The Last Dependency Crusade: Solving Python Dependency Conflicts with LLMs
作者: Antony Bartlett, Cynthia Liem, Annibale Panichella
分类: cs.SE, cs.AI
发布日期: 2025-01-27 (更新: 2025-10-16)
备注: Pre-print - Accepted at the first annual workshop on Agentic Software Engineering (AgenticSE) co-located with ASE'25
💡 一句话要点
提出PLLM:利用LLM和RAG解决Python依赖冲突问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Python依赖管理 大型语言模型 检索增强生成 自动化修复 软件工程
📋 核心要点
- 现有Python依赖管理工具难以应对依赖类型多样、版本爆炸和传递依赖冲突等问题。
- PLLM利用LLM的推理能力,结合RAG框架,通过试错和错误信息解析迭代修复依赖问题。
- 实验表明,PLLM显著优于现有方法,尤其在复杂依赖和特定领域库的项目中表现突出。
📝 摘要(中文)
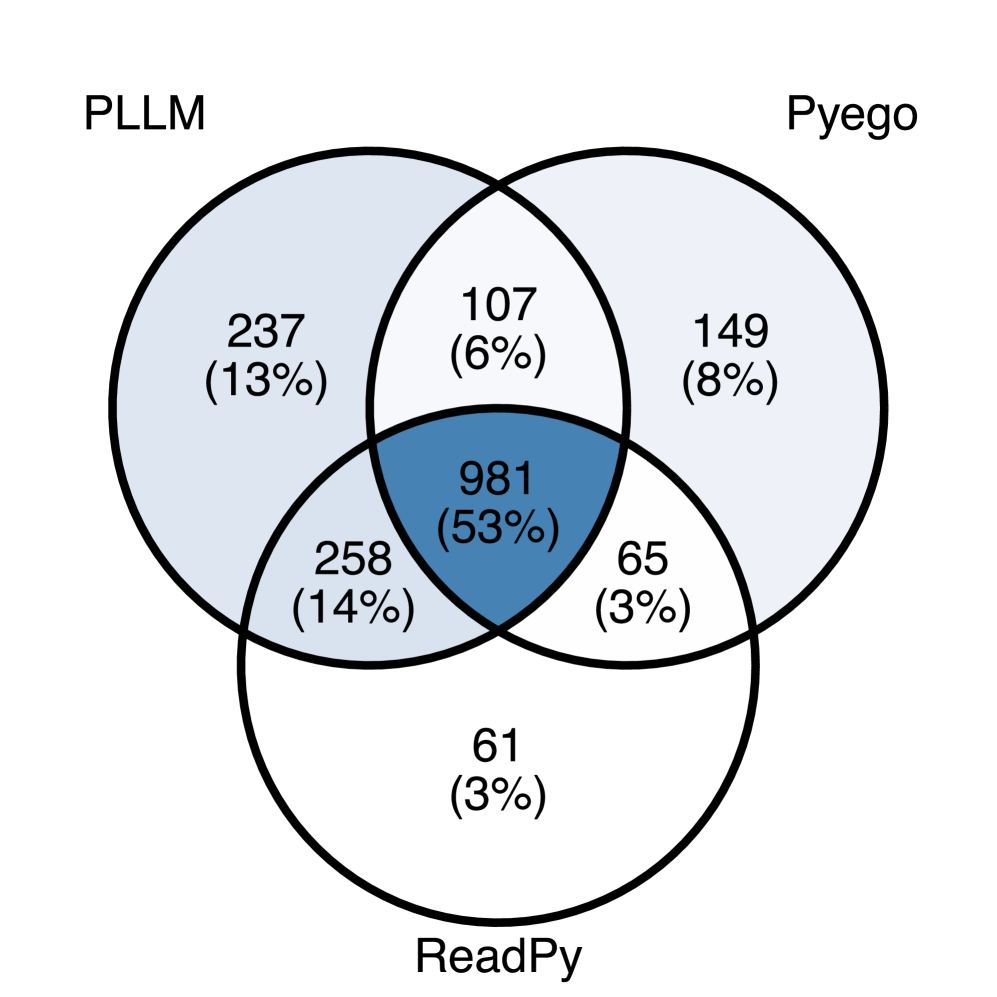
解决Python依赖问题是一个繁琐且容易出错的过程,开发者需要手动尝试兼容的模块版本和解释器配置。现有的自动化解决方案,如基于知识图谱和数据库驱动的方法,由于依赖错误类型多样、模块版本数量庞大以及传递依赖之间的冲突而面临局限性。本文研究了使用大型语言模型(LLM)自动修复Python程序中的依赖问题。我们提出了一种新颖的检索增强生成(RAG)方法PLLM(发音为“plum”),它迭代地推断缺失或不正确的依赖项。PLLM构建一个测试环境,LLM在其中提出模块组合,观察执行反馈,并使用自然语言处理(NLP)解析错误消息来改进其预测。我们在Gistable HG2.9K数据集(一个精选的真实Python程序集合)上评估了PLLM。通过这个基准,我们探索了多种PLLM配置,包括评估了六个开源LLM,无论是否使用RAG。我们的研究结果表明,RAG始终提高修复率,Gemma-2 9B与RAG结合时表现最佳。与两个最先进的基线PyEGo和ReadPyE相比,PLLM实现了显著更高的修复率;比ReadPyE高+15.97%,比PyEGo高+21.58%。进一步的分析表明,PLLM对于具有大量依赖项以及使用专门的数值或机器学习库的项目特别有效。
🔬 方法详解
问题定义:Python依赖管理面临诸多挑战,包括依赖版本冲突、缺失依赖以及不正确的依赖关系。现有的基于知识图谱或数据库的方法难以覆盖所有可能的依赖组合和错误类型,导致开发者需要手动解决依赖问题,效率低下且容易出错。
核心思路:论文的核心思路是利用大型语言模型(LLM)的自然语言理解和生成能力,结合检索增强生成(RAG)框架,将依赖修复问题转化为一个迭代的试错和推理过程。LLM负责提出可能的依赖组合,并根据执行反馈(错误信息)不断优化其预测。
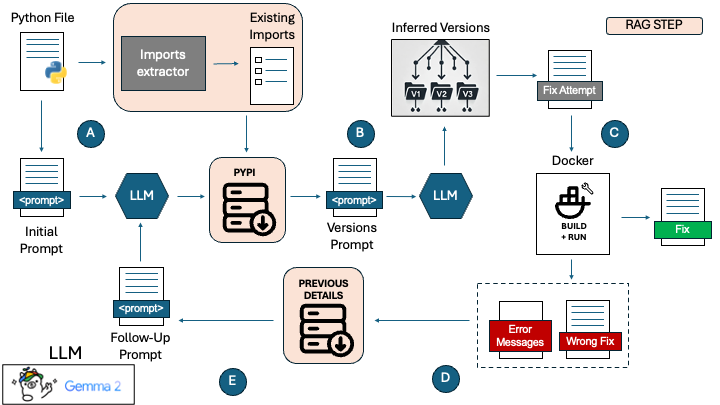
技术框架:PLLM框架包含以下主要阶段:1) 环境构建:为目标Python程序构建一个测试环境。2) 依赖推断:LLM基于程序代码和已安装的依赖项,提出可能的依赖组合。3) 执行与反馈:在测试环境中执行程序,并捕获错误信息。4) 错误解析:使用NLP技术解析错误信息,提取关键的依赖问题。5) 迭代优化:LLM根据错误信息调整依赖组合,重复步骤2-5,直到程序成功运行或达到最大迭代次数。
关键创新:PLLM的关键创新在于将LLM引入到Python依赖修复过程中,并结合RAG框架,实现了自动化的依赖问题诊断和修复。与传统的基于规则或数据库的方法相比,PLLM能够更好地处理复杂的依赖关系和未知的错误类型。此外,PLLM通过迭代试错和错误信息解析,不断优化依赖组合,提高了修复的准确性和效率。
关键设计:PLLM的关键设计包括:1) 使用自然语言处理技术解析Python错误信息,提取关键的依赖问题。2) 设计合适的提示工程(Prompt Engineering),引导LLM生成有效的依赖组合。3) 选择合适的LLM模型,并进行微调以提高其在依赖修复任务上的性能。4) 设置最大迭代次数,防止无限循环。5) 采用RAG框架,从外部知识库检索相关的依赖信息,增强LLM的推理能力。
🖼️ 关键图片
📊 实验亮点
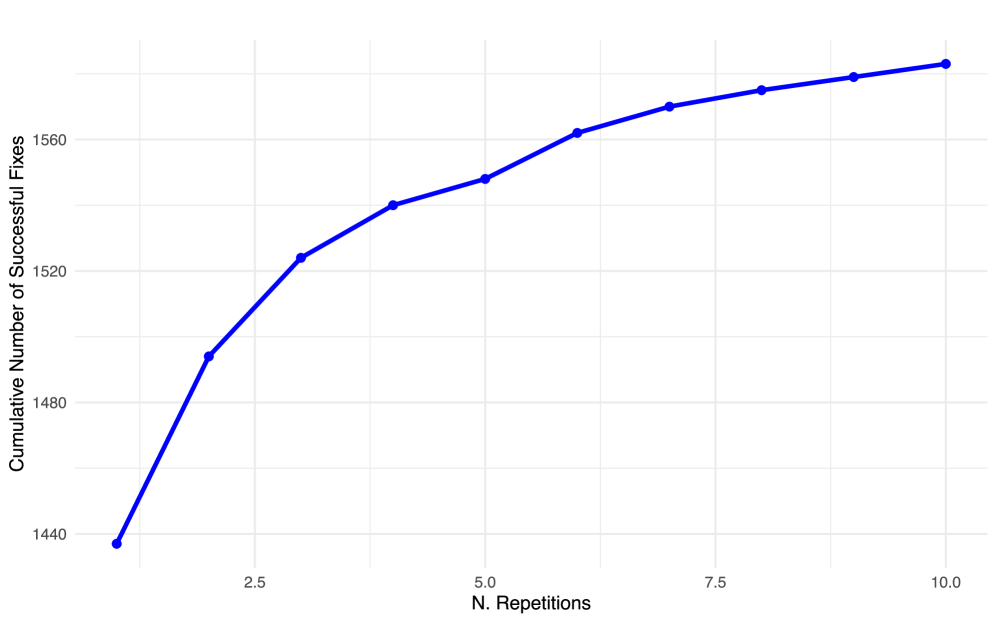
实验结果表明,PLLM在Gistable HG2.9K数据集上显著优于两个最先进的基线PyEGo和ReadPyE。PLLM的最佳配置(Gemma-2 9B + RAG)比ReadPyE的修复率高+15.97%,比PyEGo高+21.58%。此外,分析表明,PLLM对于具有大量依赖项以及使用专门的数值或机器学习库的项目特别有效,表明其在复杂依赖场景下的优势。
🎯 应用场景
PLLM可应用于自动化软件开发流程,减少开发者在依赖管理上花费的时间和精力。它可以集成到持续集成/持续部署(CI/CD)管道中,自动修复依赖问题,提高软件构建的成功率和效率。此外,PLLM还可以用于教育领域,帮助初学者更好地理解和管理Python依赖。
📄 摘要(原文)
Resolving Python dependency issues remains a tedious and error-prone process, forcing developers to manually trial compatible module versions and interpreter configurations. Existing automated solutions, such as knowledge-graph-based and database-driven methods, face limitations due to the variety of dependency error types, large sets of possible module versions, and conflicts among transitive dependencies. This paper investigates the use of Large Language Models (LLMs) to automatically repair dependency issues in Python programs. We propose PLLM (pronounced "plum"), a novel retrieval-augmented generation (RAG) approach that iteratively infers missing or incorrect dependencies. PLLM builds a test environment where the LLM proposes module combinations, observes execution feedback, and refines its predictions using natural language processing (NLP) to parse error messages. We evaluate PLLM on the Gistable HG2.9K dataset, a curated collection of real-world Python programs. Using this benchmark, we explore multiple PLLM configurations, including six open-source LLMs evaluated both with and without RAG. Our findings show that RAG consistently improves fix rates, with the best performance achieved by Gemma-2 9B when combined with RAG. Compared to two state-of-the-art baselines, PyEGo and ReadPyE, PLLM achieves significantly higher fix rates; +15.97\% more than ReadPyE and +21.58\% more than PyEGo. Further analysis shows that PLLM is especially effective for projects with numerous dependencies and those using specialized numerical or machine-learning libraries.