FDLLM: A Dedicated Detector for Black-Box LLMs Fingerprinting
作者: Zhiyuan Fu, Junfan Chen, Lan Zhang, Ting Yang, Jun Niu, Hongyu Sun, Ruidong Li, Peng Liu, Jice Wang, Fannv He, Qiuling Yue, Yuqing Zhang
分类: cs.CR, cs.AI
发布日期: 2025-01-27 (更新: 2026-01-19)
💡 一句话要点
提出FDLLM,一种基于LoRA微调的黑盒大语言模型指纹识别方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 指纹识别 低秩适应 对抗攻击 模型溯源
📋 核心要点
- 现有黑盒LLM指纹识别方法缺乏专用数据集,且难以抵抗对抗攻击,影响了实际应用。
- FDLLM利用LoRA微调,提取LLM深层特征,实现高效且鲁棒的指纹识别。
- FDLLM在FD-Dataset上超越现有方法,Macro F1提升22.1%,且对对抗攻击具有更强的抵抗性。
📝 摘要(中文)
大型语言模型(LLM)正迅速改变数字内容创作的格局。然而,对许多LLM的黑盒应用程序编程接口(API)访问给问责制、治理和安全性带来了重大挑战。LLM指纹识别旨在通过分析生成文本的统计和文体特征来识别源模型,它提供了一种潜在的解决方案。当前的研究进展受到缺乏专用数据集以及需要高效、实用的方法(能够抵抗对抗性操纵)的阻碍。为了应对这些挑战,我们引入了FD-Dataset,这是一个全面的双语指纹识别基准,包含来自20个著名的专有和开源LLM的90,000个文本样本。此外,我们提出了一种新的指纹识别方法FDLLM,该方法利用参数高效的低秩适应(LoRA)来微调基础模型。这种方法使LoRA能够提取表征每个源LLM的深层、持久特征。通过我们的分析,我们发现LoRA适应促进了来自同一LLM的输出在表示空间中的聚合,同时增强了不同LLM之间的分离。这种机制解释了为什么LoRA对于LLM指纹识别特别有效。在FD-Dataset上的大量经验评估表明了FDLLM的优越性,其Macro F1得分比最强的基线高22.1%。FDLLM还表现出对新发布模型的强大泛化能力,在未见过的模型上实现了95%的平均准确率。值得注意的是,FDLLM在各种对抗性攻击(包括润色、翻译和同义词替换)下始终保持稳健。实验结果表明,FDLLM将平均攻击成功率从49.2%(LM-D)降低到23.9%。
🔬 方法详解
问题定义:论文旨在解决黑盒LLM的指纹识别问题,即在无法访问模型内部参数的情况下,仅通过分析其生成的文本来确定其来源。现有方法通常依赖于浅层统计特征或需要大量计算资源,并且容易受到对抗攻击的影响,例如通过文本润色、翻译或同义词替换来改变LLM的输出风格,从而导致指纹识别失败。
核心思路:论文的核心思路是利用参数高效的LoRA(Low-Rank Adaptation)技术来微调一个预训练的基础模型,使其能够学习到每个LLM独特的深层特征表示。LoRA通过在预训练模型的权重矩阵中引入低秩矩阵来实现参数高效的微调,从而避免了对整个模型进行微调,降低了计算成本。通过学习到的低秩矩阵,模型能够捕捉到每个LLM的细微风格差异,从而实现准确的指纹识别。
技术框架:FDLLM的整体框架包括以下几个主要步骤:1) 数据收集:构建包含多个LLM生成文本的指纹识别数据集(FD-Dataset)。2) 模型微调:使用LoRA技术对预训练的基础模型进行微调,针对每个LLM学习一个低秩矩阵。3) 特征提取:使用微调后的模型提取输入文本的特征表示。4) 分类:使用分类器(例如,线性分类器或支持向量机)根据提取的特征表示对LLM进行分类。
关键创新:FDLLM的关键创新在于利用LoRA进行参数高效的LLM指纹识别。与传统的全参数微调相比,LoRA显著减少了需要训练的参数数量,降低了计算成本,并且能够更好地泛化到新的LLM。此外,论文还发现LoRA能够促进同一LLM的输出在表示空间中的聚集,并增强不同LLM之间的分离,从而提高了指纹识别的准确性。
关键设计:在LoRA微调过程中,论文采用了以下关键设计:1) 选择合适的预训练基础模型:例如,BERT或RoBERTa。2) 设置合适的LoRA秩(rank):秩的大小决定了LoRA的参数数量和模型的表达能力。3) 使用交叉熵损失函数来训练模型,目标是最小化预测的LLM类别与真实类别之间的差异。4) 采用数据增强技术来提高模型的鲁棒性,例如,通过随机替换同义词或进行轻微的文本润色。
🖼️ 关键图片

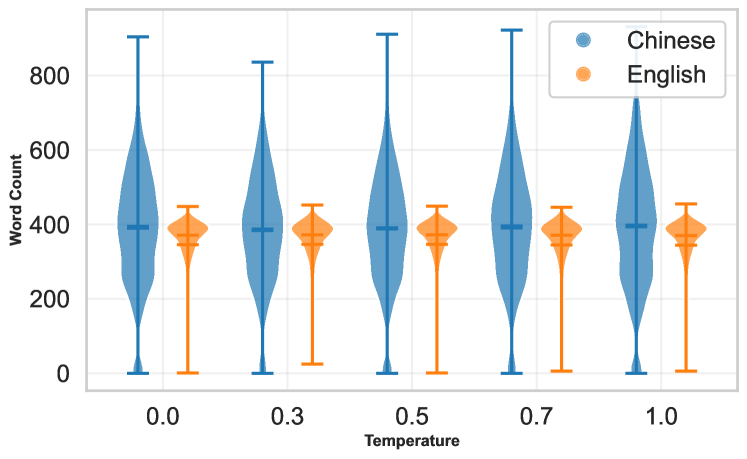
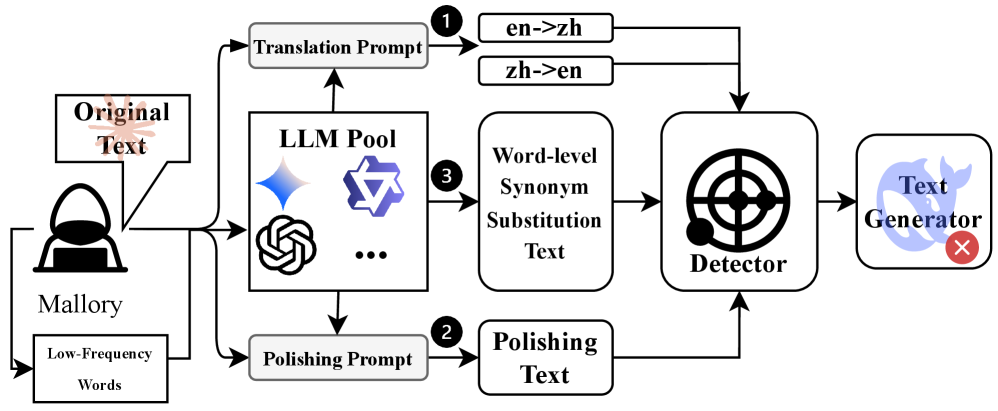
📊 实验亮点
FDLLM在FD-Dataset上取得了显著的性能提升,Macro F1得分比最强基线高22.1%。在未见过的模型上实现了95%的平均准确率,展现了良好的泛化能力。此外,FDLLM在各种对抗性攻击下表现出强大的鲁棒性,将平均攻击成功率从49.2%(LM-D)降低到23.9%。
🎯 应用场景
FDLLM可应用于检测虚假信息来源、追踪恶意内容生成者,以及验证AI生成内容的真实性。在内容安全、版权保护和模型溯源等领域具有重要应用价值。未来可用于构建更安全的AI生态系统,促进LLM技术的健康发展。
📄 摘要(原文)
Large Language Models (LLMs) are rapidly transforming the landscape of digital content creation. However, the prevalent black-box Application Programming Interface (API) access to many LLMs introduces significant challenges in accountability, governance, and security. LLM fingerprinting, which aims to identify the source model by analyzing statistical and stylistic features of generated text, offers a potential solution. Current progress in this area is hindered by a lack of dedicated datasets and the need for efficient, practical methods that are robust against adversarial manipulations. To address these challenges, we introduce FD-Dataset, a comprehensive bilingual fingerprinting benchmark comprising 90,000 text samples from 20 famous proprietary and open-source LLMs. Furthermore, we present FDLLM, a novel fingerprinting method that leverages parameter-efficient Low-Rank Adaptation (LoRA) to fine-tune a foundation model. This approach enables LoRA to extract deep, persistent features that characterize each source LLM. Through our analysis, we find that LoRA adaptation promotes the aggregation of outputs from the same LLM in representation space while enhancing the separation between different LLMs. This mechanism explains why LoRA proves particularly effective for LLM fingerprinting. Extensive empirical evaluations on FD-Dataset demonstrate FDLLM's superiority, achieving a Macro F1 score 22.1% higher than the strongest baseline. FDLLM also exhibits strong generalization to newly released models, achieving an average accuracy of 95% on unseen models. Notably, FDLLM remains consistently robust under various adversarial attacks, including polishing, translation, and synonym substitution. Experimental results show that FDLLM reduces the average attack success rate from 49.2% (LM-D) to 23.9%.