Contextual Knowledge Sharing in Multi-Agent Reinforcement Learning with Decentralized Communication and Coordination
作者: Hung Du, Srikanth Thudumu, Hy Nguyen, Rajesh Vasa, Kon Mouzakis
分类: cs.MA, cs.AI
发布日期: 2025-01-26
💡 一句话要点
提出一种融合通信与协作的去中心化多智能体强化学习框架,解决动态环境下的复杂任务。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 去中心化控制 知识共享 目标感知 时间感知
📋 核心要点
- 现有MARL方法通常假设智能体具有共同目标并依赖集中控制,这在智能体具有个体目标和有限可观测性的现实场景中存在局限性。
- 该论文提出一种Dec-MARL框架,通过点对点通信和协作,使智能体能够共享上下文相关的知识,并根据自身目标和时间背景进行推理。
- 实验结果表明,在动态障碍物环境中,该方法通过结合目标感知和时间感知的知识共享,显著提高了多智能体系统的整体性能。
📝 摘要(中文)
本文提出了一种新颖的去中心化多智能体强化学习(Dec-MARL)框架,该框架集成了点对点通信和协作机制,并将目标感知和时间感知融入到智能体的知识共享过程中。该框架使智能体能够:(i)共享上下文相关的知识以帮助其他智能体;(ii)基于从多个智能体获取的信息进行推理,同时考虑自身目标和先前知识的时间背景。通过在具有动态障碍物的环境中进行多个复杂的多智能体任务评估,结果表明,结合目标感知和时间感知的知识共享显著提高了整体性能。
🔬 方法详解
问题定义:现有的去中心化多智能体强化学习方法,要么侧重于智能体之间的通信,要么侧重于智能体之间的协调,缺乏一个能够同时有效利用通信和协调的集成方法。此外,现有方法在知识共享时,往往忽略了智能体的个体目标以及知识的时效性,导致智能体无法有效地利用其他智能体的信息,从而影响整体性能。
核心思路:本文的核心思路是设计一个Dec-MARL框架,该框架允许智能体之间进行点对点通信,并结合目标感知和时间感知来指导知识共享。通过目标感知,智能体可以判断哪些信息对其他智能体完成其目标有帮助;通过时间感知,智能体可以评估先前知识的有效性,从而避免使用过时的信息。
技术框架:该框架包含以下主要模块:1) 知识编码模块:将智能体的观测、动作和奖励等信息编码成知识表示;2) 上下文感知模块:根据智能体的目标和时间信息,确定知识的上下文相关性;3) 知识共享模块:智能体之间通过点对点通信共享上下文相关的知识;4) 知识融合模块:智能体将接收到的知识与自身知识进行融合,用于指导策略学习。整个流程是循环迭代的,智能体不断地收集信息、共享知识、融合知识和更新策略。
关键创新:该论文的关键创新在于将目标感知和时间感知融入到Dec-MARL的知识共享过程中。通过目标感知,智能体可以更有选择性地共享知识,避免信息过载;通过时间感知,智能体可以过滤掉过时的信息,提高知识利用效率。这种上下文感知的知识共享机制,使得智能体能够更有效地利用其他智能体的信息,从而提高整体性能。
关键设计:目标感知模块可能使用注意力机制来评估不同知识对其他智能体目标的重要性。时间感知模块可能使用衰减函数来降低先前知识的权重,衰减速度可以根据环境动态性进行调整。损失函数可能包含策略梯度损失、通信损失和协作损失,其中通信损失鼓励智能体进行有效的通信,协作损失鼓励智能体之间进行有效的协作。具体的网络结构和参数设置未知,需要参考论文细节。
🖼️ 关键图片

📊 实验亮点
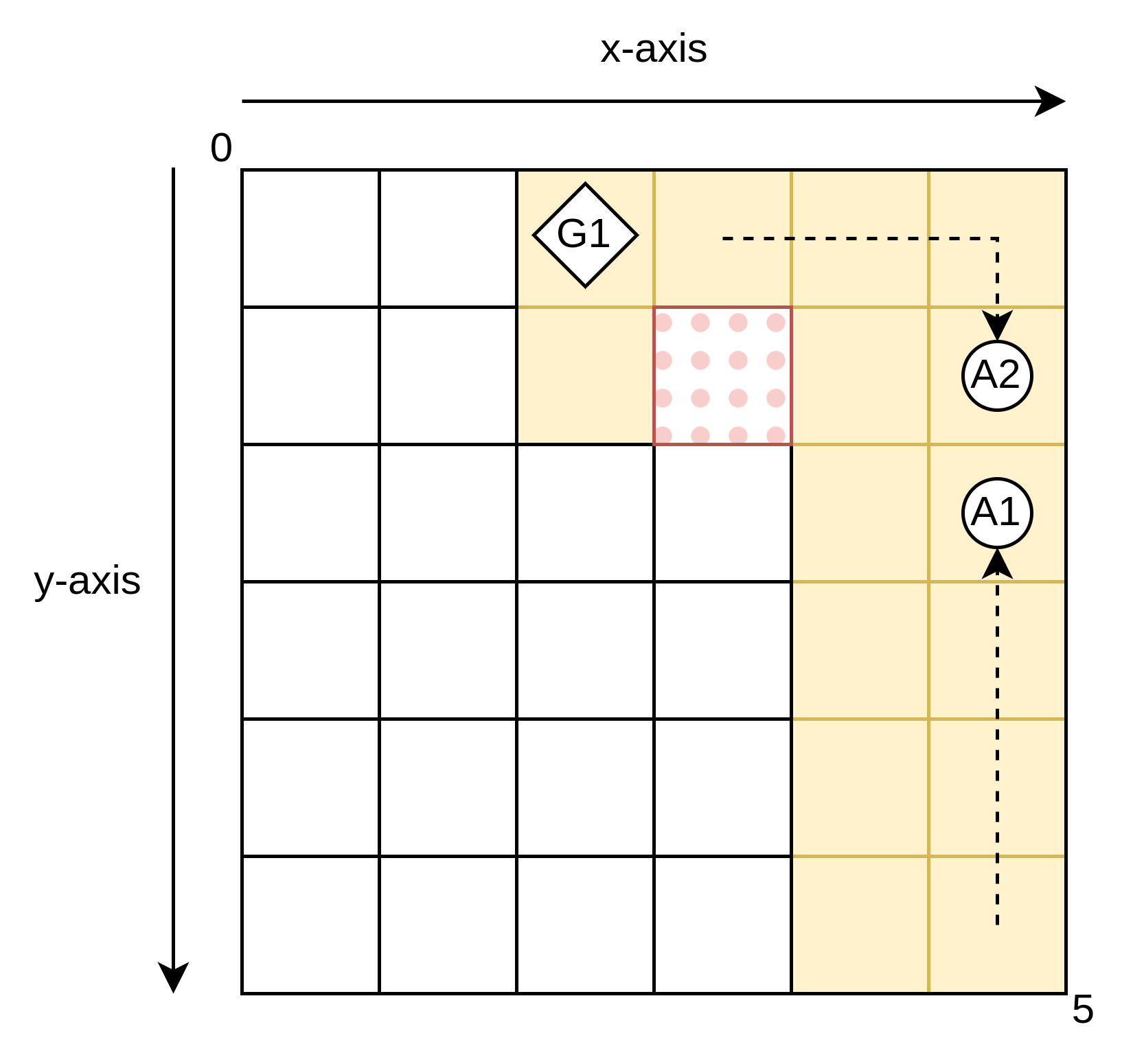
该论文通过在具有动态障碍物的多智能体环境中进行实验,验证了所提出框架的有效性。实验结果表明,与没有目标感知和时间感知的基线方法相比,该框架能够显著提高多智能体系统的整体性能。具体的性能提升幅度未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于机器人协同、自动驾驶、智能交通、分布式传感器网络等领域。通过智能体之间的有效通信和协作,可以提高系统的整体性能和鲁棒性,从而更好地应对复杂和动态的环境。例如,在自动驾驶中,车辆可以共享路况信息和驾驶策略,从而提高交通效率和安全性。
📄 摘要(原文)
Decentralized Multi-Agent Reinforcement Learning (Dec-MARL) has emerged as a pivotal approach for addressing complex tasks in dynamic environments. Existing Multi-Agent Reinforcement Learning (MARL) methodologies typically assume a shared objective among agents and rely on centralized control. However, many real-world scenarios feature agents with individual goals and limited observability of other agents, complicating coordination and hindering adaptability. Existing Dec-MARL strategies prioritize either communication or coordination, lacking an integrated approach that leverages both. This paper presents a novel Dec-MARL framework that integrates peer-to-peer communication and coordination, incorporating goal-awareness and time-awareness into the agents' knowledge-sharing processes. Our framework equips agents with the ability to (i) share contextually relevant knowledge to assist other agents, and (ii) reason based on information acquired from multiple agents, while considering their own goals and the temporal context of prior knowledge. We evaluate our approach through several complex multi-agent tasks in environments with dynamically appearing obstacles. Our work demonstrates that incorporating goal-aware and time-aware knowledge sharing significantly enhances overall performance.