Querying Databases with Function Calling
作者: Connor Shorten, Charles Pierse, Thomas Benjamin Smith, Karel D'Oosterlinck, Tuana Celik, Erika Cardenas, Leonie Monigatti, Mohd Shukri Hasan, Edward Schmuhl, Daniel Williams, Aravind Kesiraju, Bob van Luijt
分类: cs.DB, cs.AI, cs.IR
发布日期: 2025-01-23
备注: Preprint. 23 pages, 7 figures
💡 一句话要点
提出基于函数调用的数据库查询工具,提升LLM访问私有和实时数据的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数据库查询 函数调用 工具集成 数据访问
📋 核心要点
- 现有方法难以有效利用LLM进行数据库查询,尤其是在函数调用作为工具的应用方面,缺乏统一的查询和转换方法。
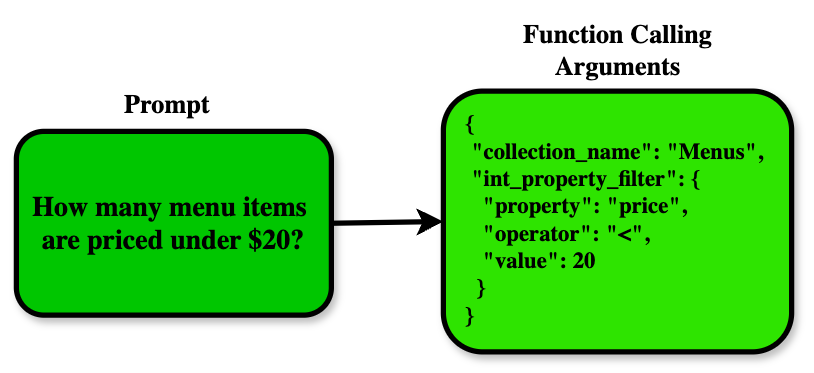
- 提出一种基于函数调用的数据库查询工具定义,统一数据访问与搜索、过滤及结果转换,利用聚合和groupby运算符。
- 实验结果表明,Claude 3.5 Sonnet、GPT-4o mini和GPT-4o在精确匹配方面表现出色,验证了该方法在数据库查询中的有效性。
📝 摘要(中文)
大型语言模型(LLM)的能力正在迅速提升,这主要归功于它们与外部工具的集成。数据库查询是其中最有效的集成方式之一,使LLM能够访问私有或持续更新的数据。虽然函数调用是LLM与外部工具交互的最常用方法,但将其作为数据库查询工具的应用尚未得到充分探索。我们提出了一种数据库查询的工具定义,它统一了数据访问与搜索查询、过滤器或两者的组合,以及使用聚合和groupby运算符转换结果。为了评估其有效性,我们对跨越5个模型系列的8个LLM进行了研究。我们提出了一个新颖的pipeline,该pipeline改编了Gorilla LLM框架来创建合成数据库模式和查询。我们主要使用预测查询API与ground truth查询API的精确匹配来评估模型。在测试的模型中,Claude 3.5 Sonnet实现了最高的性能,精确匹配得分为74.3%,其次是GPT-4o mini,得分为73.7%,GPT-4o得分为71.8%。我们进一步按使用的API组件和跨合成用例细分了这些结果。我们发现LLM在对布尔属性使用运算符方面非常有效,但在文本属性过滤器方面表现不佳。在用例中,我们发现GPT-4o等性能较高的模型具有强大的结果,但性能较低的模型在用例中的性能差异很大。此外,我们还进行了消融研究,探讨了并行工具调用、将理由作为工具调用的参数、每个数据库集合使用单独的工具以及使用结构化输出进行工具调用的影响。我们的研究结果证明了使用函数调用使LLM能够查询数据库的有效性。我们已在github.com/weaviate/gorilla上开源了我们的实验代码和结果。
🔬 方法详解
问题定义:现有方法在利用大型语言模型(LLM)进行数据库查询时,特别是通过函数调用作为工具时,存在效率和灵活性不足的问题。缺乏一种统一的框架,能够同时处理数据访问、搜索查询、过滤以及结果转换等多种操作。此外,现有方法在处理不同数据类型(如布尔属性和文本属性)的过滤时,性能存在显著差异。
核心思路:该论文的核心思路是设计一种通用的数据库查询工具定义,并将其集成到LLM的函数调用机制中。通过统一数据访问、搜索、过滤和结果转换操作,使得LLM能够更有效地利用数据库中的信息。这种设计旨在提高LLM在处理复杂查询时的准确性和效率。
技术框架:该研究采用了一个包含以下主要模块的pipeline:1) 使用Gorilla LLM框架生成合成数据库模式和查询;2) 定义数据库查询的函数调用工具,包括搜索查询、过滤器、聚合和groupby运算符;3) 使用该工具对多个LLM进行评估,包括Claude 3.5 Sonnet、GPT-4o mini和GPT-4o等;4) 通过精确匹配预测查询API和ground truth查询API来评估模型性能;5) 进行消融研究,分析不同因素(如并行工具调用、理由参数、独立工具和结构化输出)对性能的影响。
关键创新:该论文的关键创新在于提出了一种统一的数据库查询工具定义,并将其与LLM的函数调用机制相结合。这种方法不仅简化了LLM与数据库的交互,还提高了查询的灵活性和效率。此外,该研究还提出了一个新颖的pipeline,用于生成合成数据库模式和查询,为评估LLM在数据库查询任务中的性能提供了有效的工具。
关键设计:在工具定义方面,该研究统一了数据访问与搜索查询、过滤器以及结果转换操作,并支持聚合和groupby运算符。在实验评估方面,该研究采用了精确匹配作为评估指标,并对不同LLM在不同用例和数据类型上的性能进行了详细分析。此外,消融研究还探讨了不同因素对性能的影响,为进一步优化LLM在数据库查询任务中的应用提供了指导。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Claude 3.5 Sonnet在精确匹配方面表现最佳,得分为74.3%,其次是GPT-4o mini(73.7%)和GPT-4o(71.8%)。研究还发现,LLM在处理布尔属性的运算符时表现出色,但在处理文本属性过滤器时存在困难。消融研究揭示了并行工具调用、理由参数等因素对性能的影响。
🎯 应用场景
该研究成果可应用于各种需要LLM访问和查询数据库的场景,例如智能客服、数据分析、报告生成等。通过函数调用,LLM可以更方便地获取私有或实时更新的数据,从而提供更准确、更个性化的服务。该研究还有助于推动LLM在企业级应用中的普及,提高数据驱动决策的效率。
📄 摘要(原文)
The capabilities of Large Language Models (LLMs) are rapidly accelerating largely thanks to their integration with external tools. Querying databases is among the most effective of these integrations, enabling LLMs to access private or continually updating data. While Function Calling is the most common method for interfacing external tools to LLMs, its application to database querying as a tool has been underexplored. We propose a tool definition for database querying that unifies accessing data with search queries, filters, or a combination both, as well as transforming results with aggregation and groupby operators. To evaluate its effectiveness, we conduct a study with 8 LLMs spanning 5 model families. We present a novel pipeline adapting the Gorilla LLM framework to create synthetic database schemas and queries. We primarily evaluate the models with the Exact Match of predicted and ground truth query APIs. Among the models tested, Claude 3.5 Sonnet achieves the highest performance with an Exact Match score of 74.3%, followed by GPT-4o mini at 73.7%, and GPT-4o at 71.8%. We further breakdown these results per API component utilized and across synthetic use cases. We find that LLMs are highly effective at utilizing operators on boolean properties, but struggle with text property filters. Across use cases we find robust results with the higher performing models such as GPT-4o, but significant performance variance across use cases from lower performing models. We additionally conduct ablation studies exploring the impact of parallel tool calling, adding a rationale as an argument of the tool call, using a separate tool per database collection, and tool calling with structured outputs. Our findings demonstrate the effectiveness of enabling LLMs to query databases with Function Calling. We have open-sourced our experimental code and results at github.com/weaviate/gorilla.