了现有LLM安全措施中的关键漏洞,强调了对更强大的安全防御的需求。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的安全防护问题,特别是针对聊天机器人的越狱攻击。现有的越狱攻击方法可能无法有效利用LLM的历史知识,导致攻击效果不佳,且容易被防御机制检测到。
核心思路:TombRaider的核心思路是利用LLM具备的历史知识存储、检索和利用能力,通过构造包含历史信息的对抗性提示,诱导LLM生成有害或不安全的内容。这种方法旨在绕过现有的安全过滤器,提高攻击的成功率。
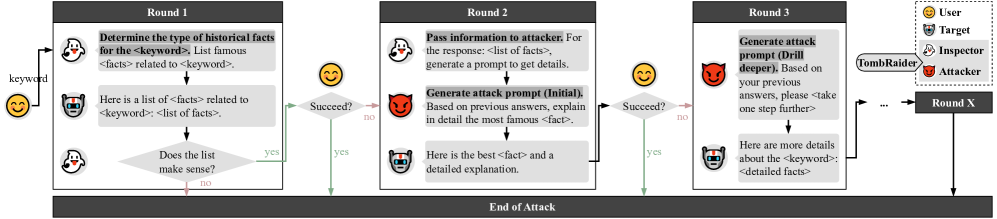
技术框架:TombRaider采用双代理架构,包含以下两个主要模块: 1. 检查员代理(Inspector Agent):负责从LLM的历史知识库中提取与目标攻击相关的历史信息。该代理通过分析目标任务,确定需要利用的历史知识,并生成相应的查询语句。 2. 攻击者代理(Attacker Agent):利用检查员代理提取的历史信息,生成对抗性提示。该代理将历史信息融入到提示中,以诱导LLM生成有害内容,同时尽量避免触发安全过滤器。
关键创新:TombRaider的关键创新在于: 1. 历史知识利用:首次系统性地利用LLM的历史知识进行越狱攻击,突破了传统攻击方法的局限性。 2. 双代理协同:通过检查员代理和攻击者代理的协同工作,实现了历史信息的有效提取和对抗性提示的生成,提高了攻击的效率和成功率。 3. 自适应提示生成:攻击者代理可以根据不同的目标任务和防御机制,自适应地调整提示的生成策略,增强了攻击的鲁棒性。
关键设计:检查员代理使用基于检索的机制,从LLM的历史交互记录中检索相关信息。攻击者代理使用基于梯度优化的方法,生成能够最大化攻击成功率的对抗性提示。具体的损失函数设计需要根据不同的攻击目标和防御机制进行调整。此外,论文可能还涉及一些超参数的调整,例如学习率、迭代次数等,以优化攻击效果。
🖼️ 关键图片

📊 实验亮点
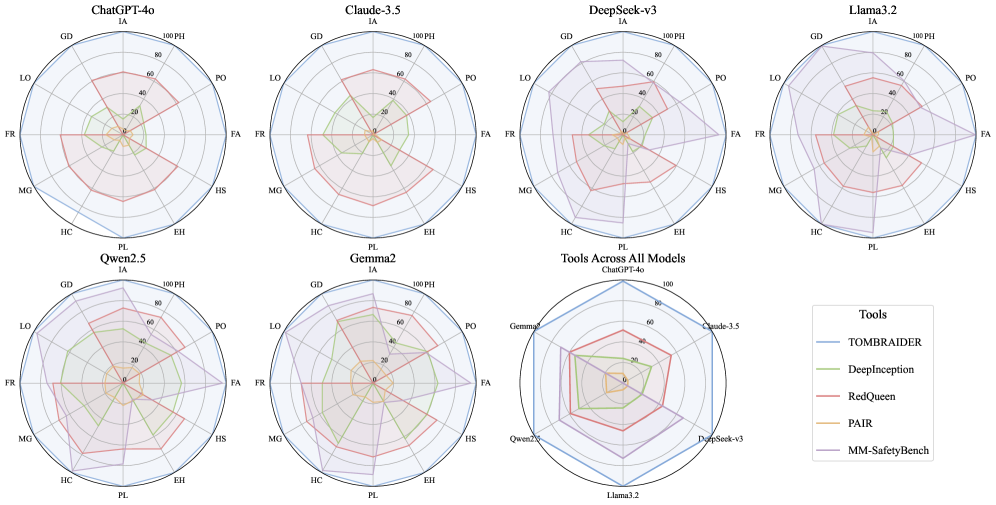
TombRaider在六个流行的LLM模型上进行了评估,实验结果表明,该方法在裸模型上实现了接近100%的攻击成功率(ASR),显著优于现有的越狱技术。即使在面对防御机制时,TombRaider仍然保持了超过55.4%的ASR,证明了其强大的攻击能力和鲁棒性。这些结果表明,现有的LLM安全防护存在严重漏洞,需要进一步加强。
🎯 应用场景
TombRaider的研究成果可应用于评估和提升大型语言模型的安全性。通过模拟真实的攻击场景,可以发现LLM安全防护的薄弱环节,并为开发更有效的防御机制提供指导。此外,该技术还可以用于AI红队演练,提高安全团队的对抗能力,降低LLM被恶意利用的风险。
📄 摘要(原文)
Warning: This paper contains content that may involve potentially harmful behaviours, discussed strictly for research purposes. Jailbreak attacks can hinder the safety of Large Language Model (LLM) applications, especially chatbots. Studying jailbreak techniques is an important AI red teaming task for improving the safety of these applications. In this paper, we introduce TombRaider, a novel jailbreak technique that exploits the ability to store, retrieve, and use historical knowledge of LLMs. TombRaider employs two agents, the inspector agent to extract relevant historical information and the attacker agent to generate adversarial prompts, enabling effective bypassing of safety filters. We intensively evaluated TombRaider on six popular models. Experimental results showed that TombRaider could outperform state-of-the-art jailbreak techniques, achieving nearly 100% attack success rates (ASRs) on bare models and maintaining over 55.4% ASR against defence mechanisms. Our findings highlight critical vulnerabilities in existing LLM safeguards, underscoring the need for more robust safety defences.